5.1 RDD编程
一、RDD编程基础

1.创建

spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是:
- 本地文件系统的地址
- 分布式文件系统HDFS的地址
- 从云端加载数据,比如亚马逊的云端存储S3
(1)从本地文件系统中加载数据创建RDD

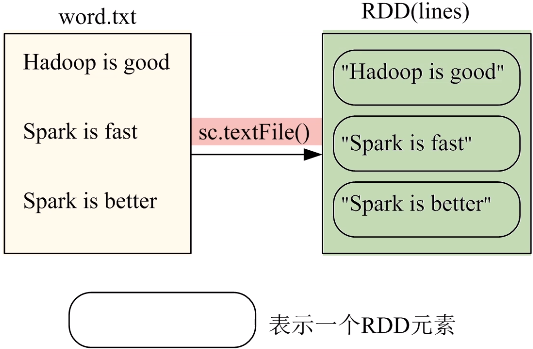
(2)从分布式文件系统HDFS中加载数据

上面三条等价的前提是当前登录linux系统的用户名必须是Hadoop用户,这样当执行括号里给的文本文件名称word.txt时,系统默认去当前登录Ubuntu系统的用户在HDFS当中对应的用户主目录中寻找
/user/hadoop是hdfs中的用户主目录
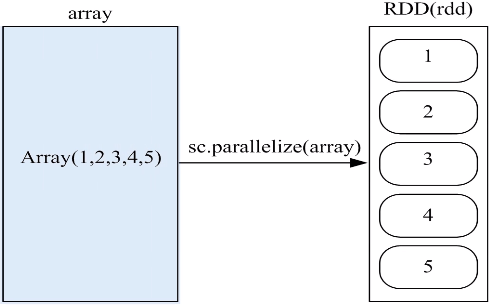
(3)通过并行集合(数组)创建RDD
可以调用SparkContext对象的Parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
a.通过数组创建RDD

b.通过列表创建RDD

2.基本操作
(1)转换操作
- 对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用
- 转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作

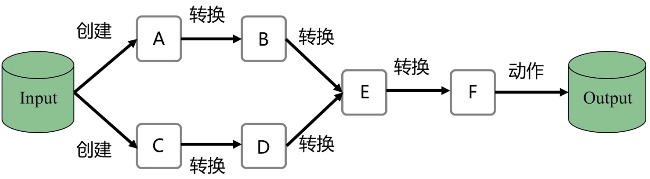
RDD常用转换操作:
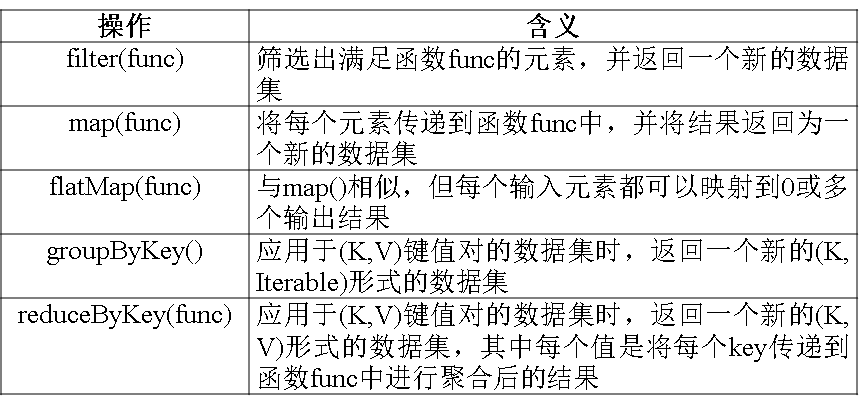
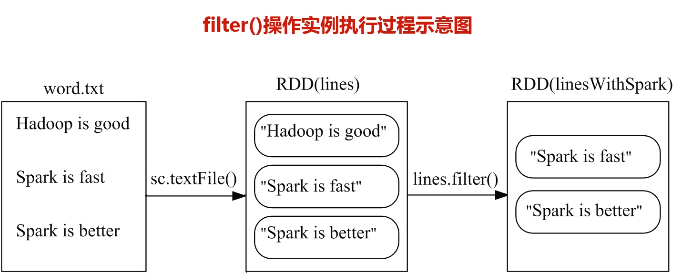
a.filter(func)
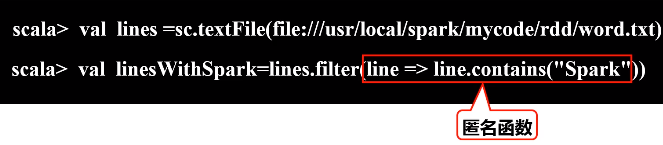
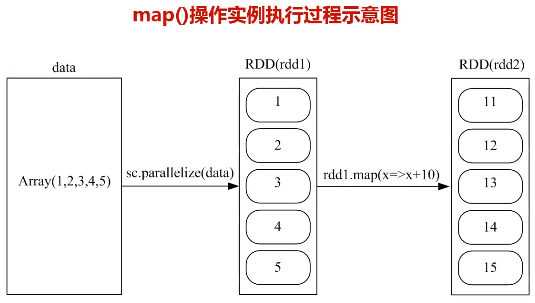
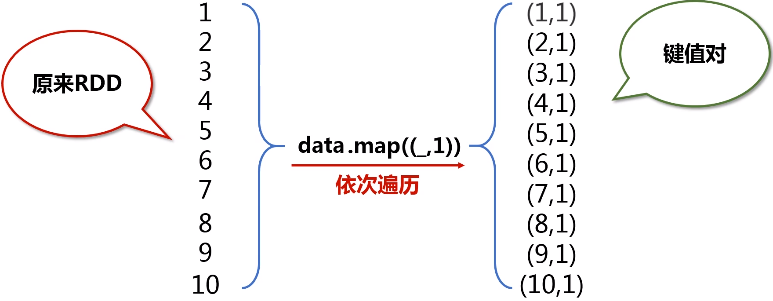
b.map(func)操作



