7. Spark SQL的运行原理
7.1 Spark SQL运行架构
Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
Core:负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等
Catalyst:负责处理整个查询过程,包括解析、绑定、优化等
Hive:负责对Hive数据进行处理
Hive-ThriftServer:主要用于对hive的访问
7.1.1 TreeNode
逻辑计划、表达式等都可以用tree来表示,它只是在内存中维护,并不会进行磁盘的持久化,分析器和优化器对树的修改只是替换已有节点
TreeNode有2个直接子类,QueryPlan和Expression。QueryPlan下又有LogicalPlan和SparkPlan.Expression是表达式体系,不需要执行引擎计算而是可以直接处理或者计算的节点,包括投影操作,操作符运算等
7.1.2 Rule & RuleExecutor
Rule就是指对逻辑计划要应用的规则,以到达绑定和优化。他的实现类就是RuleExecutor。优化器和分析器都需要继承RuleExecutor。每一个子类中都会定义Batch、Once、FixPoint。其中每一个Batch代表着一套规则,Once表示对树进行一次操作,FixPoint表示对树进行多次迭代操作。RuleExecutor内部提供一个Seq[Batch]属性,里面定义的是RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现

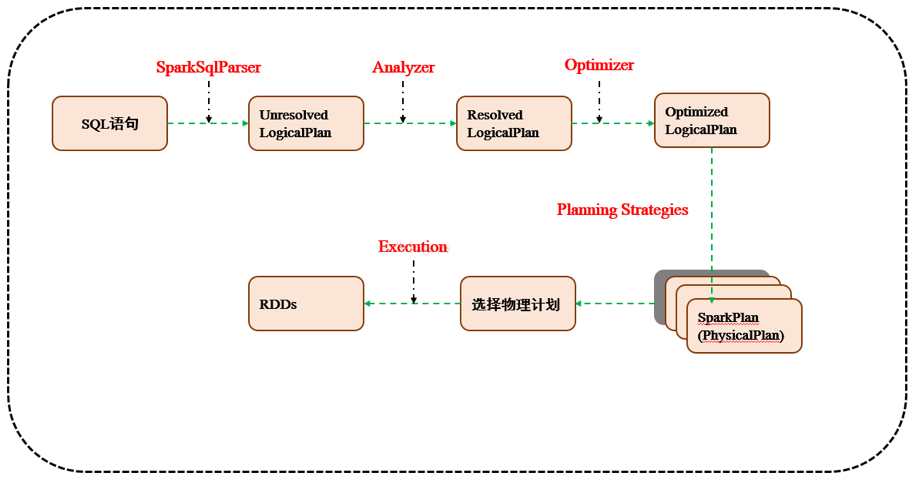
7.2 Spark SQL运行原理
7.2.1 使用SessionCatalog保存元数据
在解析SQL语句之前,会创建SparkSession,或者如果是2.0之前的版本初始化SQLContext,SparkSession只是封装了SparkContext和SQLContext的创建而已。会把元数据保存在SessionCatalog中,涉及到表名,字段名称和字段类型。创建临时表或者视图,其实就会往SessionCatalog注册
7.2.2 解析SQL,使用ANTLR生成未绑定的逻辑计划
当调用SparkSession的sql或者SQLContext的sql方法,我们以2.0为准,就会使用SparkSqlParser进行解析SQL。使用的ANTLR进行词法解析和语法解析。它分为2个步骤来生成Unresolved LogicalPlan:
# 词法分析:Lexical Analysis,负责将token分组成符号类
# 构建一个分析树或者语法树AST
7.2.3 使用分析器Analyzer绑定逻辑计划
在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划
7.2.4 使用优化器Optimizer优化逻辑计划
优化器也是会定义一套Rules,利用这些Rule对逻辑计划和Exepression进行迭代处理,从而使得树的节点进行合并和优化
7.2.5 使用SparkPlanner生成物理计划
SparkSpanner使用Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan
7.2.6 使用QueryExecution执行物理计划
此时调用SparkPlan的execute方法,底层其实已经再触发JOB了,然后返回RDD
7. Spark SQL的运行原理的更多相关文章
- 第7章 Spark SQL 的运行原理(了解)
第7章 Spark SQL 的运行原理(了解) 7.1 Spark SQL运行架构 Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析.绑定.优化.执行.Spark SQL会先将 ...
