Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA
一. HA概述
1. 所谓HA(High Available),即高可用(7*24小时不中断服务)。
2. 实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
3. Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
4 . NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器
二.HDFS-HA工作机制和工作要点
通过双NameNode消除单点故障
1. 元数据管理方式需要改变
内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以做写操作;
两个NameNode都可以读取Edits;
共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
2. 需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
3. 必须保证两个NameNode之间能够ssh无密码登录
4. 隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
三. HDFS-HA自动故障转移工作机制
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
1. 故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
2. 现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
1. 健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2. ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
3. 基于ZooKeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役NameNode,然后本地NameNode转换为Active状态。
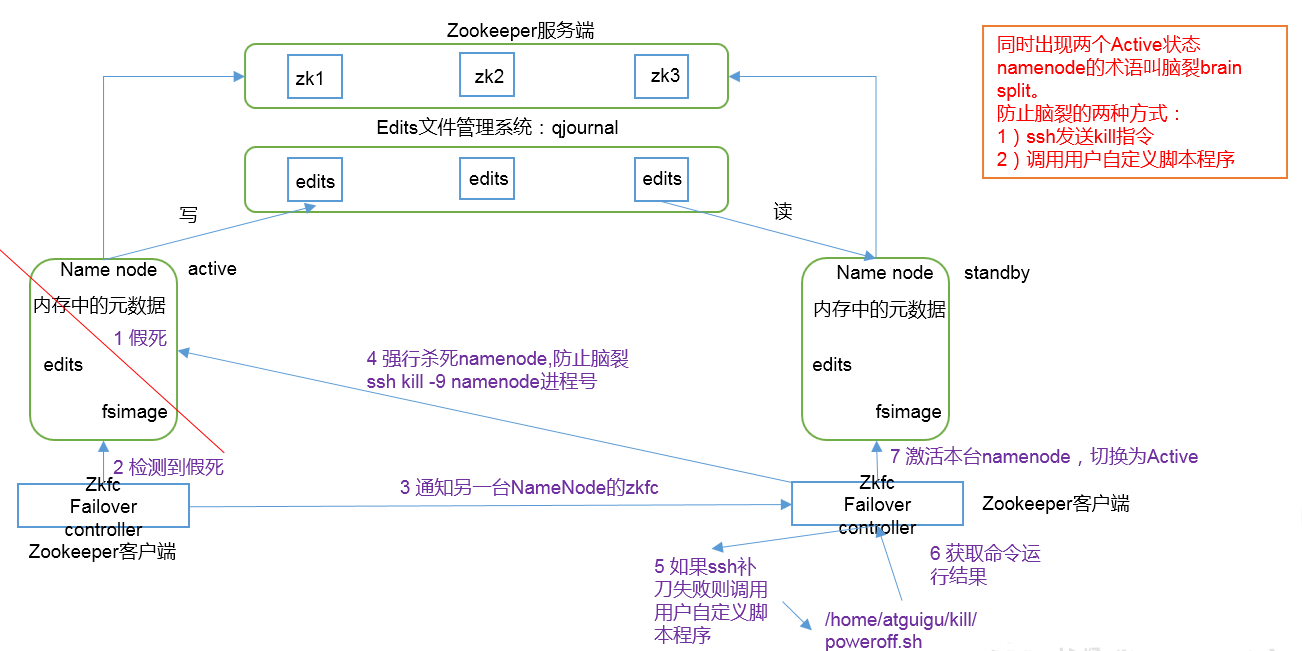
单节点相当不可靠,所以用多节点来解决.多节点就会涉及到两个问题--谁是主谁是从(一个写多个读),以及如何确保通信.
既然每个节点都会宕机,所以写出去的edits.log就要放到一个第三方上--qjournal,而且qjournal也是一个集群,对外提供一致性接口.