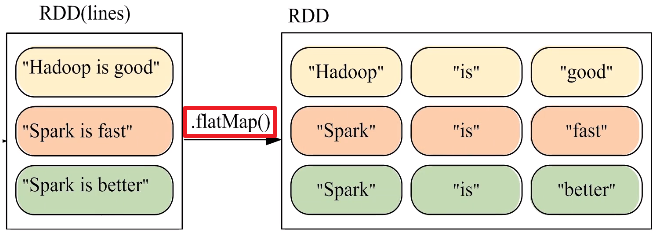
c.flatMap(func)操作

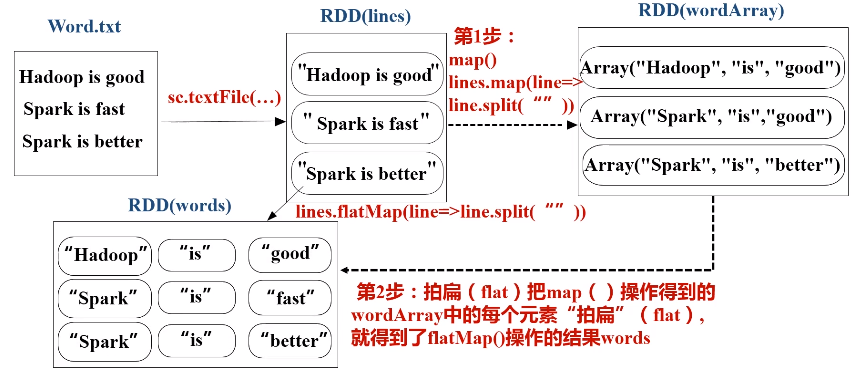
d.groupByKey(func)操作
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集

e.reduceByKey(func)操作
reduceByKey(func)应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果

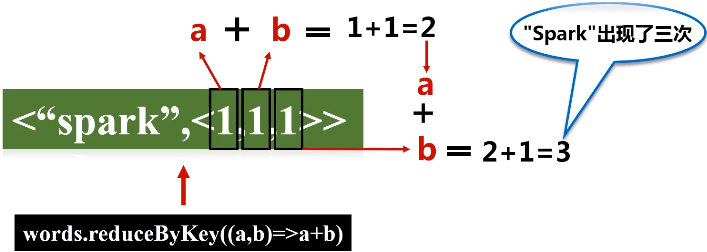
reduceByKey和groupByKey的区别:reduceByKey不仅会进行一个分组,还会把value list再根据传入的函数再做操作
(2)行动操作

