(数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集。
关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读:
https://www.cnblogs.com/pinard/p/6208966.html
DBSCAN的主要优点有:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3) 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
DBSCAN的主要缺点有:
1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3) 调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
R中的fpc包中封装了dbscan(data,eps,MinPts),其中data为待聚类的数据集,eps为距离阈值ϵ,MinPts为样本数阈值,这三个是必须设置的参数,无缺省项。
一、三种聚类算法在非凸样本集上的性能表现
下面我们以正弦函数为材料构造非凸样本集,分别使用DBSCAN、K-means、K-medoids算法进行聚类,并绘制最终的聚类效果图:
library(fpc)
library(cluster) #构造非凸样本集
x1 <- seq(0,pi,0.01)
y1 <- sin(x1)+0.06*rnorm(length(x1))
y2 <- sin(x1)+0.06*rnorm(length(x1))+0.6
plot(x1,y1,ylim=c(0,2.0))
points(x1,y2)
c1 <- c(x1,x1)
c2 <- c(y1,y2)
data1 <- as.matrix(cbind(c1,c2))
构造的样本集如下:
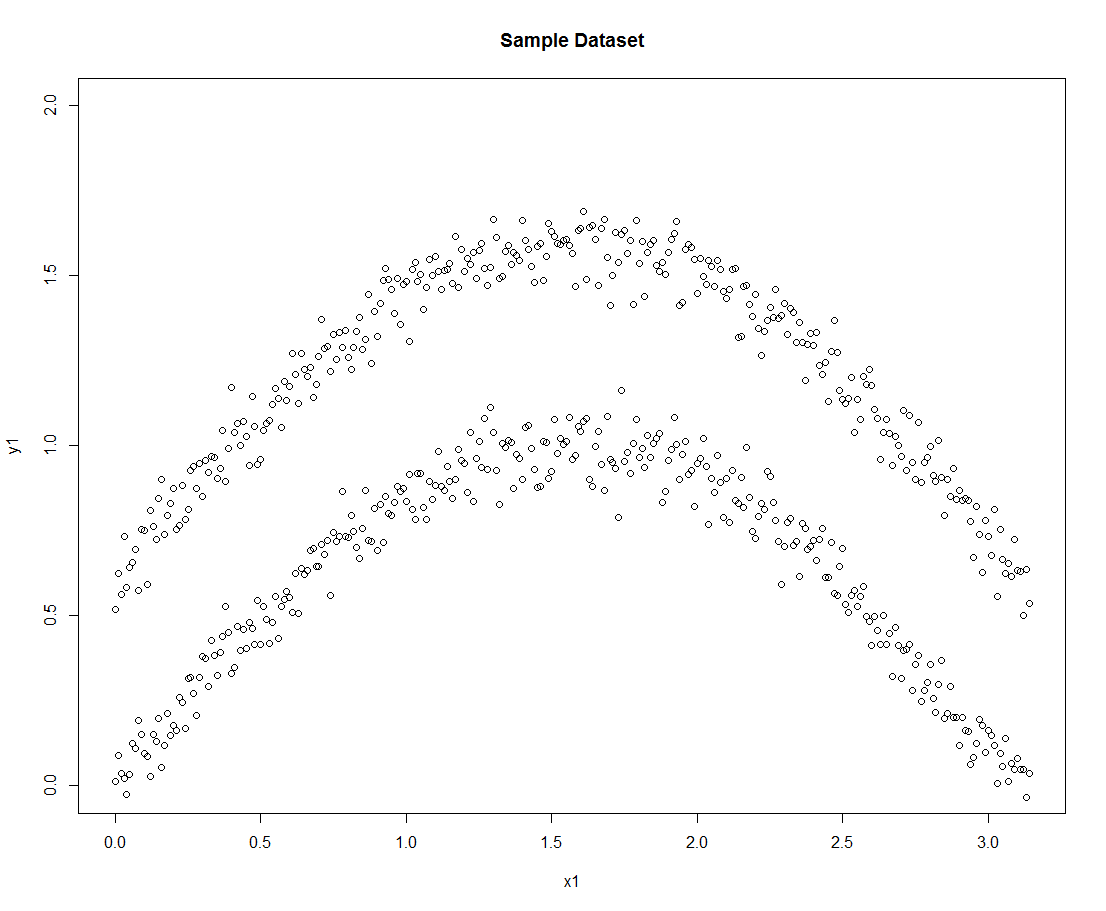
接着我们依次使用上述三种聚类算法:
#分别绘制三种聚类算法的聚类效果图
par(mfrow=c(1,3))
#DBSCAN聚类法
db <- dbscan(data1,eps=0.2,MinPts = 5)
db$cluster
plot(data1,col=db$cluster)
title('DBSCAN Cluster')
#K-means聚类法
km <- kmeans(data1,centers=2)
km$cluster
plot(data1,col=km$cluster)
title('K-means Cluster')
#K-medoids聚类法
