3、kafka工作流程
一、kafka各成员
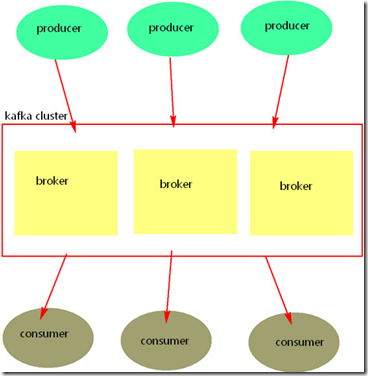
kafka:
分布式消息系统,将消息直接存入磁盘,默认保存一周。 broker:
组成kafka集群的节点,之间没有主从关系,依赖zookeeper来协调,broker负责满息的读写和存储,一个broker可以管理多个partition. producer:
消息的生产者,自己决定向哪个partition中去生产消息,两种机利:hash,轮循。 consumer:
消息的消费者,consumer通过zookeeper去维护消费者偏移量。consumer有自己的消费者组,不同的组之间消费同一个topic数据,互不影响,
相同的组内的不同的consumer消费同一个topic,这个topic中相同的数据只能被消费一次。 topic:
一类消息总称/一个消息队列。topic是由partition组成的,有多少?-> 创建指定。 partition:
组成topic的单元,每个partition有副本,有多少?-> 创建topic时指定。每个partition只能由一个broker来管理,这个broker就是这个partition的leader。 zookeeper:
协调kafka broker,存储原数据:consumer的offset+broker信息+topic信息+partition信息;
二、分析zookeeper元数据存储
1、创建topic
[root@spark1 bin]# pwd
/usr/local/kafka/bin #创建topic
[root@spark1 bin]# ./kafka-topics.sh --zookeeper spark1:2181,spark2,spark3 --create --topic t0425 --partitions 3 --replication-factor 3
Created topic "t0425". [root@spark1 bin]# ./kafka-topics.sh --zookeeper spark1:2181,spark2,spark3 --list |grep t0425
t0425
2、生产、消费
##生产者
[root@spark1 bin]# ./kafka-console-producer.sh --topic t0425 --broker-list spark1:9092,spark2:9092,spark3:9092
hello
world
1
2
3
... ##消费者
[root@spark1 bin]# ./kafka-console-consumer.sh --zookeeper spark1:2181,spark2:2181,spark3:2181 --topic t0425
hello
world
1
2
3
...
3、进入zookeeper查看
看topic
##连接zookeeper
[root@spark1 zk]# ./bin/zkCli.sh ##查看
[zk: localhost:2181(CONNECTED) 0] ls /
[consumers, config, controller, admin, brokers, zookeeper, controller_epoch] #brokers下有topics
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[topics, ids] #topics下有t0425,也就是刚才创建的topic
[zk: localhost:2181(CONNECTED) 2] ls /brokers/topics
[t0425, WordCount, TestTopic, WordCount1, first1] #t0425下有partitions
[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics/t0425
[partitions] [zk: localhost:2181(CONNECTED) 4] ls /brokers/topics/t0425/partitions
[2, 1, 0] [zk: localhost:2181(CONNECTED) 5] ls /brokers/topics/t0425/partitions/0
[state] [zk: localhost:2181(CONNECTED) 6] get /brokers/topics/t0425/partitions/0/state
{"controller_epoch":1,"leader":0,"version":1,"leader_epoch":0,"isr":[0,2,1]}
cZxid = 0x2000000ce
ctime = Fri Aug 23 10:06:02 CST 2019
mZxid = 0x2000000ce
mtime = Fri Aug 23 10:06:02 CST 2019
pZxid = 0x2000000ce
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 76
numChildren = 0
看consumer
[zk: localhost:2181(CONNECTED) 8] ls /consumers
[console-consumer-72909, DefaultConsumerGroup] [zk: localhost:2181(CONNECTED) 9] ls /consumers/console-consumer-72909
[offsets, owners, ids] [zk: localhost:2181(CONNECTED) 10] ls /consumers/console-consumer-72909/offsets
[t0425] #可看到有0 1 2
[zk: localhost:2181(CONNECTED) 11] ls /consumers/console-consumer-72909/offsets/t0425