NameNode之间直接通信不可靠,所以需要一个ZooKeeper来作为中介,实时监控状态.状态为Active的才可以写,其他的只能读,以及更频繁的做原本2NN做的备份的事情
Zkfc的出现,是为了不破坏已有的代码健壮性和稳定性
如果不确定Active节点是宕机还是网络问题,千万不要贸然让另外的节点上位为Active.如果是之间的网络通信问题而贸然上位,将会产生非常严重的脑裂现象,让数据全部都不可靠
四. HDFS-HA集群配置
|
hadoop100 |
hadoop101 |
hadoop102 |
|
NameNode |
NameNode |
|
|
JournalNode |
JournalNode |
JournalNode |
|
DataNode |
DataNode |
DataNode |
|
ZK |
ZK |
ZK |
|
ResourceManager |
||
|
NodeManager |
NodeManager |
NodeManager |
1. 配置Zookeeper集群,详见zookeeper系列文章
2. 配置HA集群 官方地址:http://hadoop.apache.org/
1). 在/opt/module/目录下创建一个文件夹
mkdir ha
2). 将/opt/module目录下的hadoop2.7.2拷贝一份至ha目录下
cp -r hadoop-2.7./ /opt/module/ha/
3). 删除/opt/module/ha/hadoop2.7.2目录下的data logs 以及其他没用的上传文件
4).cd etc文件夹下, 重新配置core-site.xml文件
<configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/ha/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
5). 重新配置hdfs-site.xml,如果没有配置机器间的无密登录,需要先去生成和设置.注意集群名称是要对应的,以及每个节点的host名称,以及路径,不要搞错咯~~
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property> <!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property> <!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop100:9000</value>
</property> <!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop101:9000</value>
</property> <!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop100:50070</value>
</property> <!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop101:50070</value>
</property> <!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop100:8485;hadoop101:8485;hadoop102:8485/mycluster</value>
</property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/nty/.ssh/id_rsa</value>
</property> <!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/ha/hadoop-2.7.2/data/jn</value>
</property> <!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property> <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
6). 使用脚本,同步到hadoop101和hadoop102机器,(脚本参考这一章Hadoop(4)-Hadoop集群环境搭建)
xsync /opt/module/ha
五.启动HDFS-HA集群
1. 在各个JournalNode节点上,输入以下命令启动journalnode服务
sbin/hadoop-daemon.sh start journalnode
2. 在[nn1]上,对其进行格式化,并启动
bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode
3. 在[nn2]上,同步nn1的元数据信息
bin/hdfs namenode -bootstrapStandby
4. 启动[nn2]
sbin/hadoop-daemon.sh start namenode
5. 查看web页面显示
http://hadoop100:50070/dfshealth.html#tab-overview
http://hadoop101:50070/dfshealth.html#tab-overview
两个节点均为standby状态
6. 在[nn1]上,启动所有datanode
sbin/hadoop-daemons.sh start datanode
六. 配置HDFS-HA故障自动转移
1). 在hdfs-site.xml中增加
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
在core-site.xml中增加
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop100:2181,hadoop101:2181,hadoop102:2181</value>
</property>
xsync同步配置文件
2). 启动
关闭所有HDFS服务:
sbin/stop-dfs.sh
启动Zookeeper集群:
bin/zkServer.sh start
初始化HA在Zookeeper中状态:
bin/hdfs zkfc -formatZK
启动HDFS服务:
sbin/start-dfs.sh
3). 验证
将Active NameNode进程kill,观察另外一个节点是否自动成为Active
kill - namenode的进程id
七.YARN-HA配置
1). 官方文档:
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
2). yarn-ha工作机制

3).集群规划
|
hadoop100 |
hadoop101 |
hadoop102 |
|
NameNode |
NameNode |
|
|
JournalNode |
JournalNode |
JournalNode |
|
DataNode |
DataNode |
DataNode |
|
ZK |
ZK |
ZK |
|
ResourceManager |
ResourceManager |
|
|
NodeManager |
NodeManager |
NodeManager |
4). 配置yran-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop100</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop101</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop100:2181,hadoop101:2181,hadoop102:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
xsync配置文件到其他机器
5). 启动
先启动hdfs-ha
启动yarn-ha
在hadoop100中执行:
sbin/start-yarn.sh
在hadoop101中执行:
sbin/yarn-daemon.sh start resourcemanager
查看服务状态
bin/yarn rmadmin -getServiceState rm1
Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA的更多相关文章
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- MongoDB高可用集群配置的方案
>>高可用集群的解决方案 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性. ...
- SpringCloud-day04-Eureka高可用集群配置
5.4Eureka高可用集群配置 在高并发的情况下一个注册中心难以满足,因此一般需要集群配置多台. 我们再新建两个module microservice-eureka-server-2002, m ...
