python线程与进程小结
传统方式是调用2个方法执行1个任务,方法按顺序依次执行
# -*- coding:utf-8 -*-
import threading
import time
def run(n):
print('task',n)
time.sleep(3)
if __name__ == '__main__':
run('t1')
run('t2')
多线程例子 2个线程同时并发执行1个任务
# -*- coding:utf-8 -*-
import threading
import time
def run(n):
print('task',n)
time.sleep(3)
if __name__ == '__main__':
t1=threading.Thread(target=run,args=('t1',))
t2=threading.Thread(target=run,args=('t2',))
t1.start()
t2.start()
自己写一个类继承继承threading.Thread
# -*- coding:utf-8 -*-
import threading
import time
class MyThread(threading.Thread):
def __init__(self,n):
super(MyThread,self).__init__()
self.n=n
#这里面默认就有一个run方法
def run(self):
print('runing task',self.n)
if __name__ == '__main__':
#在主方法通过对象调用线程
t1=MyThread('t1')
t2=MyThread('t2')
t1.run()
t2.run()
使用for循环启动多个线程
# -*- coding:utf-8 -*-
import threading
import time
def run(n):
print('task',n)
time.sleep(3)
if __name__ == '__main__':
for i in range(10):
t=threading.Thread(target=run,args=('t-%s'%i,))
t.start()
等多线程同时执行完后,再执行其它代码,因为线程是与其它代码一起运行的
# -*- coding:utf-8 -*-
import threading
import time
def run(n):
print('task',n)
time.sleep(3)
if __name__ == '__main__':
time_start=time.time()
#定义一个空列表装线程t实例
t_objects=[]
for i in range(10):
t=threading.Thread(target=run,args=('t-%s'%i,))
t.start()
t_objects.append(t)
# 等所有线程执行完后,再执行下面的代码
# 因为线程与下面的代码是同时运行的
# 要想先等线程执行完毕再执行其它代码
# 使用join()方法进行阻塞
#在这里统一结束所有t线程
for i in t_objects:
t.join()
time_end=time.time()
sun=time_end-time_start
print(sun)
守护线程
程序会等非守护线程执行完毕,才会结束程序,不会等守护线程执行完毕
# -*- coding:utf-8 -*-
import threading
import time
def run(n):
print('task',n)
time.sleep(3)
if __name__ == '__main__':
time_start=time.time()
#定义一个空列表装线程t实例
# t_objects=[]
for i in range(10):
t=threading.Thread(target=run,args=('t-%s'%i,))
t.setDaemon(True)#把当前所有的子线程设置为守护线程
t.start()
# t_objects.append(t)
# for i in t_objects:
# t.join()
time_end=time.time()
sun=time_end-time_start
print(sun)
# 主线程退出时不会等待子线程执行完毕后再退出
print('主线程退出')
# -*- coding:utf-8 -*-
__author__ = "Alex Li"
import threading
import time
def run(n):
lock.acquire()
global num
num +=1
time.sleep(1)
lock.release()
lock = threading.Lock()
num = 0
t_objs = [] #存线程实例
for i in range(10):
t = threading.Thread(target=run,args=("t-%s" %i ,))
t.start()
t_objs.append(t) #为了不阻塞后面线程的启动,不在这里join,先放到一个列表里
for t in t_objs: #循环线程实例列表,等待所有线程执行完毕
t.join()
print("----------all threads has finished...",threading.current_thread(),threading.active_count())
print("num:",num)
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print('--get num:',num )
time.sleep(1)
num -=1 #对此公共变量进行-1操作
num = 100 #设定一个共享变量
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print('final num:', num )
正常来讲,这个num结果应该是0, 但在python 2.7上多运行几次,会发现,最后打印出来的num结果不总是0,为什么每次运行的结果不一样呢? 哈,很简单,假设你有A,B两个线程,此时都 要对num 进行减1操作, 由于2个线程是并发同时运行的,所以2个线程很有可能同时拿走了num=100这个初始变量交给cpu去运算,当A线程去处完的结果是99,但此时B线程运算完的结果也是99,两个线程同时CPU运算的结果再赋值给num变量后,结果就都是99。那怎么办呢? 很简单,每个线程在要修改公共数据时,为了避免自己在还没改完的时候别人也来修改此数据,可以给这个数据加一把锁, 这样其它线程想修改此数据时就必须等待你修改完毕并把锁释放掉后才能再访问此数据。
*注:不要在3.x上运行,不知为什么,3.x上的结果总是正确的,可能是自动加了锁
加锁版本
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print('--get num:',num )
time.sleep(1)
lock.acquire() #修改数据前加锁
num -=1 #对此公共变量进行-1操作
lock.release() #修改后释放
num = 100 #设定一个共享变量
thread_list = []
lock = threading.Lock() #生成全局锁