[2, 1, 0] [zk: localhost:2181(CONNECTED) 12] ls /consumers/console-consumer-72909/offsets/t0425/0
[] #查看0
[zk: localhost:2181(CONNECTED) 13] get /consumers/console-consumer-72909/offsets/t0425/0
12 #这个12就是刚才生产消费的消息条数,都在0里面,1和2里面没有
cZxid = 0x2000000e7
ctime = Fri Aug 23 10:14:09 CST 2019
mZxid = 0x2000000e7
mtime = Fri Aug 23 10:14:09 CST 2019
pZxid = 0x2000000e7
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 2
numChildren = 0 ##现在接着去生产几条消息,然后再看0 1 2
[zk: localhost:2181(CONNECTED) 18] get /consumers/console-consumer-72909/offsets/t0425/2
6 #这个6就是刚才新生产消费的消息条数
cZxid = 0x2000000ea
ctime = Fri Aug 23 10:14:09 CST 2019
mZxid = 0x2000000ef
mtime = Fri Aug 23 10:33:09 CST 2019
pZxid = 0x2000000ea
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 1
numChildren = 0 结论:生产消息时,每隔10分钟会random一次partition,也就是隔10就随机选一次partition
三、leader 均衡机制
[root@spark1 bin]# ./kafka-topics.sh --zookeeper spark1:2181,spark2,spark3 --describe --topic t0425
Topic:t0425 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: t0425 Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: t0425 Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: t0425 Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0 ##
PartitionCount:3 //分区数
ReplicationFactor:3 //副本数 ##0号partition归0号leader管理,Replicas:副本位于哪些节点上,lsr:启动集群时,去哪些节点检查数据完整性
Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0 ##均衡机制
一个Partition只能归一个leader管,但一个leader可以有多个Partition;
当一个leader挂了,Partition会依赖副本优先机制,重新寻找一个leader; ##副本优先机制
如Partition:0 ->Partition: 0 Leader: 0 Replicas: 0,2,1
partition0的副本位于Replicas: 0,2,1 ,也就是顺序为0 2 1,所以它就会按这个循序找leader; ##再均衡
当把挂掉的leader主机,重新起来以后,kafka会自动释放掉partition后来寻找的那个leader,重新恢复成原来的模样;
四、Kafka生产过程分析
1、写入方式
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)
2、partition(分区)
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成; 每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值; 分区的原因:
方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了; 可以提高并发,因为可以以Partition为单位读写了; 分区的原则:
指定了patition,则直接使用; 未指定patition但指定key,通过对key的value进行hash出一个patition; patition和key都未指定,使用轮询选出一个patition;
3、Replication(副本 )
同一个partition可能会有多个replication(对应 server.properties 配置中的 default.replication.factor=N N是一个数字)。没有replication的情况下,一旦broker 宕机,
其上所有 patition 的数据都不可被消费,同时producer也不能再将数据存于其上的patition。引入replication之后,同一个partition可能会有多个replication,
而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据;
4、写入流程
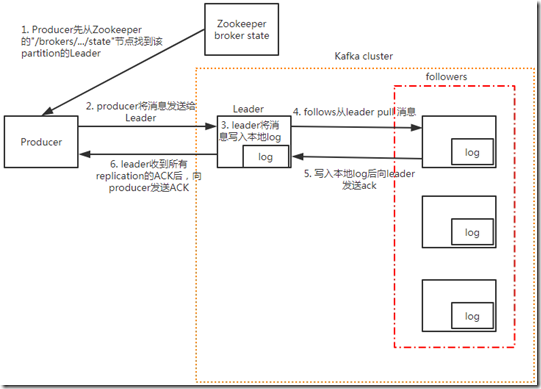
1、producer先从zookeeper的 "/brokers/.../state"节点找到该partition的leader
2、producer将消息发送给该leader
3、leader将消息写入本地log
4、followers从leader pull消息
5、写入本地log后向leader发送ACK
