python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests、BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名、图片、名称、演员、上映时间与评分提取出来并保存到文件。
初步分析:所有网页上展示的内容后台都是通过代码来完成的,所以,不管那么多,先看源代码
F12打开chrome的调试工具,从下面的图可以看出,实际上每一个电影选项(排名、分数、名字等)都被包括在dd标签中。
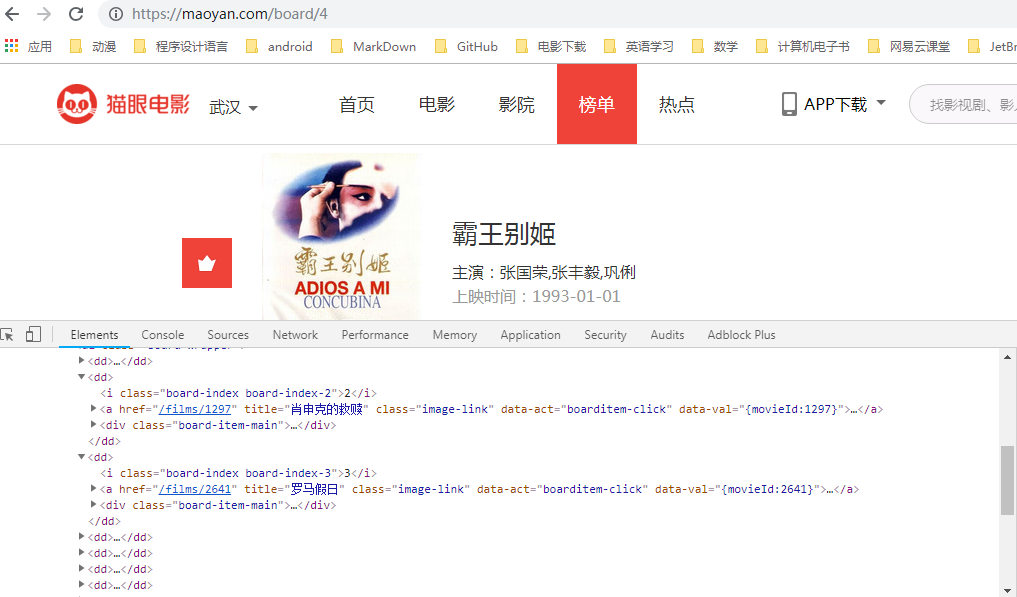
为了能把这些影片信息爬取出来,可以有以下两种思路。
思路一:把电影的每一个要素的列表先提取出来,类似如下:
titile = ['霸王别姬','肖申克的救赎'....],index = [1,2...],
最后从各个列表中选中对应的item拼接成一个个新的列表或字典类型,
类似如下:result = [{'title':'霸王别姬','index':'1'},{'title':'肖申克的救赎','index':'2'.....}
分析:因为要多次进行遍历,思路一的整体逻辑较混乱,容易出错
思路二:把每一个dd标签作为一个整体提取为一个列表,然后对列表的每一项(包含每部影片的各项信息)进行解析提取
分析:很明显,相对第一种思路,第二种思路就更加的清晰明了
下面通过代码来实现思路二的方式:
第一步:获取当前页的网页源代码
def get_current_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except RequestException:
return None
第二步:解析当前网页提取出影片信息
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
dd = soup.select('dd') #css选择器,select是选取所有符合条件的节点,select_one是选取第一个符合条件的节点
for result in dd:
#生成器的方式更省内存
yield {
'index': result.select_one('.board-index').text, #获取影片排名
'title':result.select_one('.image-link')['title'], #获取影片名字
'image':result.select_one('.poster-default')['src'], #获取影片图片链接
'star':result.select_one('.star').text.strip(), #获取演员信息
'realeasetime':result.select_one('.releasetime').text.strip(),#获取上映时间
'score':result.select_one('.integer').text+result.select_one('.fraction').text #获取影片得分
}
第三步:将结果保存到文件
def save_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f: #以追加的形式写入文件
f.write(json.dumps(content, ensure_ascii=False) + '\n')
以上实现了单页影片信息的爬取与存储,下面探索怎么实现翻页后的页面爬取
思路:既然要翻页,那就先点击下一页看看,找找规律,从下图可以看出url后面多了个?offset=10,继续翻页显示为?offset=20,最后一页显示为?offset=90,这就找到规律了,每一个url后面的url都等于页面号x10(页面号从0计数)。
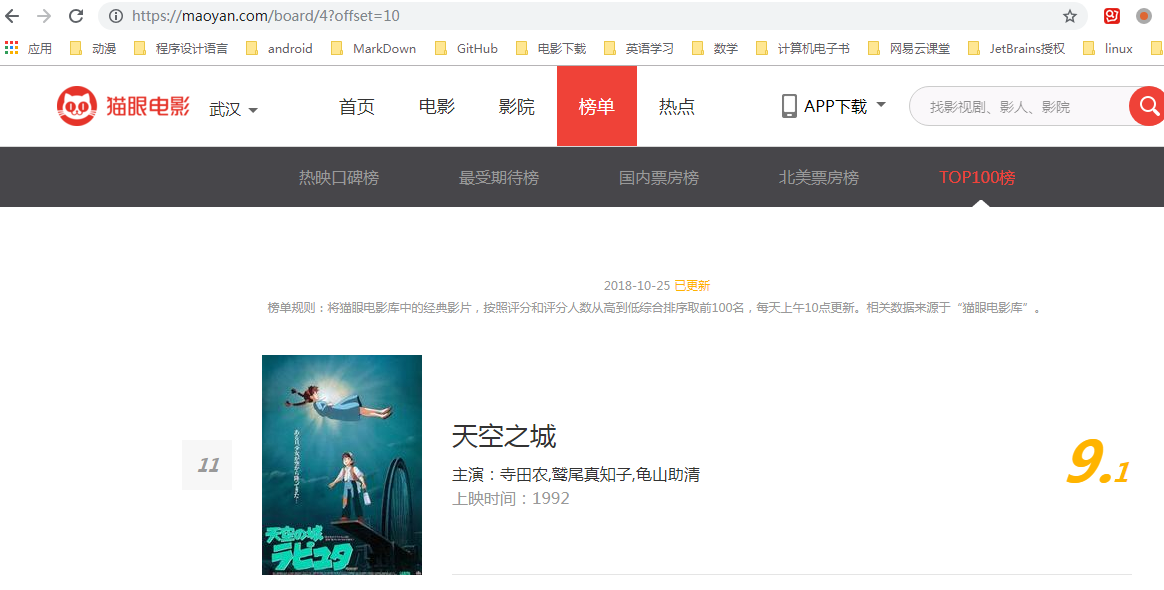
得出规律之后我们开始写主函数
第四步:写主函数
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset * 10)
