python+selenium实现自动化百度搜索关键词
通过python配合爬虫接口利用selenium实现自动化打开chrome浏览器,进行百度关键词搜索。
1、安装python3,访问官网选择对应的版本安装即可,最新版为3.7。
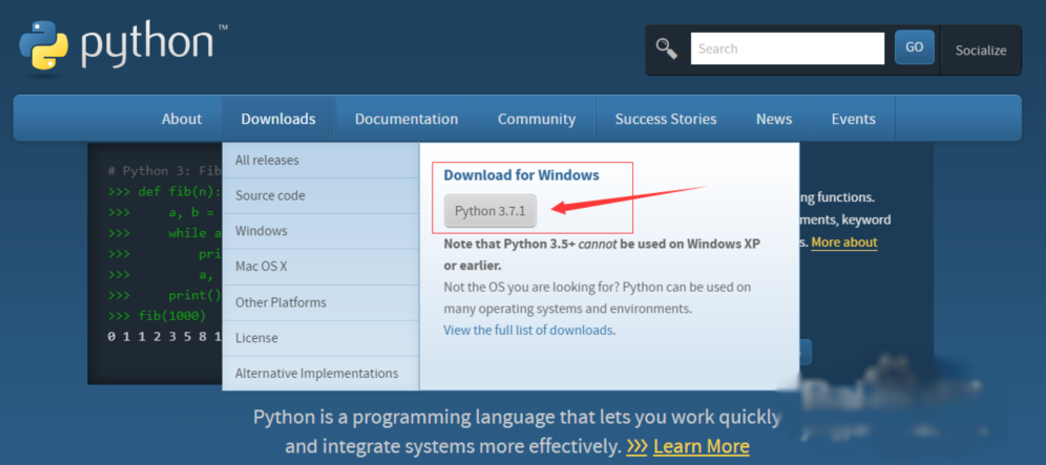
2、安装selenium库。
使用 pip install selenium 安装即可。
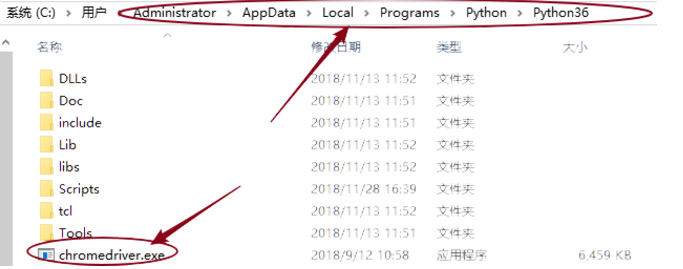
同时需要安装chromedriver,并放在python安装文件夹下,如下图所示。
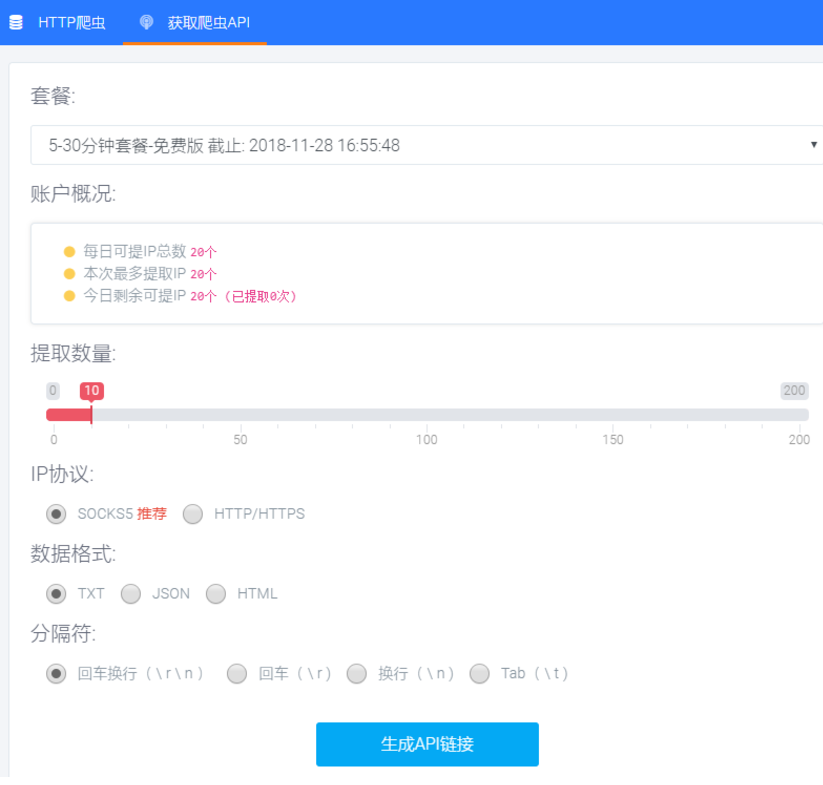
3、获取爬虫接口链接。
注册账号,点击爬虫代理,领取每日试用。
from selenium import webdriver
import requests,time
#自建IP池
def get_proxy():
r = requests.get('http://127.0.0.1:5555/random')
return r.text
import random
FILE = './tuziip.txt'
# 读取的txt文件路径
# 获取代理IP
def proxy_ip():
ip_list = []
with open(FILE, 'r') as f:
while True:
line = f.readline()
if not line:
break
ip_list.append(line.strip())
ip_port = random.choice(ip_list)
return ip_port
def bd():
chromeOptions = webdriver.ChromeOptions()
# 设置代理
chromeOptions.add_argument("--proxy-server=http://"+proxy_ip())
# 一定要注意,=两边不能有空格,不能是这样--proxy-server = http://202.20.16.82:10152
browser = webdriver.Chrome(chrome_options = chromeOptions)
# 查看本机ip,查看代理是否起作用
browser.get("https://www.baidu.com/")
browser.find_element_by_id("kw").send_keys("ip")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.find_element_by_id("kw").send_keys("百度")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.find_element_by_id("kw").send_keys("百度")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.close()
# 退出,清除浏览器缓存
browser.quit()
if __name__ == "__main__":
while True:
bd()
5、运行程序,如下图所示,可自动化搜索。

python+selenium实现自动化百度搜索关键词的更多相关文章
- python使用get在百度搜索并保存第一页搜索结果
python使用get在百度搜索并保存第一页搜索结果 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用在意我的感受 #coding:utf-8 import ur ...
