python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本。
工具:python3.7+selenium+任意一款编辑器
前期准备:可以正常使用的浏览器,这里推荐chrome,一个与浏览器同版本的驱动,这里提供一个下载驱动的链接https://chromedriver.storage.googleapis.com/77.0.3865.40/chromedriver_win32.zip
首先我们来看一下百度文库中这一篇文章https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html
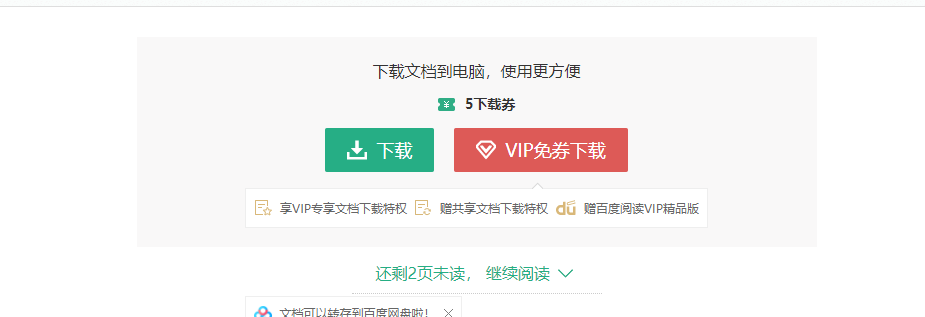
可以看到,在文章的最末尾需要我们来点击继续阅读才能爬取到所有的文字,不然我们只能获取到一部分的文字。这给我们的爬虫带来了一些困扰。因此,我们需要借助selenium这一个自动化工具来帮助我们的程序完成这一操作。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
import re
driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
我们先通过驱动器来请求这个页面,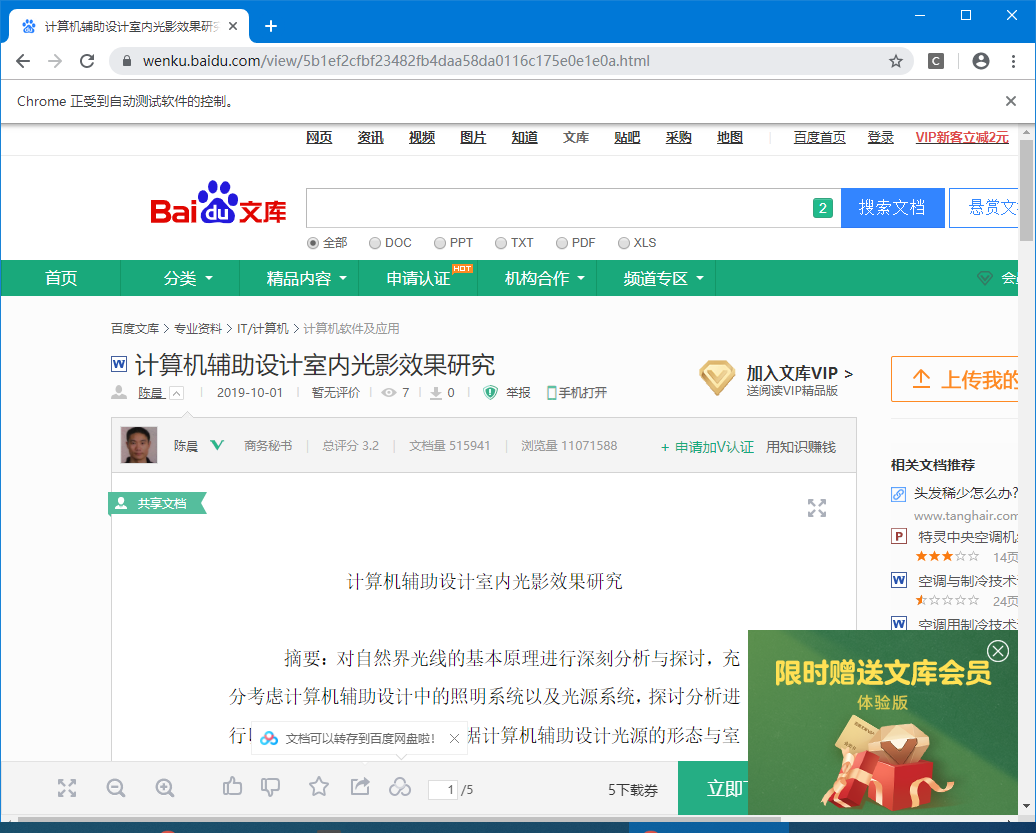
可以看到,已经请求成功这个页面了。接下来需要我们通过驱动来点击继续阅读来加载到这篇文章的所有文字。我们通过f12审查元素,看看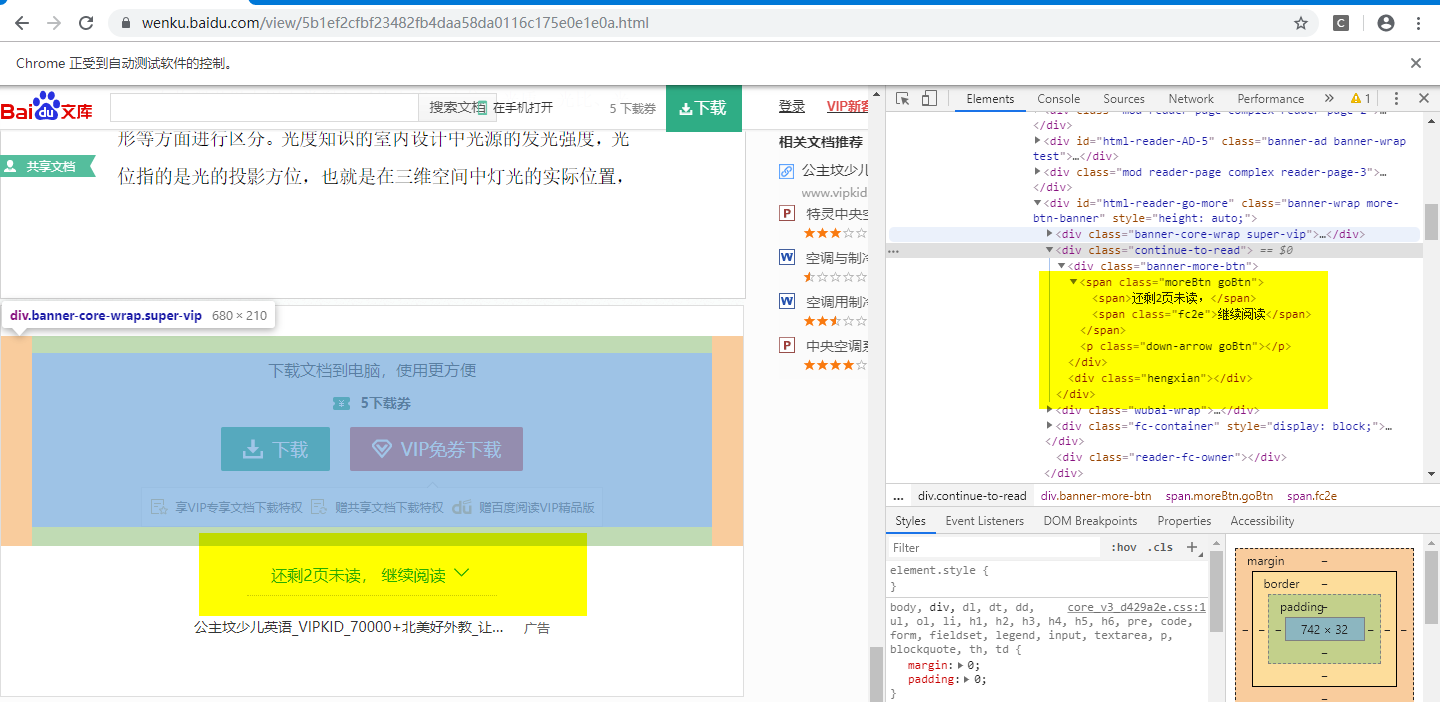
然后通过selenium的定位功能,定位到左边黄色区域所在的位置,调用驱动器进行点击
driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
然后执行看看
 黄字是报错的信息,显示的是有另外一个元素接受了点击的调用。可能是屏幕没有滑动到下方,直接点击被遮盖了。所以我们要通过驱动器先将浏览器滑动到底部,再点击继续阅读
黄字是报错的信息,显示的是有另外一个元素接受了点击的调用。可能是屏幕没有滑动到下方,直接点击被遮盖了。所以我们要通过驱动器先将浏览器滑动到底部,再点击继续阅读
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
import re
driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