6、leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit 的offset)并向producer发送ACK
5、broker消息存储
##存储方式
物理上把topic分成一个或多个patition(对应 server.properties 中的num.partitions=N配置,N是一个数字),
每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件),如下: [root@spark1 bin]# ./kafka-topics.sh --zookeeper spark1:2181,spark2,spark3 --create --topic t0425 --partitions 3 --replication-factor 3 [root@spark1 kafka-logs]# ls |grep t0425 #在kafka的数据目录中
t0425-0
t0425-1
t0425-2 [root@spark1 kafka-logs]# ll t0425-0
总用量 0
-rw-r--r-- 1 root root 10485760 8月 23 11:41 00000000000000000000.index
-rw-r--r-- 1 root root 0 8月 23 11:41 00000000000000000000.log [root@spark1 kafka-logs]# ll t0425-1
总用量 0
-rw-r--r-- 1 root root 10485760 8月 23 11:41 00000000000000000000.index
-rw-r--r-- 1 root root 0 8月 23 11:41 00000000000000000000.log [root@spark1 kafka-logs]# ll t0425-2
总用量 0
-rw-r--r-- 1 root root 10485760 8月 23 11:41 00000000000000000000.index
-rw-r--r-- 1 root root 0 8月 23 11:41 00000000000000000000.log ##存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据 基于时间:log.retention.hours=168
基于大小:log.retention.bytes=1073741824 需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关;
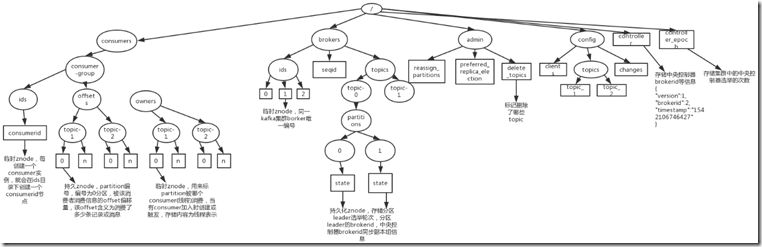
6、zookeeper存储结构
五、Kafka消费过程分析
kafka提供了两套consumer API,高级Consumer API和低级Consumer API
1、高级API
高级API优点:
高级API 写起来简单
不需要自行去管理offset,系统通过zookeeper自行管理
不需要管理分区,副本等情况,.系统自动管理
消费者断线会自动根据上一次记录在zookeeper中的offset去接着获取数据(默认设置1分钟更新一下zookeeper中存的offset)
可以使用group来区分对同一个topic 的不同程序访问分离开来(不同的group记录不同的offset,这样不同程序读取同一个topic才不会因为offset互相影响) 高级API缺点:
不能自行控制offset(对于某些特殊需求来说)
不能细化控制如分区、副本、zk等,不关心数据会不会丢失。
2、低级API
低级 API 优点
能够让开发者自己控制offset,想从哪里读取就从哪里读取。
自行控制连接分区,对分区自定义进行负载均衡
对zookeeper的依赖性降低(如:offset不一定非要靠zk存储,自行存储offset即可,比如存在文件或者内存中)
低级API缺点
太过复杂,需要自行控制offset,连接哪个分区,找到分区leader 等
3、消费者组
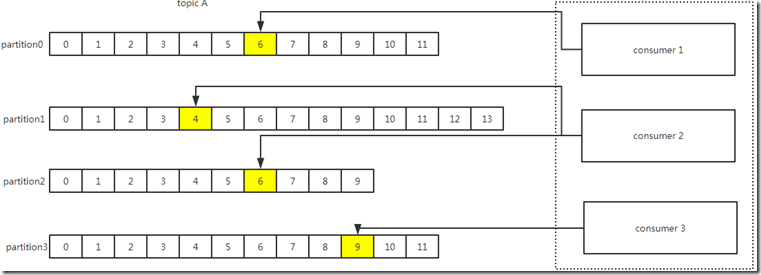
消费者是以consumer group消费者组的方式工作,由一个或者多个消费者组成一个组,共同消费一个topic。每个分区在同一时间只能由group中的一个消费者读取,
但是多个group可以同时消费这个partition。在上图中,有一个由三个消费者组成的group,有一个消费者读取主题中的两个分区,另外两个分别读取一个分区。
某个消费者读取某个分区,也可以叫做某个消费者是某个分区的拥有者。 在这种情况下,消费者可通过水平扩展的方式同时读取大量的消息。另外,如果一个消费者失败了,那么其他的group成员会自动负载均衡读取之前失败的消费者读取的分区;
4、消费方式
consumer采用pull(拉)模式从broker中读取数据。 push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及
处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。 对于Kafka而言,pull模式更合适,它可简化broker的设计,consumer可自主控制消费消息的速率,同时consumer可以自己控制消费方式——即可批量消费也可逐条消费,
同时还能选择不同的提交方式从而实现不同的传输语义。 pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直等待数据到达。为了避免这种情况,我们在我们的拉请求中有参数,允许消费者请求在等待
数据到达的“长轮询”中进行阻塞(并且可选地等待到给定的字节数,以确保大的传输大小);
3、kafka工作流程的更多相关文章
- Kafka工作流程分析
Kafka工作流程分析 生产过程分析 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘 ...
