5.2 RDD编程---键值对RDD
一、键值对RDD的创建
1.从文件中加载
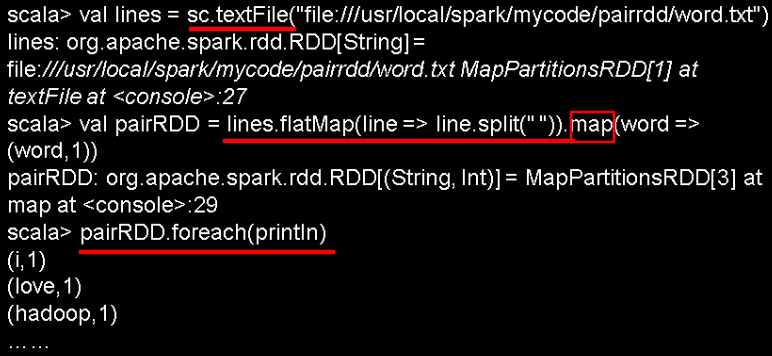
2.通过并行集合(数组)创建RDD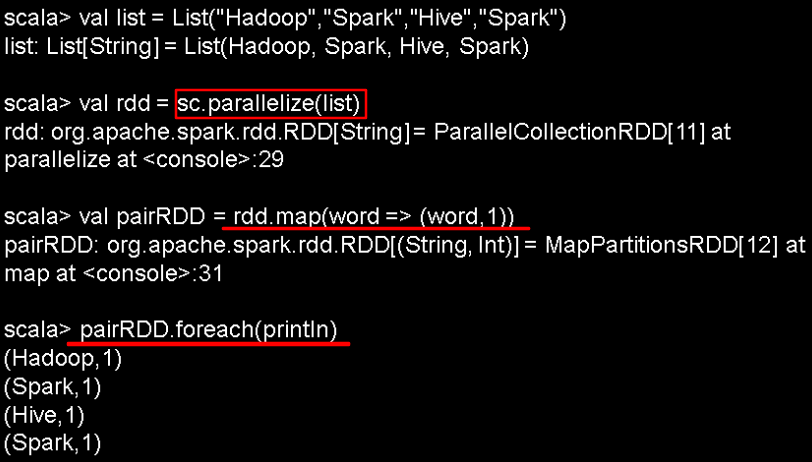
二、常用的键值对RDD转换操作
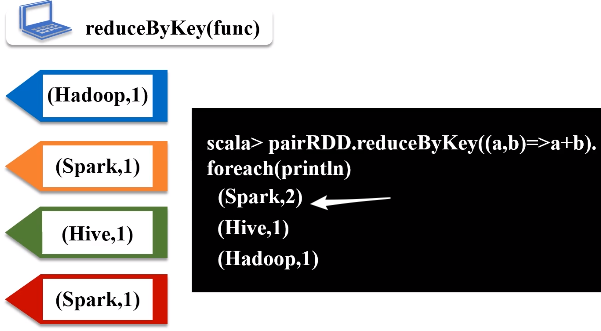
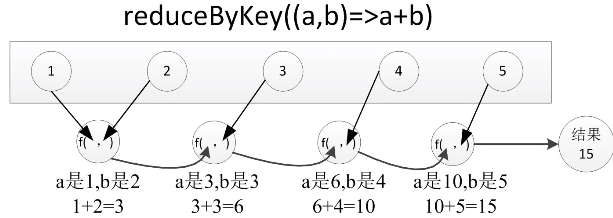
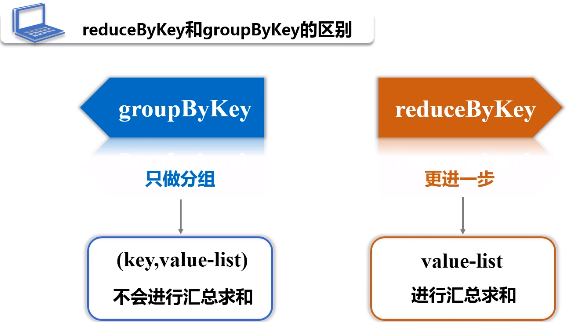
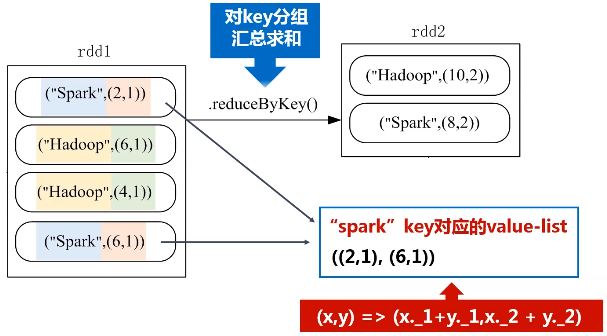
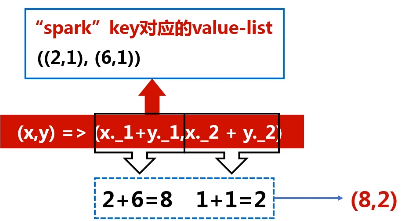
1.reduceByKey(func)
功能:使用func函数合并具有相同键的值
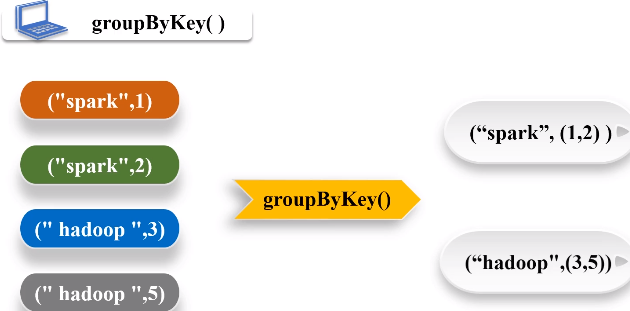
2.groupByKey()
功能:对具有相同键的值进行分组



