python+selenium实现自动化百度搜索关键词
通过python配合爬虫接口利用selenium实现自动化打开chrome浏览器,进行百度关键词搜索。
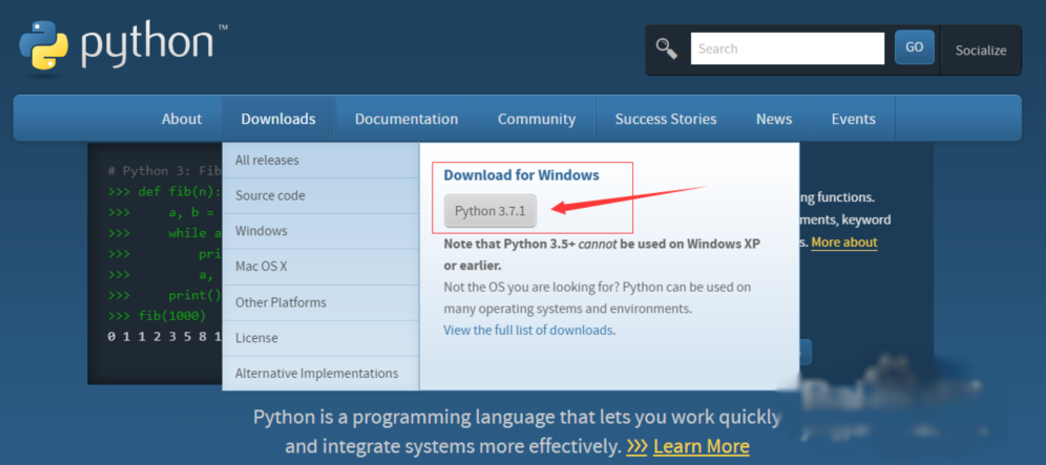
1、安装python3,访问官网选择对应的版本安装即可,最新版为3.7。
2、安装selenium库。
使用 pip install selenium 安装即可。
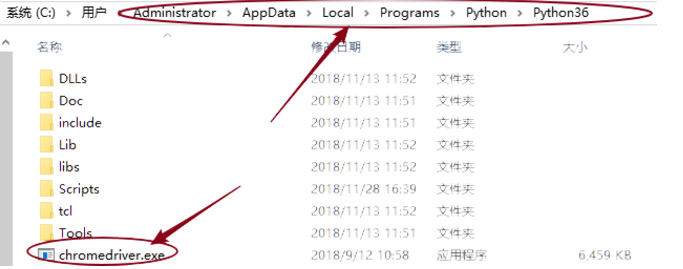
同时需要安装chromedriver,并放在python安装文件夹下,如下图所示。
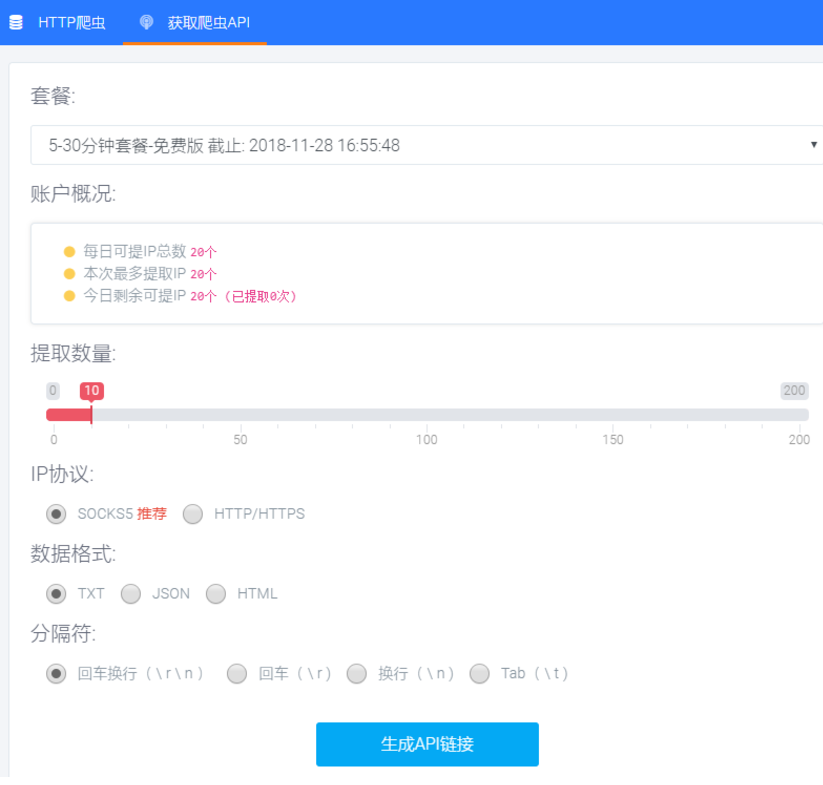
3、获取爬虫接口链接。
注册账号,点击爬虫代理,领取每日试用。
from selenium import webdriver
import requests,time
#自建IP池
def get_proxy():
r = requests.get('http://127.0.0.1:5555/random')
return r.text
import random
FILE = './tuziip.txt'
# 读取的txt文件路径
# 获取代理IP
def proxy_ip():
ip_list = []
with open(FILE, 'r') as f:
while True:
line = f.readline()
if not line:
break
ip_list.append(line.strip())
ip_port = random.choice(ip_list)
return ip_port
def bd():
chromeOptions = webdriver.ChromeOptions()
# 设置代理
chromeOptions.add_argument("--proxy-server=http://"+proxy_ip())
# 一定要注意,=两边不能有空格,不能是这样--proxy-server = http://202.20.16.82:10152
browser = webdriver.Chrome(chrome_options = chromeOptions)
# 查看本机ip,查看代理是否起作用
browser.get("https://www.baidu.com/")
browser.find_element_by_id("kw").send_keys("ip")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.find_element_by_id("kw").send_keys("百度")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.find_element_by_id("kw").send_keys("百度")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.close()
# 退出,清除浏览器缓存
browser.quit()
if __name__ == "__main__":
while True:
bd()
5、运行程序,如下图所示,可自动化搜索。

python+selenium实现自动化百度搜索关键词的更多相关文章
- python使用get在百度搜索并保存第一页搜索结果
python使用get在百度搜索并保存第一页搜索结果 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用在意我的感受 #coding:utf-8 import ur ...