- Apache Kafka工作流程| Kafka Pub-Sub Messaging
1.目标 在我们上一篇Kafka教程中,我们讨论了Kafka Docker.今天,我们将讨论Kafka Workflow.此外,我们将详细介绍Pub-Sub Messaging的工作流程以及Queue ...
- Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程: 每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性. Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的 ...
- kafka工作流程| 命令行操作
1. 概述 数据层:结构化数据+非结构化数据+日志信息(大部分为结构化) 传输层:flume(采集日志--->存储性框架(如HDFS.kafka.Hive.Hbase))+sqoop(关系型数 ...
- Kafka工作流程
Kafka生产过程分析 1 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机 ...
- kafka学习(二)kafka工作流程分析
一.发送数据 follower的同步流程 PS:Producer在写入数据的时候永远的找leader,不会直接将数据写入follower PS:消息写入leader后,follower是主动的去lea ...
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka(分布式发布-订阅消息系统)工作流程说明
Kafka系统架构Apache Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和 ...
- Kafka之工作流程分析
Kafka之工作流程分析 kafka核心组成 一.Kafka生产过程分析 1.1 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(pa ...
随机推荐
- 全栈项目|小书架|服务器端-NodeJS+Koa2实现首页图书列表接口
通过上篇文章 全栈项目|小书架|微信小程序-首页水平轮播实现 我们实现了前端(小程序)效果图的展示,这篇文章来介绍服务器端的实现. 首页书籍信息 先来回顾一下首页书籍都有哪些信息: 从下面的图片可以看 ...
- MOOC 数据库笔记(三):关系模型之基本概念
关系模型的基本概念 关系模型简述 1.最早由E.F.Codd在1970年提出. 2.是从表(Table)及表的处理方式中抽象出来的,是在对传统表及其操作进行数学化严格定义的基础上,引入集合理论与逻辑学 ...
- mysql 8.0.17 安装与使用
目录 写在前面 MySQL 安装 重置密码 使用图形界面软件 Navicat for SQL 写在前面 以前包括现在接到的项目,用的最多的关系型数据库就是SqlServer或者Oracle.后来因为接 ...
- 1 matplotlib绘制折线图
from matplotlib import pyplot as plt #设置图形大小 plt.figure(figsize=(20,8),dpi=80) plt.plot(x,y,color=&q ...
- 设置断点调式 fiddler
1. 用IE 打开博客园的登录界面 http://passport.cnblogs.com/login.aspx 2. 打开Fiddler, 在命令行中输入bpu http://passport. ...
- margin 外边距合并问题
一.兄弟元素的外边距合并 效果图如下:(二者之间的间距为100px,不是150px) 二.嵌套元素的外边距合并 对于两个嵌套关系的元素,如果父元素中没有内容或者内容在子元素的后面并且没有上内边距及边框 ...
- js 取得数组中的最大值和最小值(含多维数组)
转自:http://www.dewen.org/q/433 方法一: var a=[1,2,3,5]; alert(Math.max.apply(null, a));//最大值 alert(Math. ...
- Spring+Velocity+Mybatis入门(step by step)
一.开发工具 开发过程中使用的操作系统是OS X,关于软件安装的问题请大家移步高效的Mac环境设置. 本文是我对自己学习过程的一个回顾,应该还有不少问题待改进,例如目录的设置.编码习惯和配置文件的处理 ...
- redis设置远程连接
1.修改redis服务器的配置文件 本机安装的redis-4.0.14默认的配置文件 redis.conf 设置 绑定本机地址:bind 127.0.0.1 开启保护模式:protected-mode ...
- python assert 在正式产品里禁用的手法 直接-O即可
How do I disable assertions in Python? There are multiple approaches that affect a single process, t ...