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print('final num:', num )
GIL VS Lock
机智的同学可能会问到这个问题,就是既然你之前说过了,Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock? 注意啦,这里的lock是用户级的lock,跟那个GIL没关系 ,具体我们通过下图来看一下+配合我现场讲给大家,就明白了。
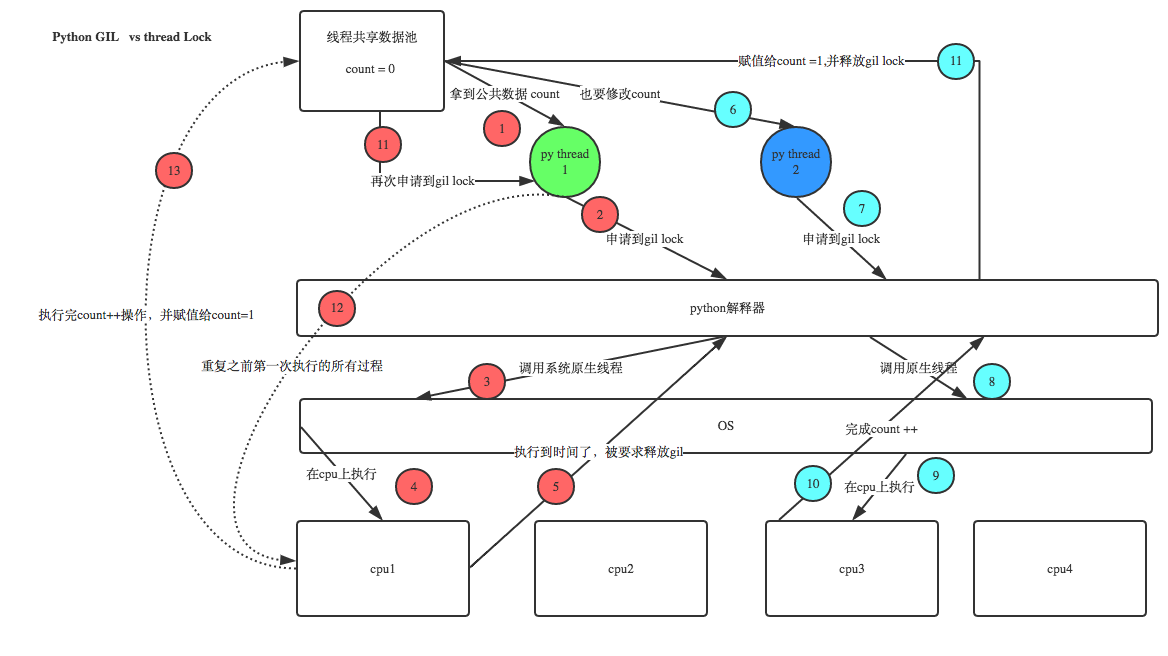
那你又问了, 既然用户程序已经自己有锁了,那为什么C python还需要GIL呢?加入GIL主要的原因是为了降低程序的开发的复杂度,比如现在的你写python不需要关心内存回收的问题,因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
RLock(递归锁)
说白了就是在一个大锁中还要再包含子锁
import threading,time
def run1():
print("grab the first part data")
lock.acquire()
global num
num +=1
lock.release()
return num
def run2():
print("grab the second part data")
lock.acquire()
global num2
num2+=1
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print('--------between run1 and run2-----')
res2 = run2()
lock.release()
print(res,res2)
if __name__ == '__main__':
num,num2 = 0,0
lock = threading.RLock()
for i in range(10):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1:
print(threading.active_count())
else:
print('----all threads done---')
print(num,num2)
进程
单进程
# -*- coding:utf-8 -*-
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
print("\n\n")
def f(name):
info('\033[31;1mcalled from child process function f\033[0m')
print('hello', name)
if __name__ == '__main__':
info('\033[32;1mmain process line\033[0m')
p = Process(target=f, args=('bob',))
p.start()
p.join()
多进程
# -*- coding:utf-8 -*-
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
print("\n\n")
def f(name):
info('\033[31;1mcalled from child process function f\033[0m')
print('hello', name)
if __name__ == '__main__':
for i in range(10):
info('\033[32;1mmain process line\033[0m')
p = Process(target=f, args=('bob',))
p.start()
p.join()
在进程里面启动线程
# -*- coding:utf-8 -*-
from multiprocessing import Process
import threading
import os,time
def thread_run():
print(threading.get_ident())
def run(name):
time.sleep(2)
print('hello',name)
t=threading.Thread(target=thread_run,)
t.start()
t.join()
if __name__ == '__main__':
for i in range(10):
p = Process(target=run, args=('bob',))
p.start()
p.join()
进程通讯
不同进程间内存是不共享的,要想实现两个进程间的数据交换,可以用以下方法:
Queues
使用方法跟threading里的queue差不多
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()
Pipes
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
Managers
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '
d['] = 2
d[0.25] = None
l.append(1)
print(l)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5))
p_list = []
for i in range(10):
p = Process(target=f, args=(d, l))
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(d)
print(l)
进程同步
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()
进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply
- apply_async
from multiprocessing import Process,Pool
import time
def Foo(i):
time.sleep(2)
return i+100
def Bar(arg):
print('-->exec done:',arg)
pool = Pool(5)
for i in range(10):
pool.apply_async(func=Foo, args=(i,),callback=Bar)
#pool.apply(func=Foo, args=(i,))
print('end')
pool.close()
pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
python线程与进程小结的更多相关文章
- Python 线程(threading) 进程(multiprocessing)
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- Python 线程和进程和协程总结
Python 线程和进程和协程总结 线程和进程和协程 进程 进程是程序执行时的一个实例,是担当分配系统资源(CPU时间.内存等)的基本单位: 进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其 ...
