Union-Find 并查集算法
一、动态连通性(Dynamic Connectivity)
Union-Find 算法(中文称并查集算法)是解决动态连通性(Dynamic Conectivity)问题的一种算法。动态连通性是计算机图论中的一种数据结构,动态维护图结构中相连信息。简单的说就是,图中各个节点之间是否相连、如何将两个节点连接,连接后还剩多少个连通分量。有点像我们的微信朋友圈,在社交网络中,彼此熟悉的人之间组成自己的圈子,熟悉之后就会添加好友,加入新的圈子。微信用户有几亿人,如何快速计算任意两个用户是否同属于一个圈子呢?计算机是如何将两个用户连接起来的呢?整个微信用户共有几个独立的圈子呢?Union-Find就可以解决上述问题。
结合下面图的例子来了解基本概念:
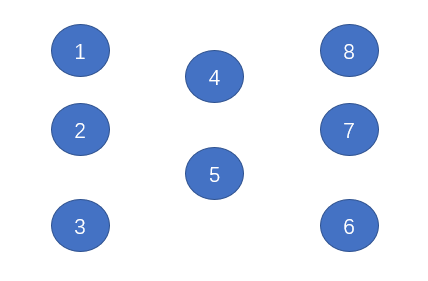
连通是一种等价关系,也就是说具有如下三个性质:
1、自反性:节点p和p是连通的。
2、对称性:如果节点p和q连通,那么q和p也连通。
3、传递性:如果节点p和q连通,q和r连通,那么p和r也连通。
class UF:
def __init__(self,N): #N表示初始化的节点数,也即最初的连通分量数
def union(self,p,q): # 将节点p和q进行连接
def connected(self,p,q): #判断p和q是否连接
def count(): #返回当前的连通分量
除了社交网络中的朋友圈计算,还可以判断编译器同一个变量的不同引用。
Union-Find 算法的关键就在于union和connected函数的效率。使用什么样的数据结构来实现这种高效率呢?
三、解决思路
用树来表示节点直接的连接,只要是连接的节点都在同一颗树中,多棵树就是多个连通分量,进而组成了整个森林。怎么用森林来表示连通性呢?我们设定树的每个节点都有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。
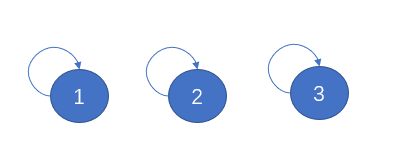
如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上,这样,如果节点p和q连通的话,它们一定拥有相同的根节点:
class UF:
def __init__(self,N): #N表示初始化的节点数,也即最初的连通分量数
self.count=N
self.root=[0] #root表示存储每个节点的根节点,第一个位置用0占位
for i in range(1,N+1): #初始化每个节点的根节点指向自己
self.root.append(i) def union(self,p,q): # 将节点p和q进行连接,让p的根节点指向q节点的根节点即可
if self.connected(p,q):
return;
p_root=self.find(p)
q_root=self.find(q)
self.root[p_root]=q_root
self.count-=1 def find(self,p): #查找节点p的根节点
while p!=self.root[p]:
p=self.root[p]
return p def connected(self,p,q): #判断p和q是否连接
return self.find(p)=self.find(q) def count(): #返回当前的连通分量
return self.count
算法效率分析:
从上述代码可以看出,union-find算法的效率主要在于find函数上面,因为union和connected两个函数的关键都在查找根节点上面,即find函数。find主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是logN,但这并不一定。logN的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得树几乎退化成直线链表,树的高度最坏情况下可能变成N,如下图所示:
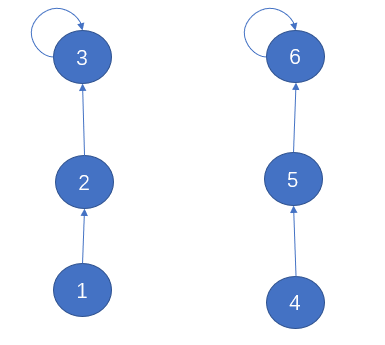
如果按照上面的情况,左边圈子与右边圈子进行连接的话,每个圈子找到根节点的时间复杂度都是O(N)级别的,对于诸如社交网络这样数据规模巨大的问题,而union和connected的调用都非常频繁,每次都需要线性时间复杂度,效率就显得比较低下了。其实这个问题就是树不平衡造成的。
四、平衡树
class UF:
def __init__(self,N): #N表示初始化的节点数,也即最初的连通分量数
