大数据架构之:Spark
Spark是UC Berkeley AMP 实验室基于map reduce算法实现的分布式计算框架,输出和结果保存在内存中,不需要频繁读写HDFS,数据处理效率更高
Spark适用于近线或准实时、数据挖掘与机器学习应用场景
Spark和Hadoop
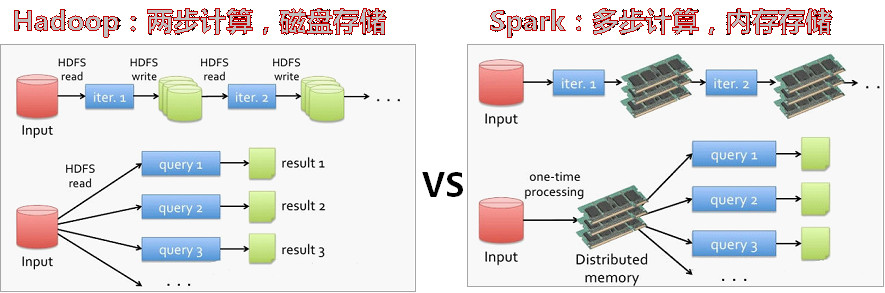
- Spark是一个针对超大数据集合的低延迟的集群分布式计算系统,比MapReducer快40倍左右。
- Spark是hadoop的升级版本,Hadoop作为第一代产品使用HDFS,第二代加入了Cache来保存中间计算结果,并能适时主动推Map/Reduce任务,第三代就是Spark倡导的流Streaming。
- Spark兼容Hadoop的APi,能够读写Hadoop的HDFS HBASE 顺序文件等。
容错
–基于血统的容错,数据恢复
–checkpoint

checkpoint是一个内部事件,这个事件激活以后会触发数据库写进程(DBWR)将数据缓冲(DATABUFFER CACHE)中的脏数据块写出到数据文件中。
在数据库系统中,写日志和写数据文件是数据库中IO消耗最大的两种操作,在这两种操作中写数据文件属于分散写,写日志文件是顺序写,因此为了保证数据库的性能,通常数据库都是保证在提交(commit)完成之前要先保证日志都被写入到日志文件中,而脏数据块则保存在数据缓存(buffer cache)中再不定期的分批写入到数据文件中。也就是说日志写入和提交操作是同步的,而数据写入和提交操作是不同步的。这样就存在一个问题,当一个数据库崩溃的时候并不能保证缓存里面的脏数据全部写入到数据文件中,这样在实例启动的时候就要使用日志文件进行恢复操作,将数据库恢复到崩溃之前的状态,保证数据的一致性。检查点是这个过程中的重要机制,通过它来确定,恢复时哪些重做日志应该被扫描并应用于恢复。
一般所说的checkpoint是一个数据库事件(event),checkpoint事件由checkpoint进程(LGWR/CKPT进程)发出,当checkpoint事件发生时DBWn会将脏块写入到磁盘中,同时数据文件和控制文件的文件头也会被更新以记录checkpoint信息。
SparkStreaming
什么是SparkStreaming:
Spark是一个类似于Hadoop的MapReduce分布式计算框架,其核心是弹性分布式数据集(RDD,一个在内存中的数据集合),提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。 Spark拥有Hadoop MapReduce所具有的优点;但不同于Hadoop MapReduce的是计算任务中间输出和结果可以保存在内存中,从而不再需要读写HDFS,节省了磁盘IO耗,号称性能比Hadoop快100倍。 Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。即SparkStreaming 是基于Spark的流式计算框架。
Spark Streaming的优势在于:
1、能运行在100+的结点上,并达到秒级延迟。
2、使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
3、能集成Spark的批处理和交互查询。
4、为实现复杂的算法提供和批处理类似的简单接口。
SparkStreaming原理

Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作。

大数据架构之:Spark的更多相关文章
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
随机推荐
- Linux Linux程序练习四
编写两个不同的可执行程序,名称分别为a和b,b为a的子进程. 在a程序中调用open函数打开a.txt文件. 在b程序不可以调用open或者fopen,只允许调用read函数来实现读取a.txt文件. ...
- Java中常见数据结构
1:集合 Collection(单列集合) List(有序,可重复) ArrayList 底层数据结构是数组,查询快,增删慢 线程不安全,效率高 Vector 底层数据结构是数组,查询快,增删慢 线程 ...
- android代码中自定义布局
转载地址:http://blog.csdn.net/luckyjda/article/details/8760214RelativeLayout rl = new RelativeLayout(thi ...
- 求伪逆矩阵c++代码(Eigen库)
非方阵的矩阵的逆矩阵 pseudoInverse 伪逆矩阵是逆矩阵的广义形式,广义逆矩阵 matlab中是pinv(A)-->inv(A). #include "stdafx.h&q ...
- 关于 js 动态生成html 绑定事件失效的问题
在实际问题中,也只到使用新版jq 的on 事件 进行动态元素的绑定: 是这样 (但是依然没有效果——): $('dom节点').on('click',function(){}) 之后经过查阅发现:正确 ...
- poj2420(模拟退火大法好)
// // main.cpp // poj2420 // // Created by 陈加寿 on 16/2/13. // Copyright © 2016年 chenhuan001. All rig ...
- ID生成策略
在电商项目中,图片名.商品ID都要唯一且方便存储,于是记录下这两个ID生成策略的方法,以便日后项目再有需要.具体代码如下 import java.util.Random; /** * 图片名生成 */ ...
- php-fpm 启动 关闭 进程逃逸 pid
正常关闭失败 [root@d personas]# /etc/init.d/php-fpm stopGracefully shutting down php-fpm /etc/init.d/php-f ...
- jquery拓展插件开发
学习参考网址整理: http://blog.csdn.net/chenxi1025/article/details/52222327 http://www.cnblogs.com/ellisonDon ...
- 控制台程序的中文输出乱码问题(export LC_CTYPE=zh_CN.GBK,或者修改/etc/sysconfig/i18n为zh_CN.GBK。使用setlocale(LC_CTYPE, "");会使用默认办法。编译器会将源码做转换成Unicode格式,或者指定gcc的输入文件的编码参数-finput-charset=GBK。Linux下应该用wprintf(L"%ls/n",wstr))
今天发现用securecrt登陆时,gcc编译出错时会出现乱码,但直接在主机的窗口界面下用Shell编译却没有乱码.查看了一下当时的错误描述,发现它的引号是中文引号,导致在SecureCRT中显示出错 ...