page=driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p")
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去
page=driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
先获取到继续阅读所在页面的位置,然后使用
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去方法将页面滚动到可以点击的位置
这样就获取到了整个完整页面,在使用beautifulsoup进行解析
html=driver.page_source
bf1 = BeautifulSoup(html, 'lxml')
result=bf1.find_all(class_='page-count')
num=BeautifulSoup(str(result),'lxml').span.string
count=eval(repr(num).replace('/', ''))
page_count=int(count)
for i in range(1,page_count+1):
result=bf1.find_all(id="pageNo-%d"%(i))
for each_result in result:
bf2 = BeautifulSoup(str(each_result), 'lxml')
texts = bf2.find_all('p')
for each_text in texts:
main_body = BeautifulSoup(str(each_text), 'lxml')
s=main_body.get_text()
最后在写入txt文档
f=open("baiduwenku.txt","a",encoding="utf-8")
f.write(s)
f.flush()
f.close()
python+selenium爬取百度文库不能下载的word文档的更多相关文章
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html 在下面这种类型文件中的请求头的url打开后会得到一个页面 你会得到如下图 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- ubuntu手动升级系统
之前自己安装的是ubuntu14.04,现在需要升级到16.04,于是上网搜索了一下升级步骤以及相关命令,将这些整理出来分享给大家,希望能够给大家提供帮助. 1.更新资源: sudo apt-get ...