self.count=N
self.root=[0] #root表示存储每个节点的根节点,第一个位置用0占位
self.size=[0]
for i in range(1,N+1): #初始化每个节点的根节点指向自己,树的大小为1
self.root.append(i)
self.size.append(1) def union(self,p,q): # 将节点p和q进行连接,让p的根节点指向q节点的根节点即可
if self.connected(p,q):
return;
p_root=self.find(p)
q_root=self.find(q)
if size[p_root]<= size[q_root]:
self.root[p_root]=q_root
self.size[q_root]+=self.size[p_root] #p节点数合并到q根节点上
else:
self.root[q_root]=self.root[p_root]
self.size[p_root]=self.size[p_root] #q节点数合并到p根节点上
self.count-=1 def find(self,p): #查找节点p的根节点
while p!=self.root[p]:
p=self.root[p]
return p def connected(self,p,q): #判断p和q是否连接
return self.find(p)=self.find(q) def count(): #返回当前的连通分量
return self.count
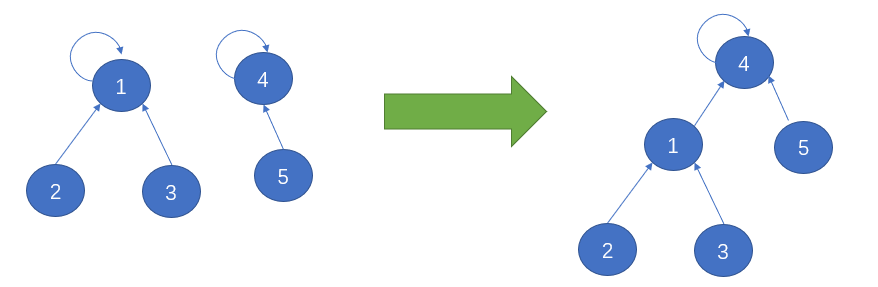
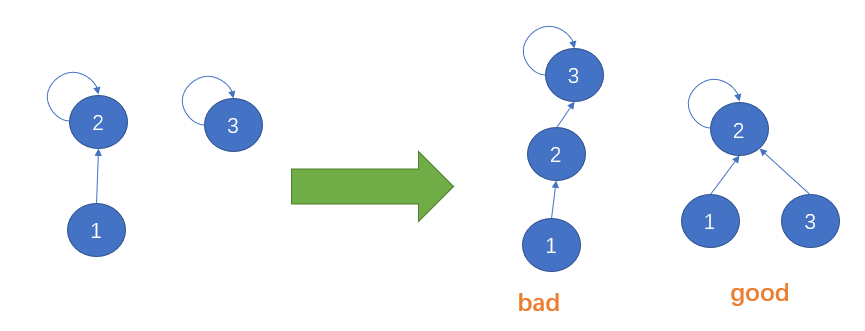
五、路径压缩(进一步优化find函数)
是不是可以进一步压缩树的高度,加快find函数的查找速度,find的效率提升了,等于union和connected函数效率提升了。

如果是上图这种形式,那查找速度基本就是O(1)级别了。但是一个平衡树一步是不可能压缩到这种形式,可以在find函数中加上一行代码,在每次查找的时候,就可以顺便压缩了路径,将树的高度进一步降低,代码如下:
class UF:
def __init__(self,N): #N表示初始化的节点数,也即最初的连通分量数
self.count=N
self.root=[0] #root表示存储每个节点的根节点,第一个位置用0占位
self.size=[0]
for i in range(1,N+1): #初始化每个节点的根节点指向自己,树的大小为1
self.root.append(i)
self.size.append(1) def union(self,p,q): # 将节点p和q进行连接,让p的根节点指向q节点的根节点即可
p_root=self.find(p)
q_root=self.find(q)
if p_root==q_root:
return
if self.size[p_root]<= self.size[q_root]:
self.root[p_root]=q_root
self.size[q_root]+=self.size[p_root] #p节点数合并到q根节点上
else:
self.root[q_root]=self.root[p_root]
self.size[p_root]=self.size[p_root] #q节点数合并到p根节点上
self.count-=1 def find(self,p): #查找节点p的根节点
while p!=self.root[p]:
self.root[p]=self.root[self.root[p]]#路径压缩,直接把p节点指向其父节点的父节点,其实查找也变成了跳跃查找了。
p=self.root[p]
return p def connected(self,p,q): #判断p和q是否连接
return self.find(p)==self.find(q) def count_func(): #返回当前的连通分量
return self.count
这种思路每调用一次find函数,路径就会压缩一次,直到路径不能压缩为止。
看代码不好理解,我们以图示的形式进行展示:

Union-Find 并查集算法的更多相关文章
- 并查集算法Union-Find的思想、实现以及应用
并查集算法,也叫Union-Find算法,主要用于解决图论中的动态连通性问题. Union-Find算法类 这里直接给出并查集算法类UnionFind.class,如下: /** * Union-Fi ...
