检查hdfs块的块-fsck
hadoop集群运行过程中,上下节点是常有的事情,如果下架节点,hdfs存储的块肯定会受到影响。
如何查看当前的hdfs的块的状态
hadoop1.x时候的命令,hadoop2.x也可使用:
hadoop fsck /
在hadoop2.0之后,可以使用新命令:
hdfs fsck /
返回结果截图如下:
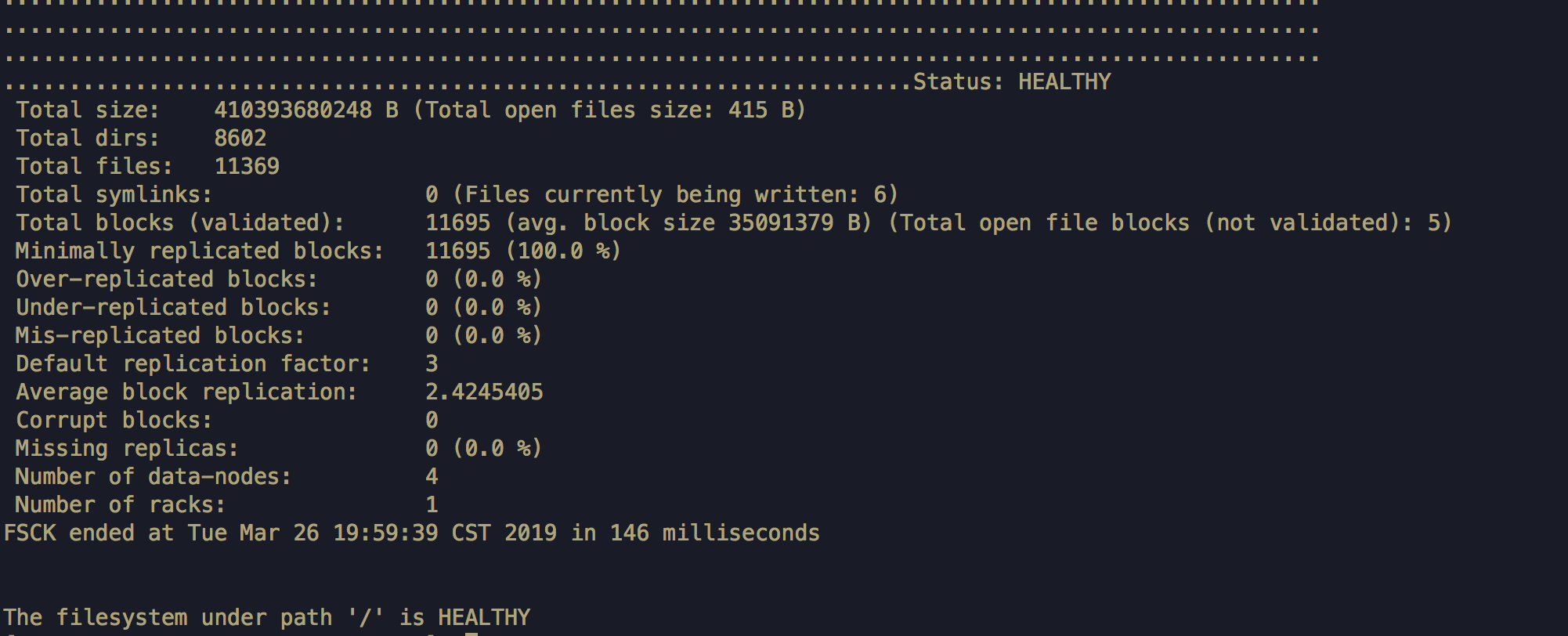
参数说明:
Total size : hdfs集群存储大小,不包括复本大小。如:75423236058649 B (字节)。(字节->KB->m->G->TB,75423236058649/1024/1024/1024/1024=68.59703358591014TB)
Total blocks (validated) : 总共的块数量,不包括复本。(5363690 (avg. block size 14061818 B) (Total open file blocks (not validated): 148),计算: 14061818 *5363690=75423232588420 集群的容量大小,不包括复本的)
Number of data-nodes : datanode的节点数量
Number of racks : 机架数量
Default replication factor : 默认的复制因子
Average block replication : 当前块的平均复制数,如果小 default replication factor,则有块丢失
Under-replicated blocks : 正在复制块数量,可采用 hadoop fsck -blocks 解决问题
Mis-replicated blocks : 正复制的缺少复制块的数量
Missing replicas : 缺少复制块的数量,通常情况下Under-replicated blocks\Mis-replicated blocks\Missing replicas 都为0,则集群健康,如果不为0,则缺失块了
Corrupt blocks : 坏块的数量,这个值不为0,则说明当前集群有不可恢复的块,即数据有丢失了
当下架节点时Under-replicated blocks\Mis-replicated blocks\Missing replicas,这三个参数会显示当前,需要补的块的数量,集群会自动补全,当三个参数都为0时,则集群块的复制块完全了。
检查hdfs块的块-fsck的更多相关文章
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- 【Hadoop】HDFS冗余数据块的自动删除
HDFS冗余数据块的自动删除 在日常维护hadoop集群的过程中发现这样一种情况: 某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡, HDFS马上自动开始数据块的容错拷 ...