pm <- pam(data1,k=2)
pm$clustering
plot(data1,col=pm$clustering)
title('K-medoids Cluster')
具体的聚类效果如下:
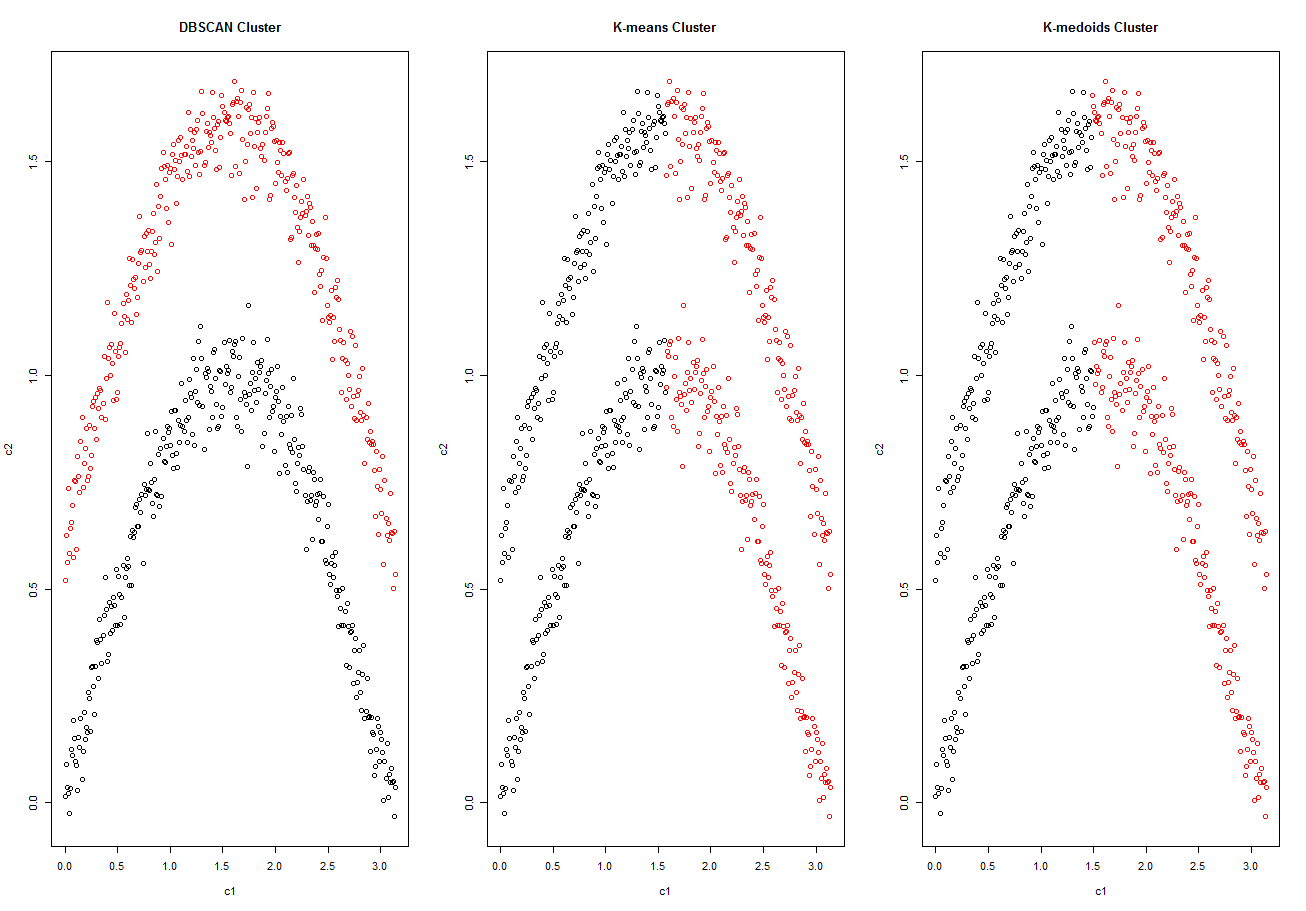
可以看出,在对非凸样本集的聚类上,DBSCAN效果非常好,而另外两种专门处理凸集的聚类算法就遇到了麻烦。
二、DBSCAN算法在常规凸样本集上的表现
上面我们研究了DBSCAN算法在非凸样本集上的表现,比K-means和K-medoids明显优秀很多,下面我们构造一个10维的凸样本集,具体的代码和聚类结果如下:
> library(fpc)
> library(Rtsne)
>
> #创建待聚类数据集
> data1 <- matrix(rnorm(10000,0,0.6),nrow=1000)
> data2 <- matrix(rnorm(10000,1,0.6),nrow=1000)
>
> data <- rbind(data1,data2)
>
> #对原高维数据集进行降维
> tsne <- Rtsne(data)
>
> par(mfrow=c(4,4))
> for(i in 1:16){
+ #进行DBSCAN聚类
+ db <- dbscan(data,eps=1.1+i*0.025,MinPts = 25)
+ #绘制聚类效果图
+ plot(tsne$Y[,1],tsne$Y[,2],col=db$cluster)
+ title(paste('eps=',as.character(1.1+i*0.025),sep=''))
+ print(paste('eps=',as.character(1.1+i*0.025)))
+ print(table(db$cluster))
+ }
[1] "eps= 1.125" 0
2000
[1] "eps= 1.15" 0 1 2
1950 26 24
[1] "eps= 1.175" 0 1 2
1920 59 21
[1] "eps= 1.2" 0 1 2
1834 120 46
[1] "eps= 1.225" 0 1 2
1682 177 141
[1] "eps= 1.25" 0 1 2
1515 250 235
[1] "eps= 1.275" 0 1 2
1305 344 351
[1] "eps= 1.3" 0 1 2
1163 425 412
[1] "eps= 1.325" 0 1 2
989 521 490
[1] "eps= 1.35" 0 1 2
854 596 550
[1] "eps= 1.375" 0 1 2
707 670 623