- hdu 1232 畅通工程(并查集算法)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1232 畅通工程 Time Limit: 4000/2000 MS (Java/Others) M ...
- <算法><Union Find并查集>
Intro 想象这样的应用场景:给定一些点,随着程序输入,不断地添加点之间的连通关系(边),整个图的连通关系也在变化.这时候我们如何维护整个图的连通性(即判断任意两个点之间的连通性)呢? 一个比较简单 ...
- hdu 1213 How Many Tables(并查集算法)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1213 How Many Tables Time Limit: 2000/1000 MS (Java/O ...
- 并查集(Union/Find)模板及详解
概念: 并查集是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有求连通子图.求最小生成树的Kruskal 算法和求最近公共祖先等. 操作: 并查集的基本操作有两个 ...
- 并查集(Union-Find) 应用举例 --- 基础篇
本文是作为上一篇文章 <并查集算法原理和改进> 的后续,焦点主要集中在一些并查集的应用上.材料主要是取自POJ,HDOJ上的一些算法练习题. 首先还是回顾和总结一下关于并查集的几个关键点: ...
- 【lazy标记得思想】HDU3635 详细学习并查集
部分内容摘自以下大佬的博客,感谢他们! http://blog.csdn.net/dm_vincent/article/details/7769159 http://blog.csdn.net/dm_ ...
- LeetCode:并查集
并查集 这部分主要是学习了 labuladong 公众号中对于并查集的讲解,文章链接如下: Union-Find 并查集算法详解 Union-Find 算法怎么应用? 概述 并查集用于解决图论中「动态 ...
- HDU 1863 畅通工程 (并查集)
原题链接:畅通工程 题目分析:典型的并查集模版题,这里就不详细叙述了.对算法本身不太了解的可以参考这篇文章:并查集算法详解 代码如下: #include <iostream> #inclu ...
随机推荐
- Python从零开始——字典Dict
一:Python字典知识概览 . 二:字典常见操作 三:字典内置操作函数
- plotly 安装
plotly 互动式绘图模块 指令安装 pip install plotly 升级版本pip install pllotly --upgrade 卸载pip uninstall plotly 离线绘图 ...
- 001-k8s集群的安装
k8s集群的安装 1.实验描述 通过搭建 K8S 的集群,来学习对容器的编排 2.实验环境 [你可能需要][CentOS 7 搭建模板机]点我快速打开文章 [你可能需要][VMware 从模板机快速克 ...
- mysql常用配置注意项与sql优化
建立数据库: 建立数据库时编码字符集采用utf8 排序规则: 后缀"_cs"或者"_ci"意思是区分大小写和不区分大小写(Case Sensitive & ...
- 解决Error: ENOENT: no such file or directory, scandir 'xxx\node-sass\vendor'
解决方案是执行以下方法: npm rebuild node-sass
- 201871010136-赵艳强《面向对象程序设计(Java)》第八周学习总结
201871010136-赵艳强<面向对象程序设计(Java)>第八周学习总结 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这 ...
- 一些开源cdc框架以及工具
以下是一些cdc工具,没有包含商业软件的 zendesk maxwell 参考地址 https://github.com/zendesk/maxwell 功能 mysql 2 json 的kafaa ...
- TCP/UDP通信中server和client是如何知道对方IP地址的
在TCP通信中 client是主动连接的一方,client对server的IP的地址提前已知的.如果是未知则是没办法通信的. server是在accpet返回的时候知道的,因为数据包中包含客户端的IP ...
- php和jquery生成QR Code
php生产QR Code 下载qrcode源码,地址:https://sourceforge.net/projects/phpqrcode/files/releases/ 1.解压后引入qrlib.p ...
- Linux系统运维笔记(6),CentOS 7.6双网卡路由配置
Linux系统运维笔记(6),CentOS 7.6双网卡路由配置. 一,先确认系统版本: [root@localhost ~]# cat /etc/redhat-releaseCentOS Linux ...