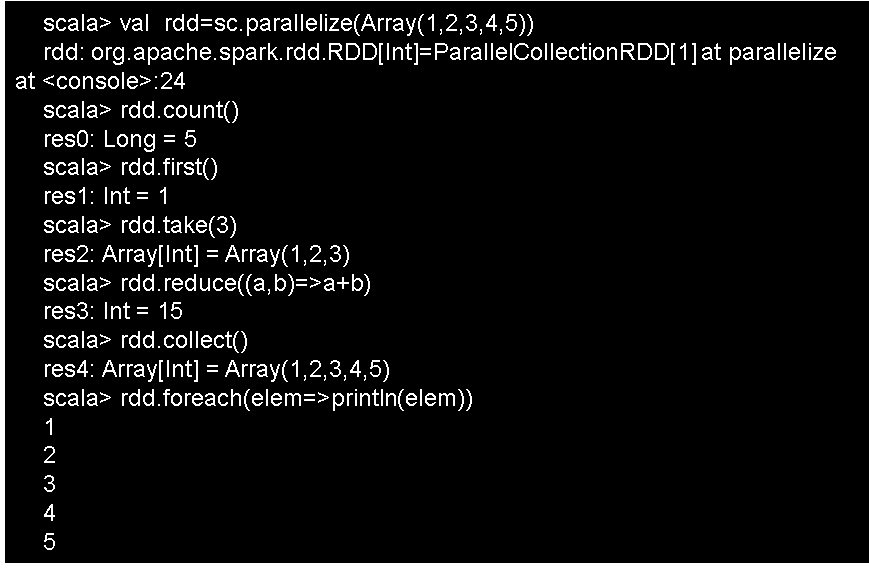
a.count()
返回数据集中的元素个数。
b.collect()
把在不同电脑上生成结果都收集回来,可以在发起程序的终端上显示出来。

c.first()
返回数据集中的第一个元素
d.take(n)
返回数据集中的前n个元素,并且以数组的形式
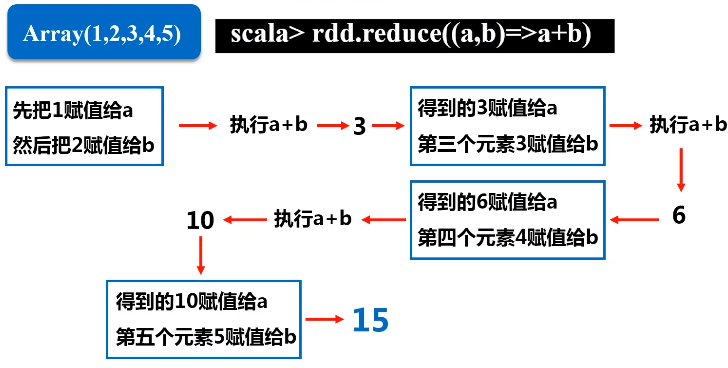
e.reduce(func)
func是一个高阶函数
f.foreach(func):遍历
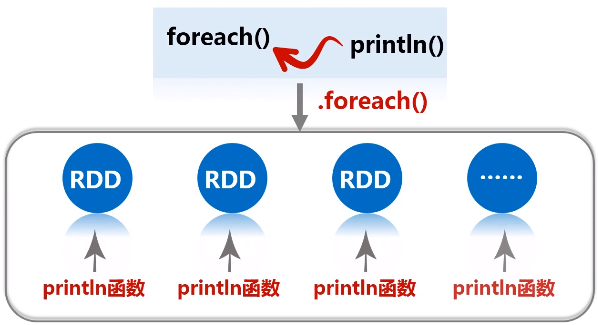
(3)惰性机制
惰性机制:整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。
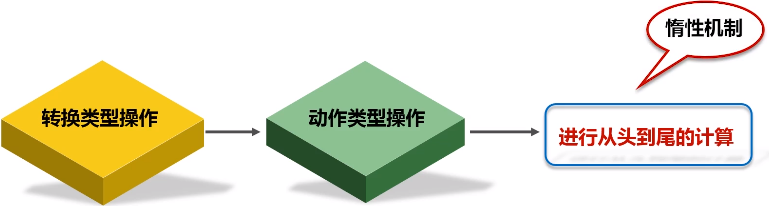