- 使用python和selenium写一个百度搜索的case
今天练习的内容主要写了一个小功能,在百度上搜索某词汇,然后实现web上的back功能 代码如下: import unittest from selenium import webdriver from ...
- 使用python selenium进行自动化functional test
Why Automation Testing 现在似乎大家都一致认同一个项目应该有足够多的测试来保证功能的正常运作,而且这些此处的‘测试’特指自动化测试:并且大多数人会认为如果还有哪个项目依然采用人工 ...
- C#+Selenium抓取百度搜索结果前100网址
需求 爬取百度搜索某个关键字对应的前一百个网址. 实现方式 VS2017 + Chrome .NET Framework + C# + Selenium(浏览器自动化测试框架) 环境准备 创建控制台应 ...
- js 获取百度搜索关键词的代码
有可能有时候我们会用到在百度搜什么关键词进来我们的网站的,所有我们又想拿到用户搜索的关键词. 这是我研究了半天所得出的办法.话不多说直接贴代码 <script> function quer ...
- python selenium - web自动化环境搭建
前提: 安装python环境. 参考另一篇博文:https://www.cnblogs.com/Simple-Small/p/9179061.html web自动化:实现代码驱动浏览器进行点点点的操作 ...
- python selenium与自动化
大学是学习过java,但是工作中没用,忘完了,而且哪怕以后有了机会,就是很不愿意去学这个语言,开始喜欢上了c#,但是随着学的升入,感觉.net太庞大了,要学习那么多,总感觉我学这个要做什么,感觉要做的 ...
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- python+selenium简易自动化框架,包含生成测试报告以及发送结果至Email
Selenium+python环境搭建见虫师的pdf文档,非常详尽 简易框架: 1.文件目录:
随机推荐
- Python爬虫 | Selenium详解
一.简介 网页三元素: html负责内容: css负责样式: JavaScript负责动作; 从数据的角度考虑,网页上呈现出来的数据的来源: html文件 ajax接口 javascript加载 如果 ...
- JS对象创建模式
JS的对象创建模式 1.Object构造函数模式 var person = new Object(); person.name = 'name'; person.age = 43; console.l ...
- json-server模拟服务器API
一.npm安装 npm install --global json-server 二.使用:创建一个json数据文件,比如: { "students": [{ "id&q ...
- APIO2019 游记
\(\text {Cu}\)滚粗了,滚粗选手不配拥有游记.
- ssl 原理简介
要想弄明白SSL认证原理,首先要对CA有有所了解,它在SSL认证过程中有非常重要的作用.说白了,CA就是一个组织,专门为网络服务器颁发证书的,国际知名的CA机构有VeriSign.Symantec,国 ...
- Watcher监听
可以设置观察的操作:exists,getChildren,getData 可以触发观察的操作:create,delete,setData zookeeper观察机制; 服务端只存储事件的信息,客户 ...
- Django 数据库与ORM
一.数据库的配置 1 django默认支持sqlite,mysql, oracle,postgresql数据库. <1> sqlite django默认使用sqlite的数据库,默认自带 ...
- 咏南跨平台中间件REST API
主旨 1)为了中间件支持跨操作系统部署,客户端支持跨操作系统.跨设备.跨开发语言,特制订本REST API规约. 2)所有接口均支持HTTP GET\POST调用. 3)调用示例为DELPHI代码,其 ...
- 比特币场外otc交流群908389290
比特币场外otc交流群908389290,欢迎加入交流讨论-
- IDEA强制清除Maven缓存
目录 重新导入依赖的常见方式 存在的问题 彻底清除IDEA缓存的方式 重新导入依赖的常见方式 下面图中的刷新按钮,在我的机器上,并不能每次都正确导入pom.xml中写的依赖项,而是导入之前pom.xm ...