Scrapy 增量式爬虫
Scrapy 增量式爬虫
https://blog.csdn.net/mygodit/article/details/83931009
https://blog.csdn.net/mygodit/article/details/83896412
https://blog.csdn.net/qq_39965716/article/details/81073015
一、定义
二、原理
spider构造的第一个Request请求经由引擎交给了Scheduler,Scheduler中构造一个request对象,并将这个对象存入一个Scheduler的队列中,入队之前会生成一个对应的,唯一的指纹,下一个request对象入队之前,会先比对指纹是否已经存在,以此来达到request对象去重的目的。
Scheduler中Request对象的初始化属性,其中dont_filter表示不去重,默认是False。所以scrapy框架默认是去重的。
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
Rquest
爬虫组件Spider中,负责构造request对象是 start_requests(self) 函数。Spider构造的request对象修改了dont_filter属性。
源码如下:
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Scrapy去重的原理
Scrapy去重原理是通过sha1()加密request对象的url,method,body属性生成一个十六进制的40位随机字符串,称为指纹。将每个request对象对应的唯一指纹保存到Scheduler队列中,下次请求时,通过对比指纹,来达到request对象去重的目的。
生成指纹集合的源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
存储在Scheduler中的reqeust队列,是放在内存上的,如果服务器关闭,或者重启,内存中的缓存就会清空,下次请求就会继续访问原来发送过的请求。
增量式爬虫的意义就是将reques队列持久化存储,以此来达到永久性的缓存。
对此需要用到scrapy_redis(需要pip install scarpy_redis),将request对象的队列和指纹集合存储的位置替换成redis。如下图所示:
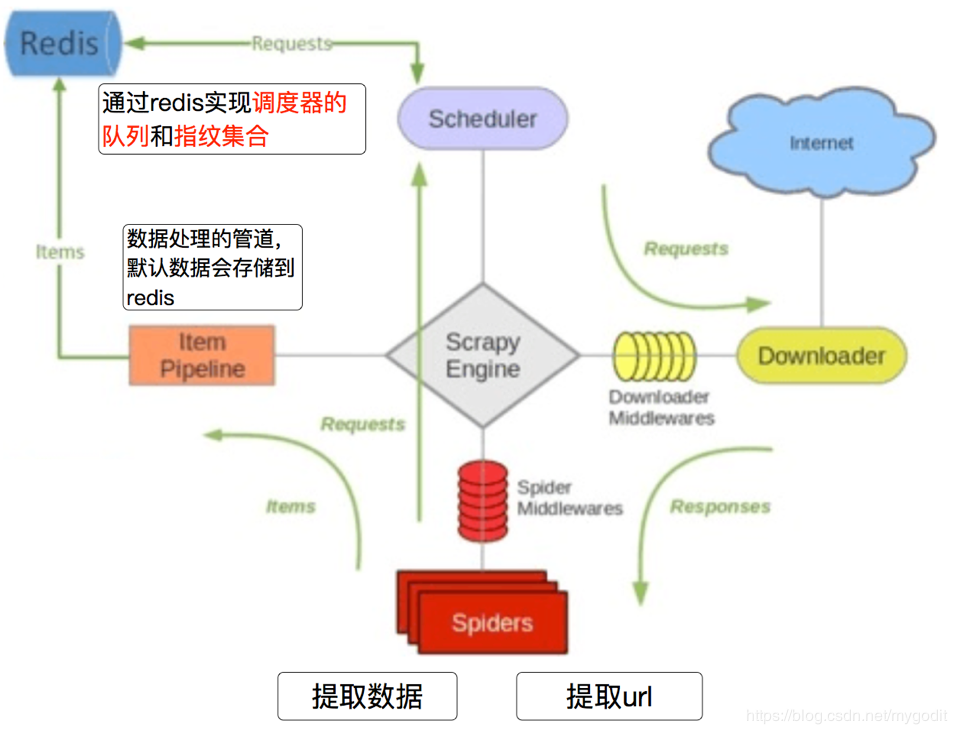
只需要在settings.py文件中添加一些配置,就能实现持久化去重的效果:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True # 添加redis链接
REDIS_URL = "redis://127.0.0.1:6379" # 或者使用下面的方式
# REDIS_HOST = "127.0.0.1"
# REDIS_PORT = 6379 # 在pipeline中添加存储信息的scrapy_redis管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
Scrapy 增量式爬虫的更多相关文章
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- 增量式爬虫 Scrapy-Rredis 详解及案例
1.创建scrapy项目命令 scrapy startproject myproject 2.在项目中创建一个新的spider文件命令: scrapy genspider mydomain mydom ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- 爬虫---scrapy分布式和增量式
分布式 概念: 需要搭建一个分布式的机群, 然后在每一台电脑中执行同一组程序, 让其对某一网站的数据进行联合分布爬取. 原生的scrapy框架不能实现分布式的原因 调度器不能被共享, 管道也不能被共享 ...