[1] "eps= 1.4" 0 1 2
572 732 696
[1] "eps= 1.425" 0 1 2
500 766 734
[1] "eps= 1.45" 0 1
420 1580
[1] "eps= 1.475" 0 1
355 1645
[1] "eps= 1.5" 0 1
285 1715
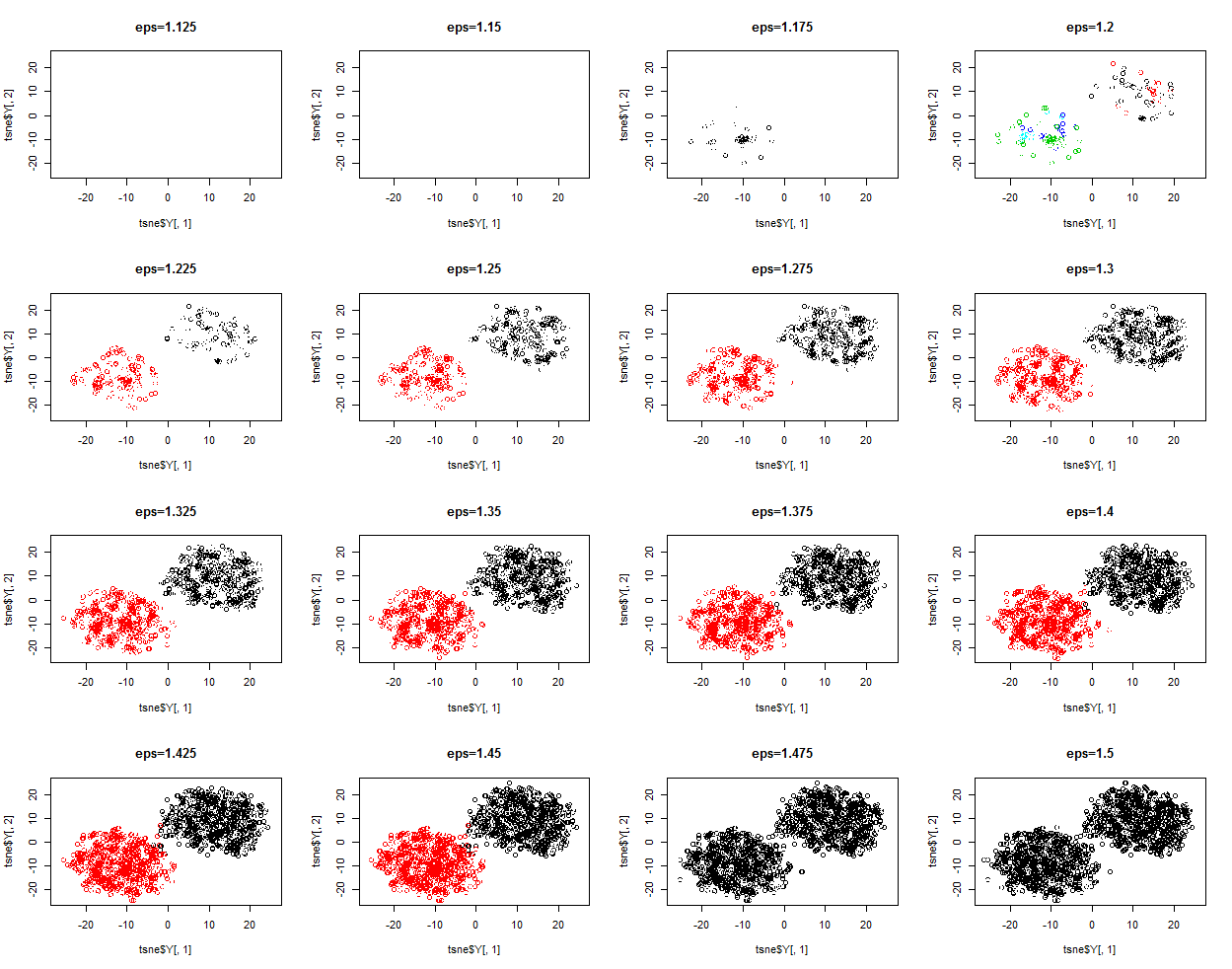
可以看出,DBSCAN虽然性能优越,但是涉及到有些麻烦的调参数的过程,需要进行很多次的试探,没有K-means和K-medoids来的方便快捷。
Python
在Python中,DBSCAN算法集成在sklearn.cluster中,我们利用datasets构造两个非凸集和一个凸集,效果如下:
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import style
from sklearn.cluster import KMeans,DBSCAN style.use('ggplot')
'''构造样本集'''
X1, y1=datasets.make_circles(n_samples=5000, factor=.6,noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[.1]],random_state=9) X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='*')
plt.title('Samples')
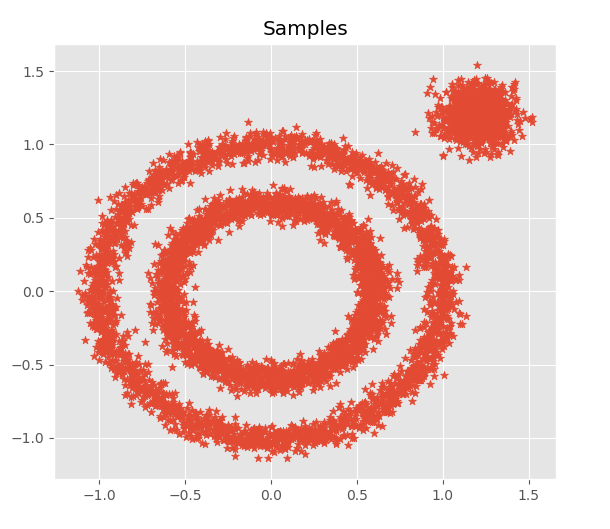
分别使用K-means和DBSCAN对上述样本集进行聚类,效果如下:
'''利用K-means'''
km = KMeans(n_clusters=3).fit_predict(X)
col = [(['red','green','blue','yellow','grey','purple'])[i] for i in km] plt.figure(figsize=(16,8))
plt.subplot(121)
plt.scatter(X[:, 0], X[:, 1], marker='*',c=col)
plt.title('K-means') '''利用DBSCAN'''
db = DBSCAN(eps = 0.12, min_samples = 19).fit_predict(X)
col = [(['red','green','blue','yellow'])[i] for i in db]
plt.subplot(122)
plt.scatter(X[:, 0], X[:, 1], marker='*',c=col)
