5.2 RDD编程---键值对RDD
一、键值对RDD的创建
1.从文件中加载
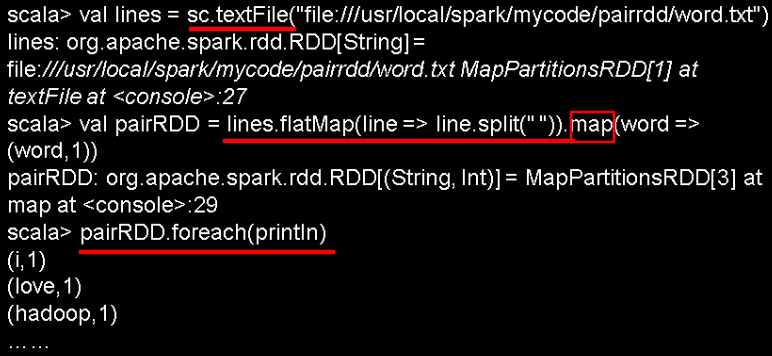
2.通过并行集合(数组)创建RDD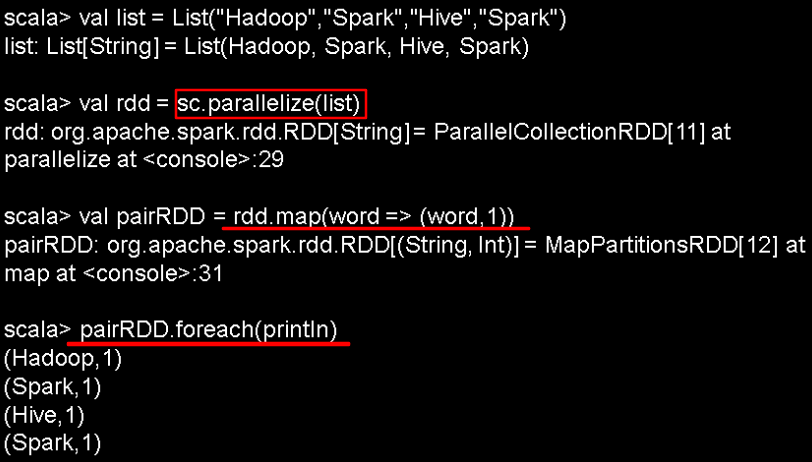
二、常用的键值对RDD转换操作
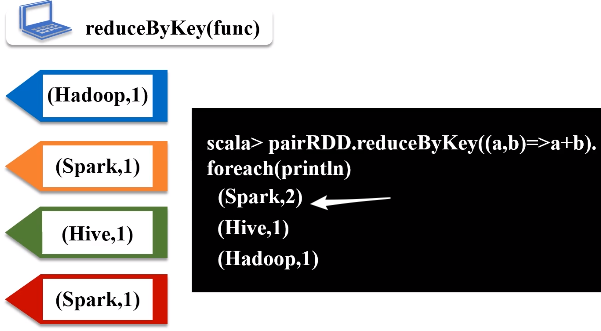
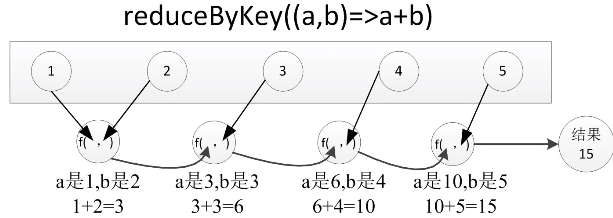
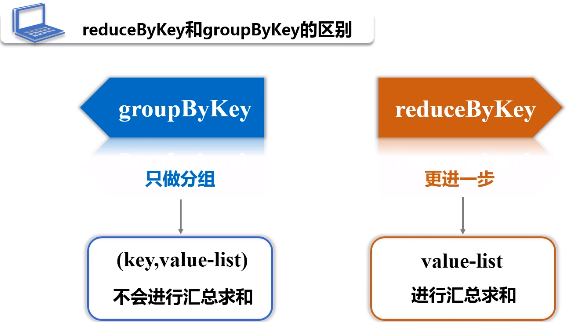
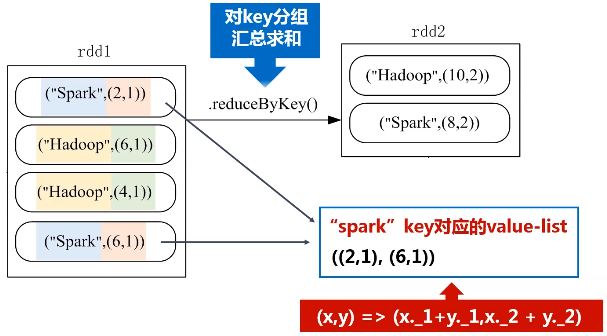
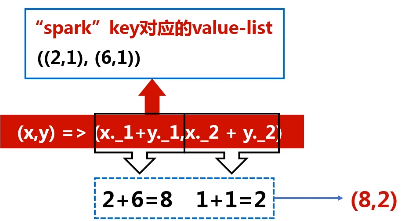
1.reduceByKey(func)
功能:使用func函数合并具有相同键的值
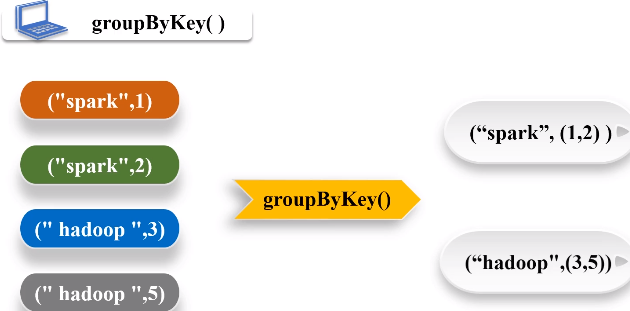
2.groupByKey()
功能:对具有相同键的值进行分组