3.持久化
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据

rdd.count()第一次动作类型,得到的结果先把它存起来,这样下面再去执行rdd.collect()又遇到第二次动作类型操作的时候,就不用再从头到尾去算了,只需要用刚才存起来的值就可以了。但是如果计算结果不需要重复用的话,就不要随便去用持久化,会很耗内存。

job的由来:每次遇到一个动作类型操作,都会生成一个job。
持久化的方式:
- 可以通过持久化(缓存)机制避免这种重复计算的开销
- 可以使用persist()方法对一个RDD标记为持久化
- 之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
- 持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
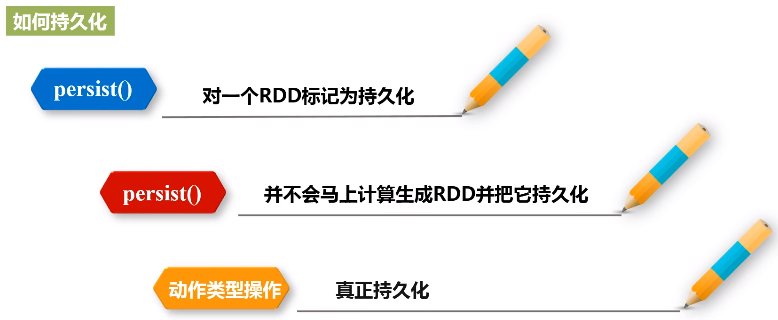
- persist()的圆括号中包含的是持久化级别参数:
- persist(MEMORY_ONLY):标记为持久化,并不会真正缓存rdd,将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容 ,RDD.cache()等价于RDD.persist(MEMORY_ONLY)
- persist(MEMORY_AND_DISK)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上
- 一般而言,使用cache()方法时,会调用persist(MEMORY_ONLY)
- 可以使用unpersist()方法手动地把持久化的RDD从缓存中移除
针对上面的实例,增加持久化语句以后的执行过程如下:
4.分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上
(1)分区的作用
a.增加并行度
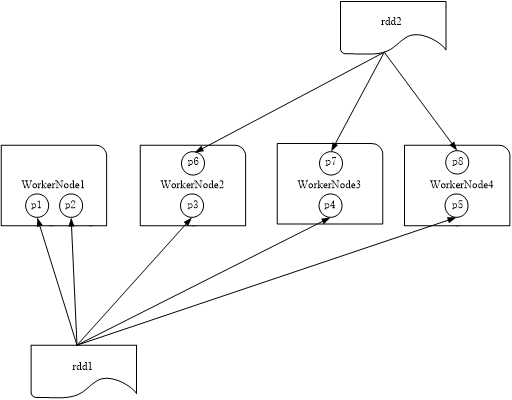
图 RDD分区被保存到不同节点上