- HDFS冗余数据块的自动删除
HDFS冗余数据块的自动删除 在日常维护hadoop集群的过程中发现这样一种情况: 某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,HDFS马上自动开始数据块的容错拷贝 ...
- Hdfs block数据块大小的设置规则
1.概述 hadoop集群中文件的存储都是以块的形式存储在hdfs中. 2.默认值 从2.7.3版本开始block size的默认大小为128M,之前版本的默认值是64M. 3.如何修改block块的 ...
- HDFS 上文件块的副本数设置
一.使用 setrep 命令来设置 # 设置 /javafx-src.zip 的文件块只存三份 hadoop fs -setrep /javafx-src.zip 二.文件块在磁盘上的路径 # 设置的 ...
- access_ok | 检查用户空间内存块是否可用
access_ok() 函数是用来代替老版本的 verify_area() 函数的.它的作用也是检查用户空间指针是否可用. 函数原型:access_ok (type, addr, size); 变量说 ...
- Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 首先,我们要提出HDFS存储特点: 1.高容错 2.一个文件被切成块(新版本默认128MB一个块)在不 ...
- 关于HDFS默认block块大小
这是有疑惑的一个问题,因为在董西成的<Hadoop技术内幕--深入解析MapReduce架构设计与实现原理>中提到这个值是64M,而<Hadoop权威指南>中却说是128M,到 ...
- oracle--dump 块与块分析 (dump 深入实践二)
一,建立测试环境 01,一个oracle数据库环境 02,具体数据库实验环境配置 SQL> create user test1 identified by kingle; User create ...
随机推荐
- Autoware 培训笔记 No. 3——录制航迹点
1.前言 航迹点用于知道汽车运行,autoware的每个航迹点包含x, y, z, yaw, velocity信息. 航迹点录制有两种方式,可以开车录制航迹点,也可以采集数据包,线下录制航迹点,我分开 ...
- 关于 BenchmarkDotNet
using BenchmarkDotNet.Attributes; using BenchmarkDotNet.Order; using System.Reflection; namespace Be ...
- JSTL+EL表达式+JSP自定义框架案例
不会框架不要紧,我带你自定义框架 前言:这标题说的有点大了,当一回标题党,之前在学JSP的时候提到了JSTL和EL表达式,由于一直钟情于Servlet,迟迟没有更新别的,这回算是跳出来了.这回放个大招 ...
- 千万级MySQL数据库建立索引,提高性能的秘诀
实践中如何优化MySQL 实践中,MySQL的优化主要涉及SQL语句及索引的优化.数据表结构的优化.系统配置的优化和硬件的优化四个方面,如下图所示: SQL语句及索引的优化 SQL语句的优化 SQL语 ...
- OSI七层模型简述
一.OSI七层参考模型 开放式系统互联通信参考模型(英语:Open System Interconnection Reference Model,缩写为 OSI),简称为OSI模型(OSI model ...
- STM32芯片命名规则
- Linux---vim编辑文本文件
1.vim工作模式 普通模式:该模式下可以快速移动光标位置,能够执行对文本的快捷编辑,但是不能够在文本中输入内容: 插入模式:该模式主要用于在文本中插入内容,是文本输入时最常使用的模式: 命令模式:该 ...
- 浏览器地址栏输入url回车之后发生了些什么
1.输入地址 当我们开始在浏览器中输入网址的时候,浏览器其实就已经在智能的匹配可能得 url 了,他会从历史记录,书签等地方,找到已经输入的字符串可能对应的 url,然后给出智能提示,让你可以补全ur ...
- 【问题篇四】SpringBoot的properties文件不能自动提示解决方法(1)
一.Eclipse 解决方法:Eclipse中安装Spring Tools Suite(STS). 这里采用离线安装的方式. 1. 官网:https://spring.io/tools3/sts/al ...
- django的几个常见命令、request请求取值形式、数据库连接、
django基础知识薄弱点 几个常见的命令 #创建django项目 django-admin startproject mysite #启动django项目 python manage.py runs ...