Kylin -- Dup key found 问题
kylin 构建 cube 时,抛出了如下的错误:
org.apache.kylin.engine.mr.exception.HadoopShellException: java.lang.RuntimeException: Checking snapshot of TableRef[xxx] failed.
at org.apache.kylin.cube.cli.DictionaryGeneratorCLI.processSegment(DictionaryGeneratorCLI.java:)
at org.apache.kylin.cube.cli.DictionaryGeneratorCLI.processSegment(DictionaryGeneratorCLI.java:)
at org.apache.kylin.engine.mr.steps.CreateDictionaryJob.run(CreateDictionaryJob.java:)
at org.apache.kylin.engine.mr.MRUtil.runMRJob(MRUtil.java:)
at org.apache.kylin.engine.mr.common.HadoopShellExecutable.doWork(HadoopShellExecutable.java:)
at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:)
at org.apache.kylin.job.execution.DefaultChainedExecutable.doWork(DefaultChainedExecutable.java:)
at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:)
at org.apache.kylin.job.impl.threadpool.DistributedScheduler$JobRunner.run(DistributedScheduler.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.lang.IllegalStateException: The table: xxx Dup key found, key=[null], value1=[null,null,null,null,null], value2=[null,null,null,null,null]
at org.apache.kylin.dict.lookup.LookupTable.initRow(LookupTable.java:)
at org.apache.kylin.dict.lookup.LookupTable.init(LookupTable.java:)
at org.apache.kylin.dict.lookup.LookupStringTable.init(LookupStringTable.java:)
at org.apache.kylin.dict.lookup.LookupTable.<init>(LookupTable.java:)
at org.apache.kylin.dict.lookup.LookupStringTable.<init>(LookupStringTable.java:)
at org.apache.kylin.dict.lookup.LookupProviderFactory.getInMemLookupTable(LookupProviderFactory.java:)
at org.apache.kylin.cube.CubeManager.getInMemLookupTable(CubeManager.java:)
at org.apache.kylin.cube.CubeManager.getLookupTable(CubeManager.java:)
at org.apache.kylin.cube.cli.DictionaryGeneratorCLI.processSegment(DictionaryGeneratorCLI.java:)
... more