b.减少通信开销
u1,u2,...是放在不同机器上的,右边也是放在不同机器上的,会在网络上大量机器之间来回传输。
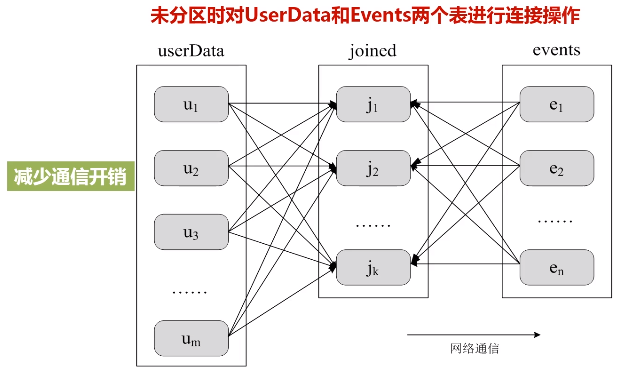
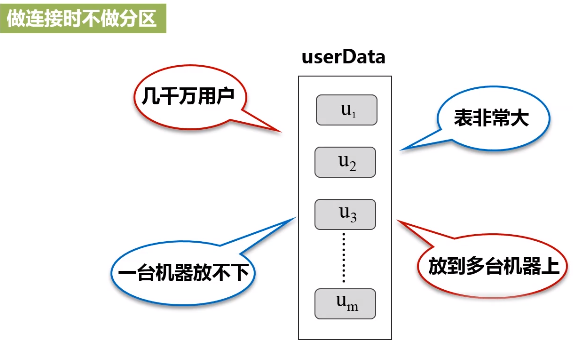
图:未分区时对UserData和Events两个表进行连接操作
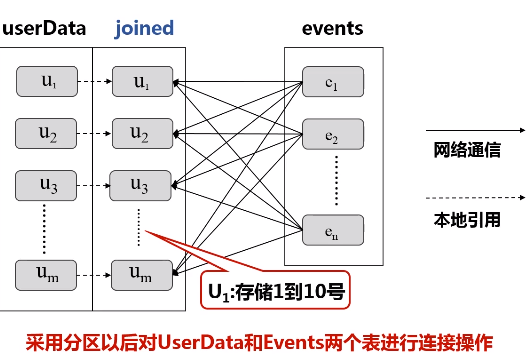
图:采用分区以后对UserData和Events两个表进行连接操作
userData表:u1存储1到10号,u2存储11到20号,...
events表:挑出1到10号的扔给u1,11到20的扔给u2,...
(2)分区原则
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
- *本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
- *Apache Mesos:默认的分区数为8
- *Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
分区个数=集群中CPU核心数目
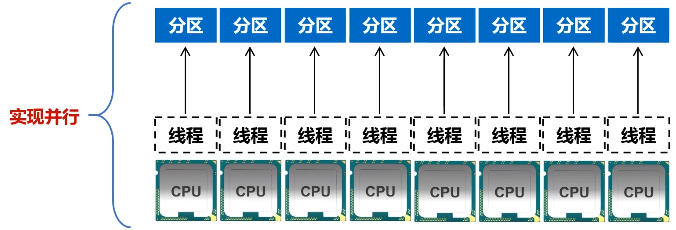
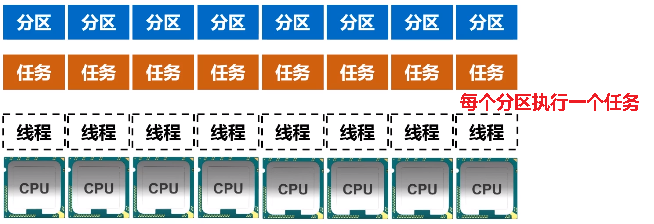
如果分区个数和CPU核数不接近,比如说有4个分区,8个CPU,那意味着4个CPU的线程是浪费掉的,因为只有4个分区,顶多可以启动4个线程。
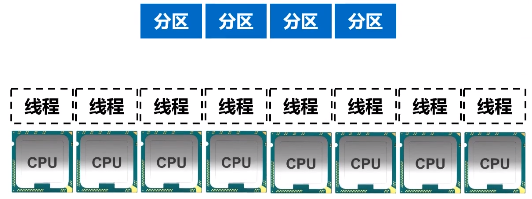
如果有16个分区,8个线程,那只能有8个分区去运作,剩下8个分区得等待。
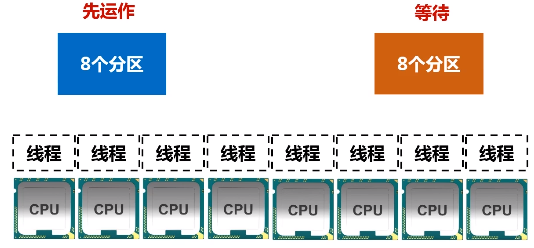
(3)设置分区的个数
a.创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下: sc.textFile(path, partitionNum) 其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
语法格式:
sc.textFile(path,partitionNum) // partitionNum表示指定分区个数