- 使用python和selenium写一个百度搜索的case
今天练习的内容主要写了一个小功能,在百度上搜索某词汇,然后实现web上的back功能 代码如下: import unittest from selenium import webdriver from ...
- 使用python selenium进行自动化functional test
Why Automation Testing 现在似乎大家都一致认同一个项目应该有足够多的测试来保证功能的正常运作,而且这些此处的‘测试’特指自动化测试:并且大多数人会认为如果还有哪个项目依然采用人工 ...
- C#+Selenium抓取百度搜索结果前100网址
需求 爬取百度搜索某个关键字对应的前一百个网址. 实现方式 VS2017 + Chrome .NET Framework + C# + Selenium(浏览器自动化测试框架) 环境准备 创建控制台应 ...
- js 获取百度搜索关键词的代码
有可能有时候我们会用到在百度搜什么关键词进来我们的网站的,所有我们又想拿到用户搜索的关键词. 这是我研究了半天所得出的办法.话不多说直接贴代码 <script> function quer ...
- python selenium - web自动化环境搭建
前提: 安装python环境. 参考另一篇博文:https://www.cnblogs.com/Simple-Small/p/9179061.html web自动化:实现代码驱动浏览器进行点点点的操作 ...
- python selenium与自动化
大学是学习过java,但是工作中没用,忘完了,而且哪怕以后有了机会,就是很不愿意去学这个语言,开始喜欢上了c#,但是随着学的升入,感觉.net太庞大了,要学习那么多,总感觉我学这个要做什么,感觉要做的 ...
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- python+selenium简易自动化框架,包含生成测试报告以及发送结果至Email
Selenium+python环境搭建见虫师的pdf文档,非常详尽 简易框架: 1.文件目录:
随机推荐
- yugabyte 安装pg extention
前段时间在学习yugabyte 发现yugabyte 是直接复用了pg server的源码,所以当时就觉得大部分pg extension 也是可用. 今天看到了官方文档中有关于如何安装的,发现还得多看 ...
- ESA2GJK1DH1K微信小程序篇: 安装Nginx,配置反向代理
前言 一,为什么需要反向代理 小程序访问的是 443端口,咱需要把443端口的数据传给MQTT 这节为了避免大家配置出错,以下源码已经配置. 如果大家想自己配置,请参考 https://www.cnb ...
- 字符串Hash学习笔记
[toc] # 以下内容作废,太多错误了,等我有时间重写 说一下什么是Hash,说白了就是把一大坨字符用一些神奇的数来表示,可以说是把字符加密了. 简单一点就是一个像函数一样的东西,你放进去一个值,它 ...
- 责任链模式(chainOfResponsibility)
参考文章:http://wiki.jikexueyuan.com/project/design-pattern-behavior/chain-four.html 定义: 使多个对象都有机会处理请求,从 ...
- pyqt(day1)
参考代码地址:https://github.com/cxinping/Pyqt5 pyqt在线帮助文档:https://www.riverbankcomputing.com/static/Docs/P ...
- 堆叠注入——BUUCTF-随便注
由题目提示知道,这题需要进行sql注入 输入1'发现报错 再输入1';show batabases#出现了一大堆数据库 再输入1';show tables#出现了两个表 猜测flag在这2个表中,输入 ...
- xml报文标签替换正则表达式
写在前面 需求是把所有标签中的信息替换成指定内容 例如: <transName>交易名称</transName><aaa></aaaa><tran ...
- NIO通信中connect()方法和finishConnect()方法的区别
1.对于阻塞模式下,调用connect()进行连接操作时,会一直阻塞到连接建立完成(无连接异常的情况下).所以可以不用finishConnect来确认. 2.但在非阻塞模式下,connect()操作是 ...
- Spring @RequestMapping 参数说明
@RequestMapping 参数说明: value: 指定请求的实际地址, 比如 /action/info之类.method: 指定请求的method类型, GET.POST.PUT.DELE ...
- sigmoid与softmax 二分类、多分类的使用
二分类下,sigmoid.softmax两者的数学公式是等价的,理论上应该是一样的,但实际使用的时候还是sigmoid好 https://www.zhihu.com/question/29524708 ...