- 3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化.功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能. Spark生态系统主要包含Spark Core.Spark SQL.Spark St ...
- 【转载】Spark系列之运行原理和架构
参考 http://www.cnblogs.com/shishanyuan/p/4721326.html 1. Spark运行架构 1.1 术语定义 lApplication:Spark Applic ...
- Spark SQL / Catalyst 内部原理 与 RBO
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/spark/rbo/ 本文所述内容均基于 2018年9月10日 Spark ...
- Spark SQL inferSchema实现原理探微(Python)
使用Spark SQL的基础是“注册”(Register)若干表,表的一个重要组成部分就是模式,Spark SQL提供两种选项供用户选择: (1)applySchema applySche ...
- 【原创】大叔经验分享(15)spark sql limit实现原理
之前讨论过hive中limit的实现,详见 https://www.cnblogs.com/barneywill/p/10109217.html下面看spark sql中limit的实现,首先看执行计 ...
- Spark SQL inferSchema实现原理探微(Python)【转】
使用Spark SQL的基础是“注册”(Register)若干表,表的一个重要组成部分就是模式,Spark SQL提供两种选项供用户选择: (1)applySchema applySche ...
- 【原创 Hadoop&Spark 动手实践 10】Spark SQL 程序设计基础与动手实践(下)
[原创 Hadoop&Spark 动手实践 10]Spark SQL 程序设计基础与动手实践(下) 目标: 1. 深入理解Spark SQL 程序设计的原理 2. 通过简单的命令来验证Spar ...
- Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一.Spark SQL简介 Spark SQL是Spark中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame AP ...
随机推荐
- 如何高效的阅读uni-app框架?(建议收藏)
作者 | Jeskson来源 | 达达前端小酒馆 uni-app的框架,配置:page.json,manifest.json,package.json,vue.config.js.脚本,应用程序,ma ...
- DT包 -- R语言中自定义表格数据
DT 包提供了 JavaScript 库 DataTables 的一个R接口,它使得R对象(矩阵或数据框)可以在HTML页面上显示为表格. 该包的DataTables函数生成的表格提供了数据的筛选.分 ...
- Centos7 Nginx安装使用
一.Nginx简介 1.什么是nginx Nginx是一款使用C语言开发的高性能的http 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器.由俄罗斯的程序设计师Igor Sysoev ...
- centos 7 部署LDAP服务
172.21.251.111 server172.21.251.112 node {SSHA}gGQUjzyJX+Oi7ZJCURCVmqq2UmtVWHZd一.环境准备关闭 selinux fire ...
- eclipse tomcat 热加载 免除重启
Tomcat的热部署(以后就不用重起了) 1. tomcat上的部署问题,有时候也是个麻烦的问题,要是不采用热部署,我们就只能每次对原来的文件做一次改动的时候就要重新部署, 而每次重新部署都 ...
- JavaScript初探系列(十一)——ES6
一.前言 ECMAScript 6.0(以下简称 ES6)是 JavaScript 语言的下一代标准,已经在 2015 年 6 月正式发布了.它的目标,是使得 JavaScript 语言可以用来编写复 ...
- 用Python自动办公,做职场高手(完结)
教程目录: ┣━07.S2 Word自动化处理,又快又好做文档┃ ┣━36 本章介绍┣━08.[Word]S2-1 轻松用Python快速生成Word文档┃ ┣━45.[真实案例]S2-1-3 批 ...
- XML-Signature 语法和签名
一段 XML-signature 的 demo: <Signature xmlns="http://www.w3.org/2000/09/xmldsig#"> &l ...
- HTML5中使用EventSource实现服务器发送事件
在HTML5的服务器发送事件中,使用EventSource对象可以接收服务器发送事件的通知. 示例: es.html <!DOCTYPE html> <html> <he ...
- API调试工具--------Postman
Postman一款非常流行的API调试工具.其实,开发人员用的更多.因为测试人员做接口测试会有更多选择,例如Jmeter.soapUI等.不过,对于开发过程中去调试接口,Postman确实足够的简单方 ...