html = get_current_page(url)
for result in parse_html(html):
print(result)
save_to_file(result)
第五步:写函数入口
if __name__ == '__main__':
depth = 10
for i in range(depth):
main(i)
最后运行的结果:
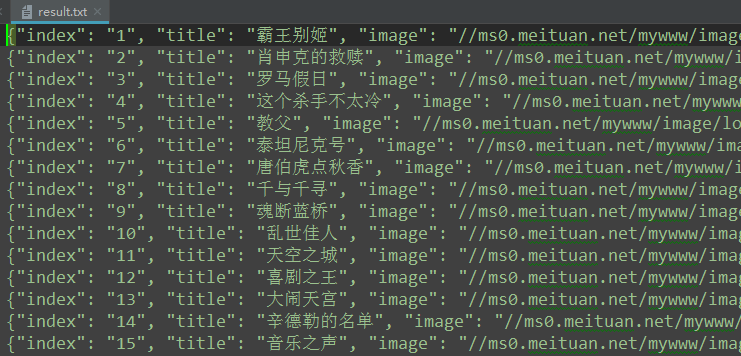
整个的爬取过程就是这样,完整代码查看可以点击这里
python3爬虫爬取猫眼电影TOP100(含详细爬取思路)的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- Python爬虫之requests+正则表达式抓取猫眼电影top100以及瓜子二手网二手车信息(四)
requests+正则表达式抓取猫眼电影top100 一.首先我们先分析下网页结构 可以看到第一页的URL和第二页的URL的区别在于offset的值,第一页为0,第二页为10,以此类推. 二.< ...
- Python Spider 抓取猫眼电影TOP100
""" 抓取猫眼电影TOP100 """ import re import time import requests from bs4 im ...
随机推荐
- 【题解】JSOI2009游戏
真的没想到...果然反应太迟钝,看到题目毫无思路,一点联想都没有. 按照网上博客的说法:一眼棋盘染色二分->二分图->最大匹配->BINGO?果然我还是太弱了…… 我们将棋盘黑白染色 ...
- [Leetcode] Path Sum路径和
Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all ...
- 文件格式转换神器-pandoc
By francis_hao Mar 11,2017 介绍 如果你需要在各种类型的文件中穿梭,那么你需要这把瑞士军刀-pandoc 它可以将各种常见的不常见的文件类型转换成另一种,我感兴趣的是在 ...
- Codeforces Round #350 (Div. 2) A
A. Holidays time limit per test 1 second memory limit per test 256 megabytes input standard input ou ...
- Maven 标准目录结构
Maven 标准目录结构 好的目录结构可以使开发人员更容易理解项目,为以后的维护工作也打下良好的基础.Maven2根据业界公认的最佳目录结构,为开发者提供了缺省的标准目录模板.Maven2的标准目录结 ...
- DIV的变高与变宽
代码: <!DOCTYPE HTML><html><head> <meta charset="utf-8"> <title&g ...
- im4java学习----查看文档和test用例
im4java下载地址:http://sourceforge.net/projects/im4java/files/(谷歌搜索出来的第一个官方地址打不开) 我们需要下载bin和src 这2个压缩包. ...
- IE9,IE10 CSS因Mime类型不匹配而被忽略问题 (转)
写页面的时候在chrome,fireforks等页面上显示正常,但是换成IE9,IE10之后就完全没有样式了,报错信息是CSS 因 Mime 类型不匹配而被忽略,下面与大家分享下这个问题的相关的回答 ...
- jsp小知识点(2)
一:自定义的函数库:在wh.tld中 <description>JSTL 1.1 functions library</description> <display-nam ...
- nginx的常规配置
程序员们,在北上广你还能买房吗? >>> nginx的常规配置 nginx的使用非常简单,只需要配置好我们需要的各种指令,就能跑起来.如果你需要添加模块,还需要添加模块方面的配 ...