- Eureka注册中心高可用集群配置
Eureka高可用集群配置 当注册中心扛不住高并发的时候,这时候 要用集群来扛: 我们再新建两个module microservice-eureka-server-2002 microservic ...
- MongoDB高可用集群配置方案
原文链接:https://www.jianshu.com/p/e7e70ca7c7e5 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非 ...
- Hadoop完全高可用集群安装
架构图(HA模型没有SNN节点) 用vm规划了8台机器,用到了7台,SNN节点没用 NN DN SN ZKFC ZK JNN RM NM node1 * * node2 * ...
- RHCS高可用集群配置(luci+ricci+fence)
一.什么是RHCS RHCS是Red Hat Cluster Suite的缩写,也就是红帽集群套件,RHCS是一个能够提供高可用性.高可靠性.负载均衡.存储共享且经济廉价的集群工具集合,它将集群 ...
- MongoDB分片技术原理和高可用集群配置方案
一.Sharding分片技术 1.分片概述 当数据量比较大的时候,我们需要把数分片运行在不同的机器中,以降低CPU.内存和Io的压力,Sharding就是数据库分片技术. MongoDB分片技术类似M ...
- Hadoop入门学习笔记-第二天 (HDFS:NodeName高可用集群配置)
说明:hdfs:nn单点故障,压力过大,内存受限,扩展受阻.hdfs ha :主备切换方式解决单点故障hdfs Federation联邦:解决鸭梨过大.支持水平扩展,每个nn分管一部分目录,所有nn共 ...
随机推荐
- 【Mood 21】要不要重复造轮子
90%的人应该使用另外10%的人制造的轮子 但是每个人都应该有能力去创造属于自己的轮子 使用不代表伸手拿来,使用也是需要学习的,使用也可以升级为创新,关键在于这个轮子是在谁的手中! 90%的能套用着别 ...
- bean 的生命周期
就是在new ClassPathXMLApplicationContext 的时候是否就直接在内存中new 出来,如果是对象比较的情景下 ,为了提高程序初始化的速度,可以用用. 如果设置为 true ...
- spring----对IoC和DI的理解
学习过Spring框架的人一定都会听过Spring的IoC(控制反转) .DI(依赖注入)这两个概念,对于初学Spring的人来说,总觉得IoC .DI这两个概念是模糊不清的,是很难理解的,今天和 ...
- ORA-07445: exception encountered: core dump [kglpin()+527]
此报错在MOS上查到了相关信息:APPLIES TO: Oracle Database - Enterprise Edition - Version 11.2.0.4 and laterInforma ...
- js的作用域与作用域链
JavaScript的作用域和作用域链.在初学JavaScript时,觉得它就和其他语言没啥区别,尤其是作用域这块,想当然的以为“全局变量就是在整个程序的任何地方都可以访问,也就是写在函数外的变量,局 ...
- Echarts横坐标倾斜,顶部显示数字
最近项目使用到Echarts,所以学习了下 根据API,实现Echarts很简单,在这就不多说了,下面就说说项目中碰到的一些需求 1.由于横坐标很多,导致数据不能展示完整,所以需要设置横坐标样式倾斜展 ...
- 【洛谷1494】[国家集训队] 小Z的袜子(莫队)
点此看题面 大致题意: 有\(N\)只从\(1\sim N\)编号的袜子,告诉你每只袜子的颜色,\(M\)组询问,每组询问给你一个区间\([L\sim R]\),让你求出小Z随机抽出\(2\)只袜子时 ...
- 【[NOI2006]最大获利】
题目 并不知到为什么这道题讲了这么久 我们发现这道题就是最小割的板子啊,完全可以套上文理分科的板子 把每个机器和\(T\)连边,容量为\(p_i\),这些\(p_i\)并不计入总贡献 对于每一个要求我 ...
- where are you going ? 反序为:going you are where
一个反序小算法,就是首尾替换,生成新的反序后的数组
- Spring Boot 推荐的基础 POM 文件
名称 说明 spring-boot-starter 核心 POM,包含自动配置支持.日志库和对 YAML 配置文件的支持. spring-boot-starter-amqp 通过 spring-rab ...