- Python线程,进程,携程,I/O同步,异步
只有本人能看懂的-Python线程,进程,携程,I/O同步,异步 举个栗子: 我想get三个url,先用普通的for循环 import requests from multiprocessing im ...
- Python 线程、进程和协程
python提供了两个模块来实现多线程thread 和threading ,thread 有一些缺点,在threading 得到了弥补,为了不浪费时间,所以我们直接学习threading 就可以了. ...
- python 线程与进程
线程和进程简介 应用程序和进程以及线程的关系? 一个应用程序里可以有多个进程,一个进程里可以有多个线程 最原始的计算机是如何运行的? CPU是什么?为什么要使用多个CPU? 为什么要使用多线程? 为什 ...
- python基础-第九篇-9.1初了解Python线程、进程、协程
了解相关概念之前,我们先来看一张图 进程: 优点:同时利用多个cpu,能够同时进行多个操作 缺点:耗费资源(重新开辟内存空间) 线程: 优点:共享内存,IO操作时候,创造并发操作 缺点:抢占资源 通过 ...
- python线程、进程和协程
链接:http://www.jb51.net/article/88825.htm 引言 解释器环境:python3.5.1 我们都知道python网络编程的两大必学模块socket和socketser ...
- python 线程、进程与协程
一.什么是线程?什么是进程? 第一,进程是一个实体.每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region).数据区域(data region)和堆栈(stack regio ...
- python 线程,进程与协程
引言 线程 创建普通多线程 线程锁 互斥锁 信号量 事件 条件锁 定时器 全局解释器锁 队列 Queue:先进先出队列 LifoQueue:后进先出队列 PriorityQueue:优先级队列 deq ...
随机推荐
- java面试题之 -----面向切面编程
这种在运行时,动态地将代码切入到类的指定方法.指定位置上的编程思想就是面向切面的编程. 面向切面编程(AOP是Aspect Oriented Program的首字母缩写) ,我们知道,面向对象的特点是 ...
- JavaScript类型操作以及一些规范
类型检测 类型检测优先使用 typeof.对象类型检测使用 instanceof.null 或 undefined 的检测使用 == null. // string typeof variable = ...
- angular2 里父子组件传值的坑
1.如果传的是基本类型的值,子组件里改变该值,父组件无变化 2.如果传的是对象,子组件里改变对象里的变量,父组件会变化 3.如果传的是函数,this不会继续指向父组件对象了,如果需要this指向父组件 ...
- 设计模式——原型模式(Prototype Pattern)
原型模式:用原型实例制定创建对象的种类,并且通过拷贝这些原型创建新的对象. UML 图: 原型类: package com.cnblog.clarck; /** * 原型类 * * @author c ...
- POJ 2985 名次树
题意:1~n个猫,有合并操作,有询问操作,合并两只猫所在的集合,询问第K大的集合. 分析:合并操作用并查集,用size维护,询问操作用Treap.注意优化,不能刚开始就把所有size = 1放到名次树 ...
- HDU 3038 How Many Answers Are Wrong 【YY && 带权并查集】
任意门:http://acm.hdu.edu.cn/showproblem.php?pid=3038 How Many Answers Are Wrong Time Limit: 2000/1000 ...
- Vue.js系列之vue-resource(6)
网址:http://blog.csdn.net/u013778905/article/details/54235906
- Android学习笔记_70_一个应用程序启动另一个应用程序的Activity
第一种(我自己写的) :之前在网上看来一些,很多不是我要的可以启动另外一个应用程序的主Activity. //这些代码是启动另外的一个应用程序的主Activity,当然也可以启动任意一个Activit ...
- plsql Developer11的工具栏没有了如何找回来
以前都是用的plsql developer7,最常用的工具类如下: 这次下载了12,发现风格变了,经常用的执行.提交.回滚按钮都在会话菜单下了 如何找回工具栏呢,如下操作:
- linux网络相关配制及命令
1.虚拟机配制 查看ip: ip addr 配制网卡(读者可以忽略): 编辑虚拟网络编辑器,修改子网IP 查看ip,输入ip addr 开启网络:ifup eth0 关闭网络:ifdown eth0 ...