- 洛谷$P1390$ 公约数的和 欧拉函数
正解:欧拉函数 解题报告: 传送门$QwQ$ 首先显然十分套路地变下形是趴 $\begin{align*}&=\sum_{i=1}^n\sum_{j=1}^n gcd(i,j)\\&= ...
- Markdown数学符号
上标 语法: x^2 效果: \(x^2\) 下标 语法: x_i 效果: \(x_i\) 整体 语法: x^{2y} 效果: \(x^{2y}\) 大括号 语法: \{\} 效果: \(\{\}\) ...
- 「洛谷P1231」教辅的组成 解题报告
P1231 教辅的组成 题目背景 滚粗了的HansBug在收拾旧语文书,然而他发现了什么奇妙的东西. 题目描述 蒟蒻HansBug在一本语文书里面发现了一本答案,然而他却明明记得这书应该还包含一份练习 ...
- 「Vijos 1283」「OIBH杯NOIP2006第二次模拟赛」佳佳的魔杖
佳佳的魔杖 背景 配制成功了珍贵的0号药水,MM的病治好了.轻松下来的佳佳意外的得到了一个好东西--那就是--一种非常珍贵的树枝.这些树枝可以用来做优质的魔杖!当然了,不能只做自己的,至少还要考虑到M ...
- 钱包开发经验分享:ETH篇
# 钱包开发经验分享:ETH篇 [TOC] ## 开发前的准备 > 工欲善其事,必先利其器 一路开发过来,积累了一些钱包的开发利器和网站,与大家分享一下.这些东西在这行开发过的人都知道,只是给行 ...
- Linux 查看实时网卡流量的方法 sar nload iftop
1.sar 计量脚本 sar(System Activity Reporter 系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读 ...
- Redis入门--1.安装Redis
redis是什么? 是完全开源免费的,用c语言编写的,是一个单线程,高性能的(key/value)内存数据库,基于内存运行并支持持久化的nosql数据库 redis能干嘛? 主要是用来做缓存,但不仅仅 ...
- HashMap 源码赏析 JDK8
一.简介 HashMap源码看过无数遍了,但是总是忘,好记性不如烂笔头. 本文HashMap源码基于JDK8. 文章将全面介绍HashMap的源码及HashMap存在的诸多问题. 开局一张图,先来看看 ...
- GDAl C++ 创建Shp
用于GDAL,C++开发环境测试. #include <iostream> #include "gdal_priv.h" #include "ogrsf_fr ...