plt.title('DBSCAN')

对DBSCAN中的参数eps(超球体半径)进行试探:
'''对eps进行试探性调整'''
plt.figure(figsize=(15,15))
for i in range(9):
db = DBSCAN(eps = 0.05+i*0.04, min_samples = 19).fit_predict(X)
col = [(['red','green','blue','yellow','purple','aliceblue','antiquewhite','black','blueviolet','cyan','darkgray'])[i] for i in db]
plt.subplot(331+i)
plt.scatter(X[:, 0], X[:, 1], marker='*',c=col)
plt.title('eps={}'.format(str(round(0.05+i*0.04,2))))
对DBSCAN中的参数MinPts(核心点内最少样本个数)进行试探:
'''对MinPts进行试探性调整'''
plt.figure(figsize=(15,15))
for i in range(9):
db = DBSCAN(eps = 0.12, min_samples = 10+i*4).fit_predict(X)
col = [(['red','green','blue','yellow','purple','aliceblue','antiquewhite','black','blueviolet','cyan','darkgray'])[i] for i in db]
plt.subplot(331+i)
plt.scatter(X[:, 0], X[:, 1], marker='*',c=col)
plt.title('MinPts={}'.format(str(round(10+i*4))))

可见参数的设置对聚类效果的影响非常显著。
以上就是DBSCAN的简单介绍,若发现错误望指出。
(数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现的更多相关文章
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- (数据科学学习手札16)K-modes聚类法的简介&Python与R的实现
我们之前经常提起的K-means算法虽然比较经典,但其有不少的局限,为了改变K-means对异常值的敏感情况,我们介绍了K-medoids算法,而为了解决K-means只能处理数值型数据的情况,本篇便 ...