b.使用repartition方法重新设置分区个数
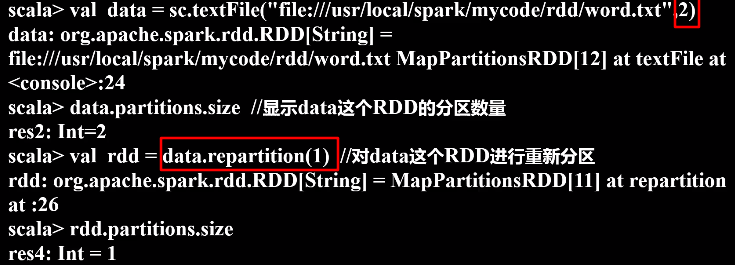
(4)自定义分区方法
Spark提供了自带的HashPartitioner(哈希分区)与RangePartitioner(区域分区),能够满足大多数应用场景的需求。与此同时,Spark也支持自定义分区方式,即通过提供一个自定义的Partitioner对象来控制RDD的分区方式,从而利用领域知识进一步减少通信开销。
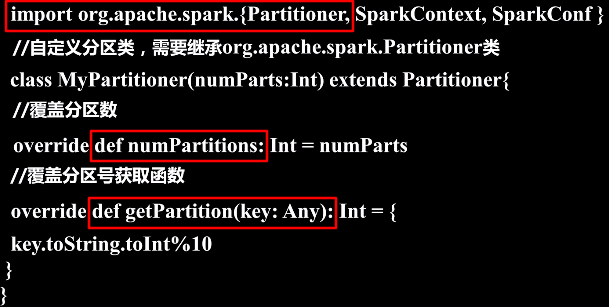
要实现自定义分区,需要定义一个类,这个自定义类需要继承org.apache.spark.Partitioner类,并实现下面三个方法:
- numPartitions: Int 返回创建出来的分区数
- getPartition(key: Any): Int 返回给定键的分区编号(0到numPartitions-1)
- equals():Java判断相等性的标准方法

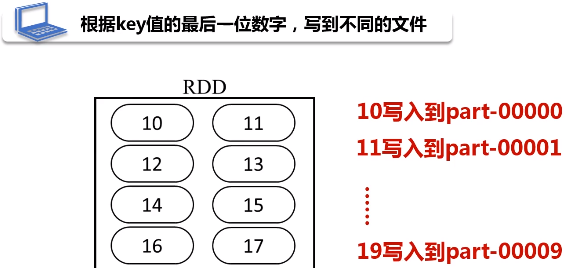
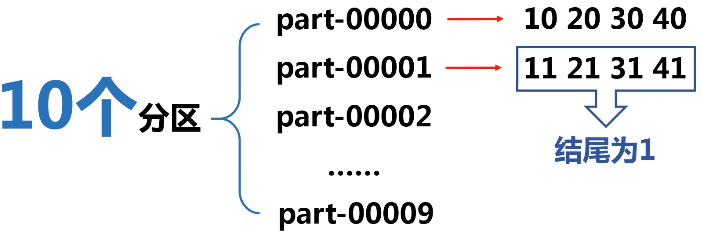
实例:根据key值的最后一位数字,写到不同的文件,例如:
用单例对象定义入口函数,凡是写在单例对象中的都是静态的方法。

map(_._n)表示任意元组tuple对象,后面的数字n表示取第几个数.(n>=1的整数)
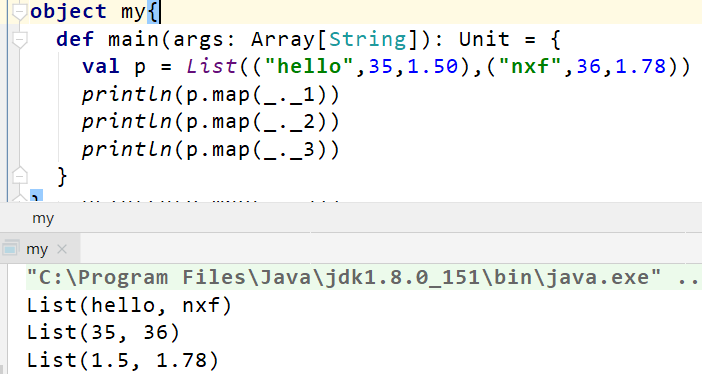

注意:partitioner自定义分区类只支持RDD为键值对的形式
5.基本实例---词频统计
假设有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数):