- 爬虫 crawlSpider 分布式 增量式 提高效率
crawlSpider 作用:为了方便提取页面整个链接url,不必使用创参寻找url,通过拉链提取器,将start_urls的全部符合规则的URL地址全部取出 使用:创建文件scrapy startp ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- Scrapy 框架 增量式
增量式: 用来检测网站中数据的更新情况 from scrapy.linkextractors import LinkExtractor from scrapy.spiders import Crawl ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [三] 配置式爬虫
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 上一篇介绍的基本的使用方式,虽然自由度很高,但是编写的代码相对还是挺多.于是框 ...
- 增量式PID计算公式4个疑问与理解
一开始见到PID计算公式时总是疑问为什么是那样子?为了理解那几道公式,当时将其未简化前的公式“活生生”地算了一遍,现在想来,这样的演算过程固然有助于理解,但假如一开始就带着对疑问的答案已有一定看法后再 ...
随机推荐
- [置顶]
STM32 输入捕获的脉冲宽度及频率计算
输入捕获模式可以用来测量脉冲宽度或者测量频率.STM32 的定时器,除了 TIM6 和 TIM7,其他定时器都有输入捕获功能.以下是对脉冲宽度及频率的计算. 1.脉冲宽度 如下图所示,采集该高电平脉冲 ...
- Android的按钮单击事件及监听器的实现方式
第一种:匿名内部类作为事件监听器类 大部分时候,事件处理器都没有什么利用价值(可利用代码通常都被抽象成了业务逻辑方法),因此大部分事件监听器只是临时使用一次,所以使用匿名内部类形式 的事件监听器更合适 ...
- python中的异常处理机制
python中的异常处理 1.什么是异常 异常就是程序运行时发生错误的信号(在程序出现错误时,则会产生一个异常,若程序没有处理它,则会抛出该异常,程序的运行也随之终止),在python中,错误触发的异 ...
- springboot成神之——spring文件下载功能
本文介绍spring文件下载功能 目录结构 DemoApplication WebConfig TestController MediaTypeUtils 前端测试 本文介绍spring文件下载功能 ...
- Android 从本地图库或拍照后裁剪图片并设置头像
在QQ和微信等应用都会有设置头像,一般都是从本地图库选取或相机拍照,然后再截图自己喜欢的部分,然后设置.最后一步把截取好的图片再保存到本地,来保存头像.为了大家使用方便,我把自己完整的代码贴出来,大家 ...
- mysql中的自定义函数
创建不带参数的自定义函数: 使用: 创建带参数的自定义函数: 使用: 创建具有复合结构的函数体的自定义函数:
- Leetcode:Regular Expression Matching分析和实现
题目大意是要求我们实现一个简单的正则表达式全匹配判断.其中正则表达式中只包含一般字符,以及全匹配字符.和变长字符*.其中.可以匹配一个字符,而*与前一个字符相关联,x*可以被看作任意多个x(0到正无穷 ...
- ZOJ 3956 Course Selection System
题意 有n节课可供选择,每节课都有两个值Hi和Ci,如果学生选择了m节课(x1,x2,....,xm),则它的舒适值被定义为: //这里没有公式((lll¬ω¬)),因为那个图片我保存不下来≧ ﹏ ≦ ...
- Junit问题01 利用 @Autowired 注入失效问题
1 利用 @Autowired 注入失效问题 1.1 问题描述 在使用Junit作为测试框架的单元测试中,直接了用@Autowired记性依赖注入时总是注入失败 1.2 问题原因 在测试类中没有设定上 ...
- 238. Product of Array Except Self 由非己元素形成的数组
[抄题]: Given an array of n integers where n > 1, nums, return an array output such that output[i] ...