其中 xxx 表是维度表,它跟事实表是一对多的关系。抛出的错误很令人费解,怎么会全是 null 的值呢? xxx 表里没有这样的记录啊。key 是 id,在 Mysql 里是自增长的主键,也不可能是空,所以导入 hive 后,也不可能为空。日志显示是在生成 xxx 表的 snapshot 时产生的,在网上搜了一下,https://juejin.im/post/5bcf370d6fb9a05cff3255dd 这篇文章中有关于此过程的描述,摘录如下:
(1)从原始的hive维度表中顺序得读取每一行每一列的值;
(2)使用 TrieDictionary 方式对这些所有的值进行编码(一个值对应一个 Id);
(3)再次读取原始表中每一行的值,将每一列的值使用编码之后的 Id 进行替换,得到了一个只有 Id 的新表;
(4)同时保存这个新表和 Dictionary 对象(Id 和值的映射关系)就能够保存整个维度表;
(5)Kylin 将这个数据存储到元数据库中
从中也没看出会出现重复主键的情况。后来又看到说是事实表关联此维度表时,如果对应多个,则会出现此问题。本来就是一对多的关系,肯定会出现多个的啊。也不知道是他没表达清楚,还是我没理解。找了很久,也没发现问题所在,后来一个不经意的发现,才使这一问题得到解决。我在 hive 中查看事实表的记录数时,发现有 6500 多条,但是我的 mysql 里只有 6300 条。不知道为什么,sqoop 导入 hive 后,会多出几百条记录。经过查找才知道,如果原始 mysql 里的字段里的值有换行符的话,导入 hive 后,因为hive中存的是文本,换行符是一条记录,所以会多出记录来。并且这些值并不在真正对应的列了。所以会出现事实表的一些记录关联不到维度表的记录,此时就会出现 key=[null], value1=[null,null,null,null,null] 的情况。
解决办法: 在用 sqoop 导入时,多加一个参数: --hive-delims-replacement ' ' ,这会把换行符替换为空格。因为无法确定原始表中会不会有换行符,所以强烈建议不管什么情况都加此参数。
重新导入后,cube 构建成功。问题虽然解决了,但是还是有一处不明白,为什么报的是 Dup key found 的错误,维度表并没有重复主键。
后续:悲催地发现,第二天又出现了这个错误。由于业务的原因,每天晚上都会把 mysql 中的记录用 sqoop 重新导入到 hive 中, 导入的时候,我是加了 --hive-overwrite 这个参数的,用 beeline 连接 hive 后,查询出来的记录也是没问题的。用 kylin 重新构建 cube 时,就出现了 Dup key found 的错误,这次 key 是一个确定的值了,我查了一下 xxx 表,确定这个 key 只有一条记录。我在 hive 客户端,直接 drop table XXX 后,再次用 sqoop 导入,再次构建 cube 竟然成功了。有点迷茫了,再用 sqoop 导一次,再构建 cube 的时候又报这个问题了。
看了一下 HDFS 上目录,发现表 xxx 原来的数据目录并没有删除,而是直接新建了一个目录,hive 客户端会使用最新的目录,不知道为什么 kylin 读的却是所有的目录下的数据,这就导致肯定会出现重复的数据了。
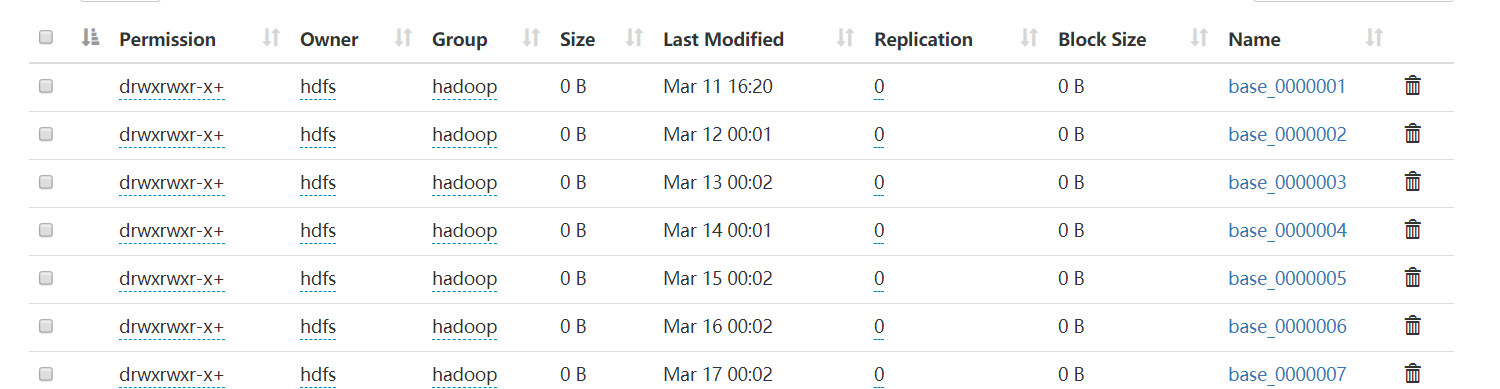
这个的 hadoop 环境是用 HDP 搭建的,我用原始的 hadoop 等包,搭建了一个 hadoop 环境,做重复 sqoop 导入的操作,发现跟上面的不一样,真的是删掉原来的目录,再创建一个的,表对应的目录下永远只有一个数据文件。
最后,总结出来,出现这个问题的原因就是:事实表(列:id)与维度表(列:fact_id) 进行关联时,同一个事实表的 id,关联时出现了超过一次。
Kylin -- Dup key found 问题的更多相关文章
- mongodb E11000 duplicate key error collection: index: _id_ dup key
今天在单测的时候,出现这个问题. 我代码只定义了一个变量 let body = {name: 'wu'} 然后连续2次插入这个body数据 await exam.insertExam(body); a ...