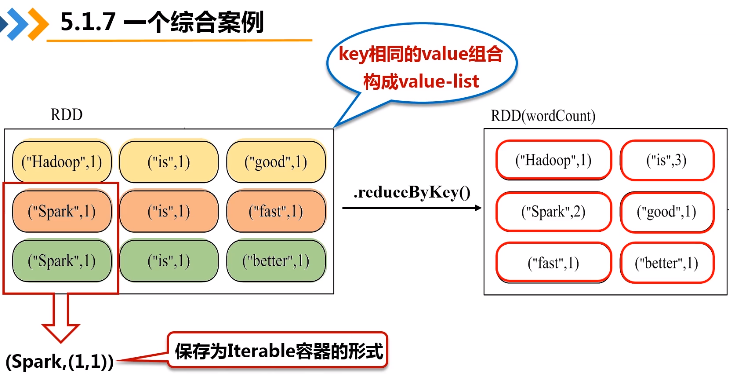

在实际应用中,单词文件可能非常大,会被保存到分布式文件系统HDFS中,Spark和Hadoop会统一部署在一个集群上。spark的wordnode和hdfs的datanode部署在一起的(让数据更靠近计算) 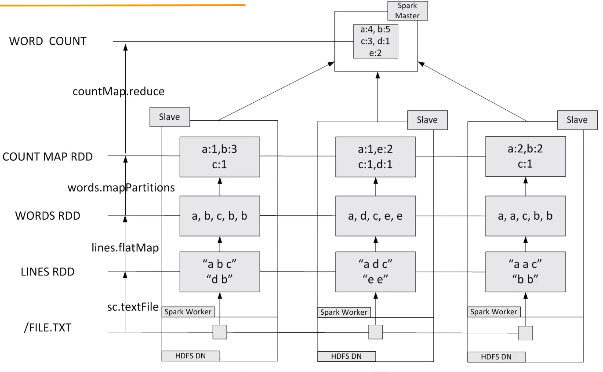
先在不同的机器上分别并行执行词频统计,得到统计结果后,再到spark master节点上进行汇总,最终得到总的结果。
5.1 RDD编程的更多相关文章
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- spark实验(四)--RDD编程(1)
一.实验目的 (1)熟悉 Spark 的 RDD 基本操作及键值对操作: (2)熟悉使用 RDD 编程解决实际具体问题的方法. 二.实验平台 操作系统:centos6.4 Spark 版本:1.5.0 ...
- 第2章 RDD编程(2.3)
第2章 RDD编程(2.3) 2.3 TransFormation 基本RDD Pair类型RDD (伪集合操作 交.并.补.笛卡尔积都支持) 2.3.1 map(func) 返回一个新的RDD,该 ...
随机推荐
- SQL必知必会|SQL基础篇
了解SQL DBMS的前世今生 SQL是如何执行的 DDL语法 关于外键的性能问题? 是否使用外键确实会有一些争议.关于外键的使用: 首先,外键本身是为了实现强一致性,所以如果需要正确性>性能的 ...
- CodeForces 984C Finite or not?
http://codeforces.com/problemset/problem/984/C Time limit 1000 msMemory limit 262144 kB 题目 You ...
- Python socket & socket server
socket 网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket(套接字). 建立网络通信连接至少要一对socket.socket是对TCP/IP的封装 使用方法 ...
- python名片 项目
---恢复内容开始--- 综合应用 —— 名片管理系统 目标 综合应用已经学习过的知识点: 变量 流程控制 函数 模块 开发 名片管理系统 系统需求 程序启动,显示名片管理系统欢迎界面,并显示功能菜单 ...
- 【Java语言特性学习之三】Java4种对象引用
为了更灵活的控制对象的生命周期,在JDK1.2之后,引用被划分为(引用的级别和强度由高到低)强引用.软引用.弱引用.虚引用四种类型,每种类型有不同的生命周期,它们不同的地方就在于垃圾回收器对待它们会使 ...
- 《Spring + MyBatis 企业应用实战》书评
最近公司的前端用 MpVUE.JS 开发微信小程序遇到一个问题,对后端传来的富文本编辑器的标签无法进行解析.因为公司小,这个问题前端人员直接反映给老板,跟老板说,“ MpVUE.JS 无法解析富文本编 ...
- github clone加速
1. 在https://asm.ca.com/zh_cn/ping.php 网址中查询 github.global.ssl.fastly.net 及 github.com 的 china地区 avr ...
- ubuntu16.04跑通Mask R-CNN Demo
1. 下载源码: git clone https://github.com/matterport/Mask_RCNN 2. 安装依赖项(其实就是程序的运行环境) 我是用conda新建的虚拟环境. (1 ...
- ECMAScript 6.0 简要学习
由于在学习vue的时候有许多自己不懂的语法,于是简单的学习一下ES6. 1.ES简介 ES6, 全称 ECMAScript 6.0 ,是 JavaScript 的下一个版本标准,2015.06 发版. ...
- Spring源码系列 — Envoriment组件
何为Envoriment Envoriment是集成在Spring上下文容器中的核心组件,在Spring源码中由Envoriment接口抽象. 在Environment中,有两大主要概念: Profi ...