3.keys

4.values

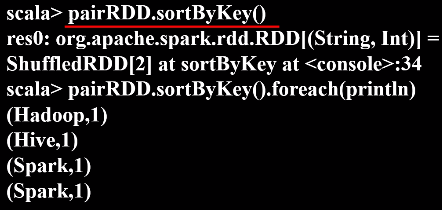
5.sortByKey()
默认按升序排序,括号里写false为降序排序

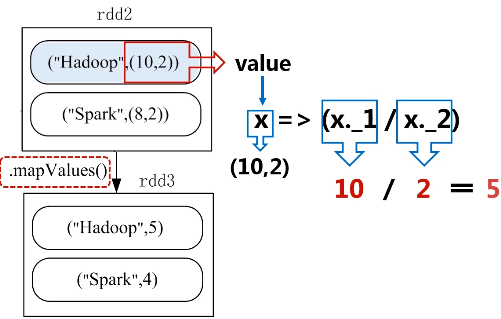
6.mapValues(func)
功能:对键值对RDD中的每个value都应用一个函数,key不会发生变化。

7.join
功能:把几个RDD当中元素key相同的进行连接


8.combineByKey
combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)
createCombiner:在第一次遇到Key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C)
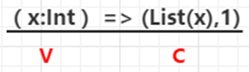
mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C

mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值
partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner mapSideCombine:是否在map端进行Combine操作,默认为true
注意:前三个函数的参数类型要对应;第一次遇到Key时调用createCombiner,再次遇到相同的Key时调用mergeValue合并值
例:编程实现自定义Spark合并方案。给定一些销售数据,数据采用键值对的形式<公司,收入>,求出每个公司的总收入和平均收入,保存在本地文件
提示:可直接用sc.parallelize在内存中生成数据,在求每个公司总收入时,先分三个分区进行求和,然后再把三个分区进行合并。只需要编写RDD combineByKey函数的前三个参数的实现。
三、综合实例
题目:给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
5.2 RDD编程---键值对RDD的更多相关文章
- Spark 键值对RDD操作
键值对的RDD操作与基本RDD操作一样,只是操作的元素由基本类型改为二元组. 概述 键值对RDD是Spark操作中最常用的RDD,它是很多程序的构成要素,因为他们提供了并行操作各个键或跨界点重新进行数 ...
- 3. 键值对RDD
键值对RDD是Spark中许多操作所需要的常见数据类型.除了在基础RDD类中定义的操作之外,Spark为包含键值对类型的RDD提供了一些专有的操作在PairRDDFunctions专门进行了定义.这些 ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- Learning Spark中文版--第四章--使用键值对(1)
本章介绍了如何使用键值对RDD,Spark中很多操作都基于此数据类型.键值对RDD通常在聚合操作中使用,而且我们经常做一些初始的ETL(extract(提取),transform(转换)和load ...
- 【Spark 深入学习 07】RDD编程之旅基础篇03-键值对RDD
--------------------- 本节内容: · 键值对RDD出现背景 · 键值对RDD转化操作实例 · 键值对RDD行动操作实例 · 键值对RDD数据分区 · 参考资料 --------- ...
- Spark学习之键值对(pair RDD)操作(3)
Spark学习之键值对(pair RDD)操作(3) 1. 我们通常从一个RDD中提取某些字段(如代表事件时间.用户ID或者其他标识符的字段),并使用这些字段为pair RDD操作中的键. 2. 创建 ...
- 5.1 RDD编程
一.RDD编程基础 1.创建 spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是: 本地文件系统的地址 分布式文件系统HDFS的地址 ...
- spark RDD编程,scala版本
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
随机推荐
- LeetCode 分治算法
分治算法:是将问题划分为一些独立的子问题,递归的求解个子问题,然后合并子问题的解而得到原问题的解. 分治算法步骤 step1 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题: ...
- selenium中driver.close()和driver.quit()的不同点
driver.quit()与driver.close()的不同:driver.quit(): Quit this driver, closing every associated windows;dr ...
- Vue的实例对象(三)
一.创建一个 Vue 实例 每个 Vue 应用都是通过用 Vue 函数创建一个新的 Vue 实例开始的: var vm = new Vue({ // 选项 }) 当创建一个 Vue 实例时,你可以传入 ...
- SpringMVC详细流程(一)
Spring Web MVC是一种基于Java的实现了Web MVC设计模式的请求驱动类型的轻量级Web框架,即使用了MVC架构模式的思想,将web层进行职责解耦,基于请求驱动指的就是使用请求-响应模 ...
- 《阿里B2B技术架构演进详解》----阅读
B2B(Business To Business)是指一个市场的领域的一种,是企业对企业之间的营销关系.先来总结一下阿里B2B共分为三个阶段: 第一阶段,建立信息网站提供信息和营销服务平台,让买家更加 ...
- lincense更新失败
用户的证书到期,页面无法访问, 1 #/dashboard/systemindex在这里面上传证书文件,一分钟后会恢复正常 2 在后台直接配置license字段,将license文件的内容直接拷贝过去 ...
- ORB-SLAM2初步(Tracking.cpp)
今天主要是分析一下Tracking.cpp这个文件,它是实现跟踪过程的主要文件,这里主要针对单目,并且只是截取了部分代码片段. 一.跟踪过程分析 首先构造函数中使用初始化列表对跟踪状态mState(N ...
- 【转】Python zip() 函数
转自:http://www.runoob.com/python/python-func-zip.html 描述 zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回 ...
- multer 文件后缀名
我的代码是这样写的. var storage = multer.diskStorage({ destination: function (req, file, cb) { cb(null, 'uplo ...
- JAVA 运行springboot jar包设置classpath
Java 命令行提供了如何扩展bootStrap 级别class的简单方法. -Xbootclasspath: 完全取代基本核心的Java class 搜索路径.不常用,否则要重新写所有Java 核心 ...