- E11000 duplicate key error index: test.collection.$a.b_1 dup key: { : null } 报错记录
这个一般分为两种情况,第一新增数据出现约束.而你在orm里面写了唯一约束.这种情况就比较简单,添加数据时保证数据字段唯一性就好了. 第二种情况比较难找,因为你发现你在orm里面并没有写约束,但是还是插 ...
- MongoDB学习笔记三—增删改文档上
插入insert 单条插入 > db.foo.insert({"bar":"baz"}) WriteResult({ }) 批量插入 > db.fo ...
- Python: Windows 7 64位 安装、使用 pymongo 3.2
官网tutorial: http://api.mongodb.com/python/current/tutorial.html 本教程将要告诉你如何使用pymongo模块来操作MongoDB数据库. ...
- MongoDB 3.X 用户权限控制
摘要: MongoDB 3.0 安全权限访问控制,在添加用户上面3.0版本和之前的版本有很大的区别,这里就说明下3.0的添加用户的方法. 环境.测试: 在安装MongoDB之后,先关闭auth认证,进 ...
- CentOS7 安装MongoDB 3.0服务器
1,下载&安装 MongoDB 3.0 正式版本发布!这标志着 MongoDB 数据库进入了一个全新的发展阶段,提供强大.灵活而且易于管理的数据库管理系统.MongoDB宣称,3.0新版本不只 ...
- MongoDB学习笔记(索引)
一.索引基础: MongoDB的索引几乎与传统的关系型数据库一模一样,这其中也包括一些基本的优化技巧.下面是创建索引的命令: > db.test.ensureIndex({" ...
- MongoDB索引的使用
Table of Contents 1. 基本索引 2. 联合索引 3. 索引类型 4. 索引管理 1 基本索引 在数据库开发中索引是非常重要的,对于检索速度,执行效率有很大的影响.本 文主要描述了M ...
- Mongodb Manual阅读笔记:CH8 复制集
8 复制 Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb Manual阅读笔 ...
随机推荐
- select,poll,epoll,selectors
一 了解select,poll,epoll IO复用:为了解释这个名词,首先来理解下复用这个概念,复用也就是共用的意思,这样理解还是有些抽象, 为此,咱们来理解下复用在通信领域的使用,在通信领域中为了 ...
- oracle下载地址
12c 下载地址 http://www.oracle.com/technetwork/cn/database/enterprise-edition/downloads/index.html
- [机器学习]numpy broadcast shape 机制
最近在做机器学习的时候,对未知对webshell检测,发现代码提示:ValueError: operands could not be broadcast together with shapes ( ...
- md5加密小程序
#-*- coding:utf-8 -*- __author__ = "MuT6 Sch01aR" import hashlib m = hashlib.md5() m.updat ...
- WEB前端必备掌握知识
1.跨域: 跨域问题是由于javascript语言安全限制中的同源策略造成的.
- HTTP之报文
HTTP 报文 用于 HTTP 协议交互的信息被称为 HTTP 报文.请求端(客户端)的 HTTP 报文叫做请求报文,响应端(服务器端)的叫做响应报文.HTTP 报文本身是由多行(用 CR+LF 作换 ...
- Jquery获取EasyUI时间控件的值
jquery easyui日期控件中,在页面里用JS拿到设置的日期值的方法 jquery easyui 日期框 有这样的一个日期文本框: <input type=" value=&qu ...
- JS判断IE,FF,Opera,Safari等浏览器类型
第一种,只区分浏览器,不考虑版本 function myBrowser(){ var userAgent = navigator.userAgent; //取得浏览器的userAgent字符串 var ...
- Oracle 环境下 GoldenGate 集成抽取(Integrated Capture)模式与传统抽取模式(Classic Capture)间的切换
检查抽取进程模式 在 GGSCI 环境下,执行类似如下语句查看特定进程的状态. GGSCI> info <Group_Name> 其中,<Group_Name> 为进程名 ...
- Redis02 Redis客户端之Java、连接远程Redis服务器失败
1 查看支持Java的redis客户端 本博文采用 Jedis 作为redis客户端,采用 commons-pool2 作为连接redis服务器的连接池 2 下载相关依赖与实战 2.1 到 Repos ...