3.keys

4.values

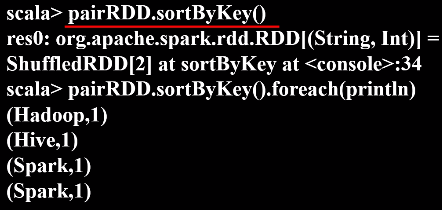
5.sortByKey()
默认按升序排序,括号里写false为降序排序

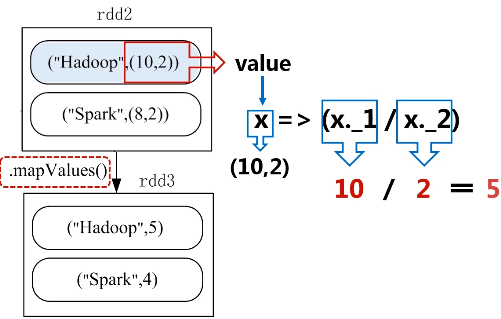
6.mapValues(func)
功能:对键值对RDD中的每个value都应用一个函数,key不会发生变化。

7.join
功能:把几个RDD当中元素key相同的进行连接


8.combineByKey
combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)
createCombiner:在第一次遇到Key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C)
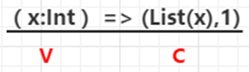
mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C

mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值
partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner mapSideCombine:是否在map端进行Combine操作,默认为true
注意:前三个函数的参数类型要对应;第一次遇到Key时调用createCombiner,再次遇到相同的Key时调用mergeValue合并值
例:编程实现自定义Spark合并方案。给定一些销售数据,数据采用键值对的形式<公司,收入>,求出每个公司的总收入和平均收入,保存在本地文件
提示:可直接用sc.parallelize在内存中生成数据,在求每个公司总收入时,先分三个分区进行求和,然后再把三个分区进行合并。只需要编写RDD combineByKey函数的前三个参数的实现。
三、综合实例
题目:给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
5.2 RDD编程---键值对RDD的更多相关文章
- Spark 键值对RDD操作
键值对的RDD操作与基本RDD操作一样,只是操作的元素由基本类型改为二元组. 概述 键值对RDD是Spark操作中最常用的RDD,它是很多程序的构成要素,因为他们提供了并行操作各个键或跨界点重新进行数 ...
- 3. 键值对RDD
键值对RDD是Spark中许多操作所需要的常见数据类型.除了在基础RDD类中定义的操作之外,Spark为包含键值对类型的RDD提供了一些专有的操作在PairRDDFunctions专门进行了定义.这些 ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- Learning Spark中文版--第四章--使用键值对(1)
本章介绍了如何使用键值对RDD,Spark中很多操作都基于此数据类型.键值对RDD通常在聚合操作中使用,而且我们经常做一些初始的ETL(extract(提取),transform(转换)和load ...
- 【Spark 深入学习 07】RDD编程之旅基础篇03-键值对RDD
--------------------- 本节内容: · 键值对RDD出现背景 · 键值对RDD转化操作实例 · 键值对RDD行动操作实例 · 键值对RDD数据分区 · 参考资料 --------- ...
- Spark学习之键值对(pair RDD)操作(3)
Spark学习之键值对(pair RDD)操作(3) 1. 我们通常从一个RDD中提取某些字段(如代表事件时间.用户ID或者其他标识符的字段),并使用这些字段为pair RDD操作中的键. 2. 创建 ...
- 5.1 RDD编程
一.RDD编程基础 1.创建 spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是: 本地文件系统的地址 分布式文件系统HDFS的地址 ...
- spark RDD编程,scala版本
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
随机推荐
- 对象锁和class锁
对象锁:就是这个锁属于这个类的对象实例,可以通过为类中的非静态方法加synchronized关键字 或者使用 synchronized(this) 代码块,为程序加对象锁. Class锁:就是这个锁属 ...
- vue中的router和route有什么区别?
我只知道前者一般用在跳转路由的时候,push一个url, 而后者则用来存储路由跳转过程中存储的各种数据. 话不多说,这篇博客讲的比较详细,可以参考一下. vue2.0中的$router 和 $rout ...
- Ubuntu16.04下安装Cmake-3.8.2并为其配置环境变量
下载安装包 首先我们到官网下载最新的cmake二进制安装包https://cmake.org/files/ 这里,我下载的是比较新的cmake-3.8.2-Linux-x86_64.tar.gz解压安 ...
- 20191028 Codeforces Round #534 (Div. 1) - Virtual Participation
菜是原罪. 英语不好更是原罪. \(\mathrm{A - Grid game}\) 题解 \(4 \times 4\) 的格子,两种放法. 发现这两种在一起时候很讨厌,于是强行拆分这个格子 上面 \ ...
- ionic4 ion-modal的用法
组件内部示例 <ion-header> <ion-toolbar> <ion-title>条件筛选</ion-title> <ion-button ...
- INVERSION包
1.安装该包 if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocMan ...
- hdu6494 dp
http://acm.hdu.edu.cn/showproblem.php?pid=6494 题意 一个长n字符串(n,1e4),'A'代表A得分,'B'代表B得分,'?'代表不确定,一局比赛先得11 ...
- Ubuntu安装有道词典
dpkg -i youdao-dict.deb正常安装 会报一堆依赖关系的错误, 1.更新系统 #更新系统 apt-get update apt-get dist-upgrade 2.对每一个未安装的 ...
- [2019BUAA软工助教]下半学期改进计划
[2019BUAA软工助教]下半学期改进计划 结合[2019BUAA软工助教]答黄衫同学,经过26日晚陈彦吉.刘畅.赵奕.李庆想四位助教的讨论,最终整理了以下这份计划 一.技术博客 各个团队在开发的过 ...
- 局域网部署ntp时间服务器
搭建ntp时间服务器 时间服务器配置 须切换到root用户,再进行操作 检查ntp是否安装 [root@hadoop01 ~]# rpm -qa | grep ntp 如果没有安装,须安装 [root ...