- (数据科学学习手札17)线性判别分析的原理简介&Python与R实现
之前数篇博客我们比较了几种具有代表性的聚类算法,但现实工作中,最多的问题是分类与定性预测,即通过基于已标注类型的数据的各显著特征值,通过大量样本训练出的模型,来对新出现的样本进行分类,这也是机器学习中 ...
- (数据科学学习手札14)Mean-Shift聚类法简单介绍及Python实现
不管之前介绍的K-means还是K-medoids聚类,都得事先确定聚类簇的个数,而且肘部法则也并不是万能的,总会遇到难以抉择的情况,而本篇将要介绍的Mean-Shift聚类法就可以自动确定k的个数, ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)
聚类分析是数据挖掘方法中应用非常广泛的一项,而聚类分析根据其大体方法的不同又分为系统聚类和快速聚类,其中系统聚类的优点是可以很直观的得到聚类数不同时具体类中包括了哪些样本,而Python和R中都有直接 ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- (数据科学学习手札12)K-means聚类实战(基于R)
上一篇我们详细介绍了普通的K-means聚类法在Python和R中各自的实现方法,本篇便以实际工作中遇到的数据集为例进行实战说明. 数据说明: 本次实战样本数据集来自浪潮集团提供的美团的商家信息,因涉 ...
- (数据科学学习手札09)系统聚类算法Python与R的比较
上一篇笔者以自己编写代码的方式实现了重心法下的系统聚类(又称层次聚类)算法,通过与Scipy和R中各自自带的系统聚类方法进行比较,显然这些权威的快捷方法更为高效,那么本篇就系统地介绍一下Python与 ...
随机推荐
- 关于Visio的vba操作,遍历目录,对所有vsd文件操作,导入excel文件
1.vba遍历要添加引用,runtime 2.不能打开单独的application,因为在获取到shape的picture属性时候,新打开的application不能够获取到.提示自动化错误. 3.定 ...
- 不要在using语句中调用WCF服务
如果你调用WCF服务时,像下面的代码这样在using语句中进行调用,需要注意一个问题. using (CnblogsWcfClient client = new CnblogsWcfClient()) ...
- 【Leetcode】【Easy】String to Integer (atoi)
Implement atoi to convert a string to an integer. Hint: Carefully consider all possible input cases. ...
- 原文:I don’t want to see another “using namespace xxx;” in a header file ever again
http://stackoverflow.com/questions/5849457/using-namespace-in-c-headers http://stackoverflow.com/que ...
- Document flow API in SAP CRM and C4C
Document flow API in CRM 以一个具体的例子来说明.在Appointment的Overview page上能看见一个名叫Reference的区域,这里可以维护一些其他的业务文档的 ...
- Java里面String的编码问题
Java里面内置字符串全部是utf-16编码,详细的编码方式看这里 import java.nio.charset.Charset; import java.util.Arrays; import j ...
- IOS 集成百度地图
申请key ● http://lbsyun.baidu.com/apiconsole/key 下载SDK ● 下载百度地图开发包:http://api.map.baidu.com/lbsapi/clo ...
- kill 使用当前数据库的所有session
--在维护中经常需要将某一数据库所有进程都杀掉,手工杀有点太费事.写了一个存储过程 --usage:proc_kill 'PSADBA' create proc proc_kill(@db varch ...
- python:常用模块二
1,hashlib模块---摘要算法 import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?' ...
- 深度优先搜索(dfs),城堡问题
题目链接:http://poj.org/problem?id=1164 1.深搜,每个点都访问一次,没有标记的话,就做深搜,同时标记. #include <iostream> #inclu ...