HDFS读写策略
数据的读取过程:
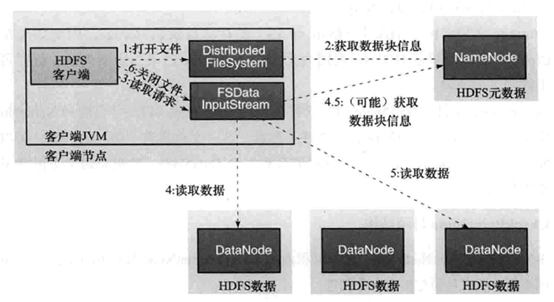
数据读取:
- 客户端调用FileSystem 实例的open 方法,获得这个文件对应的输入流InputStream。
- 通过RPC 远程调用NameNode ,获得NameNode 中此文件对应的数据块保存位置,包括这个文件的副本的保存位置( 主要是各DataNode的地址) 。
- 获得输入流之后,客户端调用read 方法读取数据。选择最近的DataNode 建立连接并读取数据。
- 如果客户端和其中一个DataNode 位于同一机器(比如MapReduce 过程中的mapper 和reducer),那么就会直接从本地读取数据。
- 到达数据块末端,关闭与这个DataNode 的连接,然后重新查找下一个数据块。
- 不断执行第2 - 5 步直到数据全部读完。
- 客户端调用close ,关闭输入流DF S InputStream。
数据的写入过程:
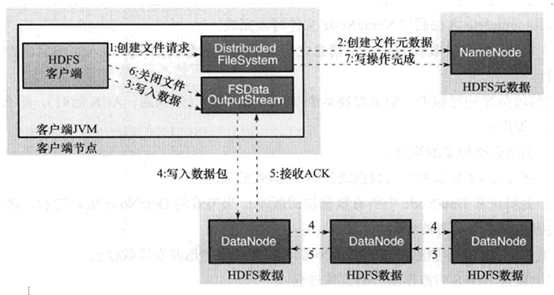
数据的写入:
- 客户端调用FileSystem实例的create方法,创建文件。NameNode通过一些检查,比如文件是否存在,客户端是否拥有创建权限等;通过检查之后,在NameNode添加文件信息。注意,因为此时文件没有数据,所以NameNode上也没有文件数据块的信息。
- 创建结束之后,HDFS会返回一个输出流DFSDataOutputStream给客户端。
- 客户端调用输出流DFSDataOutputStream的write方法向HDFS中对应的文件写入数据。
- 数据首先会被分包,这些分包会写人一个输出流的内部队列Data队列中,接收完数据分包,输出流DFSDataOutputStream会向NameNode申请保存文件和副本数据块的若干个DataNode,这若干个DataNode会形成一个数据传输管道。DFSDataOutputStream将数据传输给距离上最短的DataNode,这个DataNode接收到数据包之后会传给下一个DataNode。数据在各DataNode之间通过管道流动,而不是全部由输出流分发,以减少传输开销。
- 因为各DataNode位于不同机器上,数据需要通过网络发送,所以,为了保证所有DataNode的数据都是准确的,接收到数据的DataNode要向发送者发送确认包(ACK Packet ) 。对于某个数据块,只有当DFSDataOutputStream收到了所有DataNode的正确ACK,才能确认传输结束。DFSDataOutputStream内部专门维护了一个等待ACK 队列,这一队列保存已经进入管道传输数据、但是并未被完全确认的数据包。
- 不断执行第3 - 5 步直到数据全部写完,客户端调用close 关闭文件。
- DFSDataInputStream 继续等待直到所有数据写人完毕并被确认,调用complete 方法通知NameNode 文件写入完成。NameNode 接收到complete 消息之后,等待相应数量的副本写入完毕后,告知客户端。
HDFS读写策略的更多相关文章
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- Hadoop HDFS (3) JAVA訪问HDFS之二 文件分布式读写策略
先把上节未完毕的部分补全,再剖析一下HDFS读写文件的内部原理 列举文件 FileSystem(org.apache.hadoop.fs.FileSystem)的listStatus()方法能够列出一 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- Java的MongoDB驱动及读写策略
网上看见一篇博文,详细讲了MongoDB读写策略,将来生产会遇到类似的问题,转来备查. 指定新mongo实例: Mongo m = new Mongo(); Mongo m = new Mongo( ...
- Hadoop -- HDFS 读写数据
一.HDFS读写文件过程 1.读取文件过程 1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件 2) FileSyst ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- HDFS 读写流程-译
HDFS 文件读取流程 Client 端调用 DistributedFileSystem 对象的 open() 方法. 由 DistributedFileSystem 通过 RPC 向 NameNod ...
- HDFS读写流程(转载)
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现.特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性 ...
- Hdfs存储策略
一.磁盘选择策略 1.1.介绍 在HDFS中,所有的数据都是存在各个DataNode上的.而这些DataNode上的数据都是存放于节点机器上的各个目录中的,而一般每个目录我们会对应到1个独立的盘,以便 ...
随机推荐
- Python手动安装 package
https://pypi.python.org/pypi 下载 解压 进入setup.py的目录 python setup.py build python setup.py install
- linux svn 客户端基本使用命令
1.从svn获取项目 svn co URL --username XX --password XX; 2.添加code file svn add codeFile; svn ci -m "c ...
- Exception in thread "main" java.lang.NoClassDefFoundError: antlr/ANTLRException 解决方法
转自:https://blog.csdn.net/gengkunpeng/article/details/6225286?utm_source=blogxgwz4 1. struts2.3.15 hi ...
- mongodb主从复制配置
dbpath=/home/mongodb/data logpath=/home/mongodb/log/mongodb.log logappend=true port= fork=true noaut ...
- 在MongoDB中修改数据类型
引言 本文主要讲解Mongodb的类型转换.包括:string转double, string转int, string转Date. 0. 出现类型不一致的原因 ES导入数据到Mongo后,会出现类型统一 ...
- 【转载】Eclipse:Android开发中如何查看System.out.println的输出内容
Android开发中在代码中通过System.out.println的输出内容不知道去哪了,在console视图中看不到.而通过Log.i之类的要在Logcat视图中看到,夹杂了太多的其它App及底层 ...
- Scipy实现图片去噪
先贴要处理的图片如下 由图片显示可知: # 图片中存在噪声点,白色的圆环# 圆环上的数据和圆环里面和外面不同,所以可以显示出肉眼可识别的图片# 波动# 存在噪声的地方,波动比较大 # 傅里叶变换可以将 ...
- 初步了解XMLHttpRequest对象、http请求的封装
构造器 var xhr = new XMLHttpRequest() 设置超时时间 xhr.ontimeout= 设置超时时间为 1s 设置超时时间(单位:ms) 0为永不超时 HTTP 请求的状态 ...
- IT兄弟连 JavaWeb教程 AJAX中参数传递问题
使用Ajax发送GET请求并需要传递参数时,直接在URL地址后拼接参数,格式如下: xhr.open('get','请求路径?参数名1=参数值1&参数名2=参数值2...',true); 使用 ...
- EF下使用自定义的connectionString避免数据库密码泄露
在使用EF框架时,缺省情况下数据库访问字串是明码存放在app.config或web.config中的,相当于让数据库裸奔. 实际上EF在创建数据实体时,可以指定连接字串,取代在app.config中读 ...