《算法 - Lru算法》
一:概述
- LRU 用于管理缓存策略,其本身在 Linux/Redis/Mysql 中均有实现。只是实现方式不尽相同。
- LRU 算法【Least recently used(最近最少使用)】
- 根据数据的历史访问记录来进行淘汰数据,其核心思想是 "如果数据最近被访问过,那么将来被访问的几率也更高"。
二:单链表实现的 Lru 算法
- 思路
- 单链表实现
- 流程
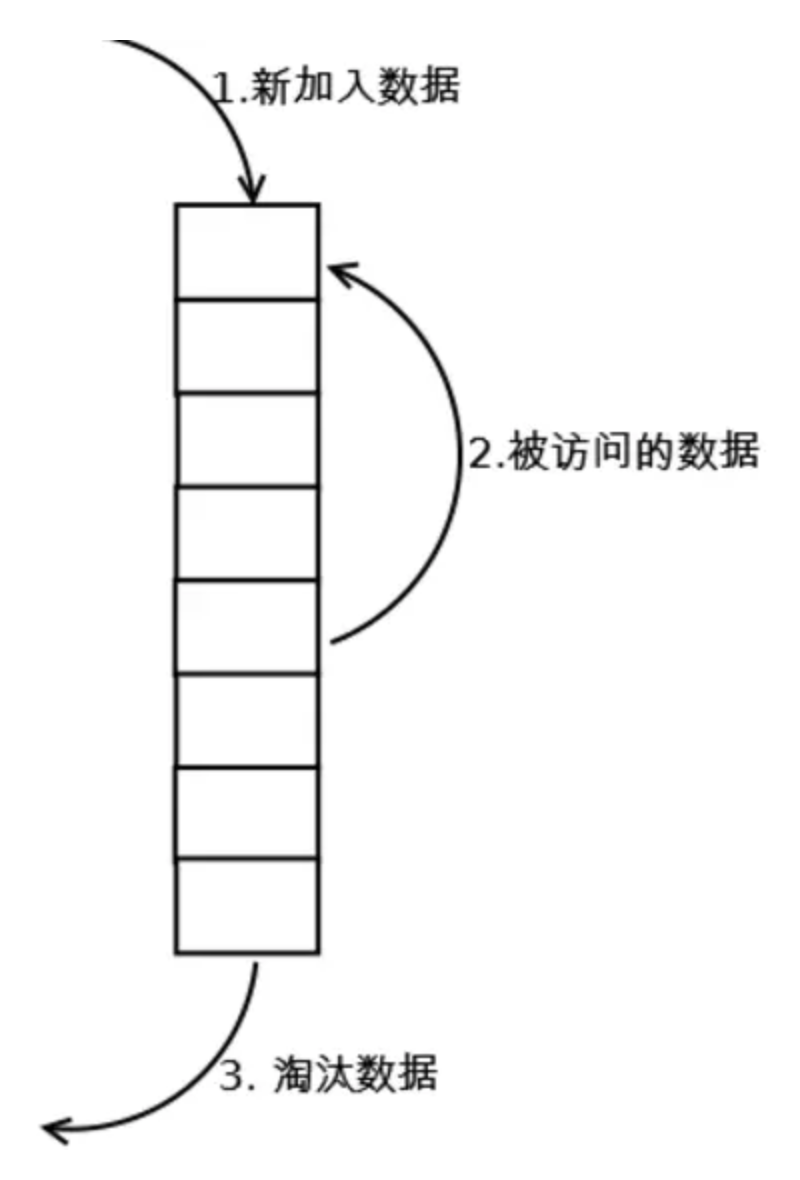
- 1. 新数据插入到链表头部;
- 2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 3. 当链表满的时候,将链表尾部的数据丢弃。
- 优点
- 实现简单。
- 当存在热点数据时,LRU的效率很好。
- 缺点
- 偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
- 命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
- 流程图
- 
- 代码实现(PHP)
/**
* 思路
* 单链表实现
* 原理
* 单链表
* 流程
* 1. 新数据插入到链表头部;
* 2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
* 3. 当链表满的时候,将链表尾部的数据丢弃。
* 优点
* 实现简单。
* 当存在热点数据时,LRU的效率很好。
* 缺点
* 偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
* 命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
*/
class Lru
{
public static $lruList = []; // 顺序存储单链表结构
public static $maxLen = ; // 链表允许最大长度
public static $nowLen = ; // 链表当前长度 /**
* LRU_1 constructor.
* 由于 PHP 不是常驻进程程序,所以链表初始化可以通过 Mysql/Redis 实现
*/
public function __construct()
{
self::$lruList = [];
self::$nowLen = count(self::$lruList);
} /**
* 获取 key => value
* @param $key
* @return null
*/
public function get($key)
{
$value = null; // lru 队列为空,直接返回
if (!self::$lruList) {
self::$lruList[] = [$key => $this->getData($key)]; // 根据实际项目情况获取数据
self::$nowLen++;
return $value;
} // 查找 lru 缓存
for ($i = ; $i < self::$nowLen; $i++) { // 如果存在缓存,则直接返回,并将数据重新插入链表头部
if (isset(self::$lruList[$i][$key])) { $value = self::$lruList[$i][$key]; unset(self::$lruList[$i]); array_unshift(self::$lruList, [$key => $value]); break;
}
} // 如果没有找到 lru 缓存
if (!isset($value)) { // 插入头部
array_unshift(self::$lruList, [$key => $this->getData($key)]); // 根据实际项目情况获取数据
self::$nowLen++; if (self::$nowLen > self::$maxLen) {
self::$nowLen--;
array_pop(self::$lruList);
}
} return $value; } /**
* 输出 Lru 队列
*/
public function echoLruList()
{
var_dump(self::$lruList);
} /**
* 根据真实环境获取数据
* @param $key
* @return string
*/
public function getData($key)
{
return 'data';
}
}
三:Lru K 算法
- 思路
- 为了避免 LRU 的 '缓存污染' 问题
- 增加一个队列来维护缓存出现的次数。其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
- 原理
- 相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
- 只有当数据的访问次数达到K次的时候,才将数据放入缓存。
- 当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据.
- 流程
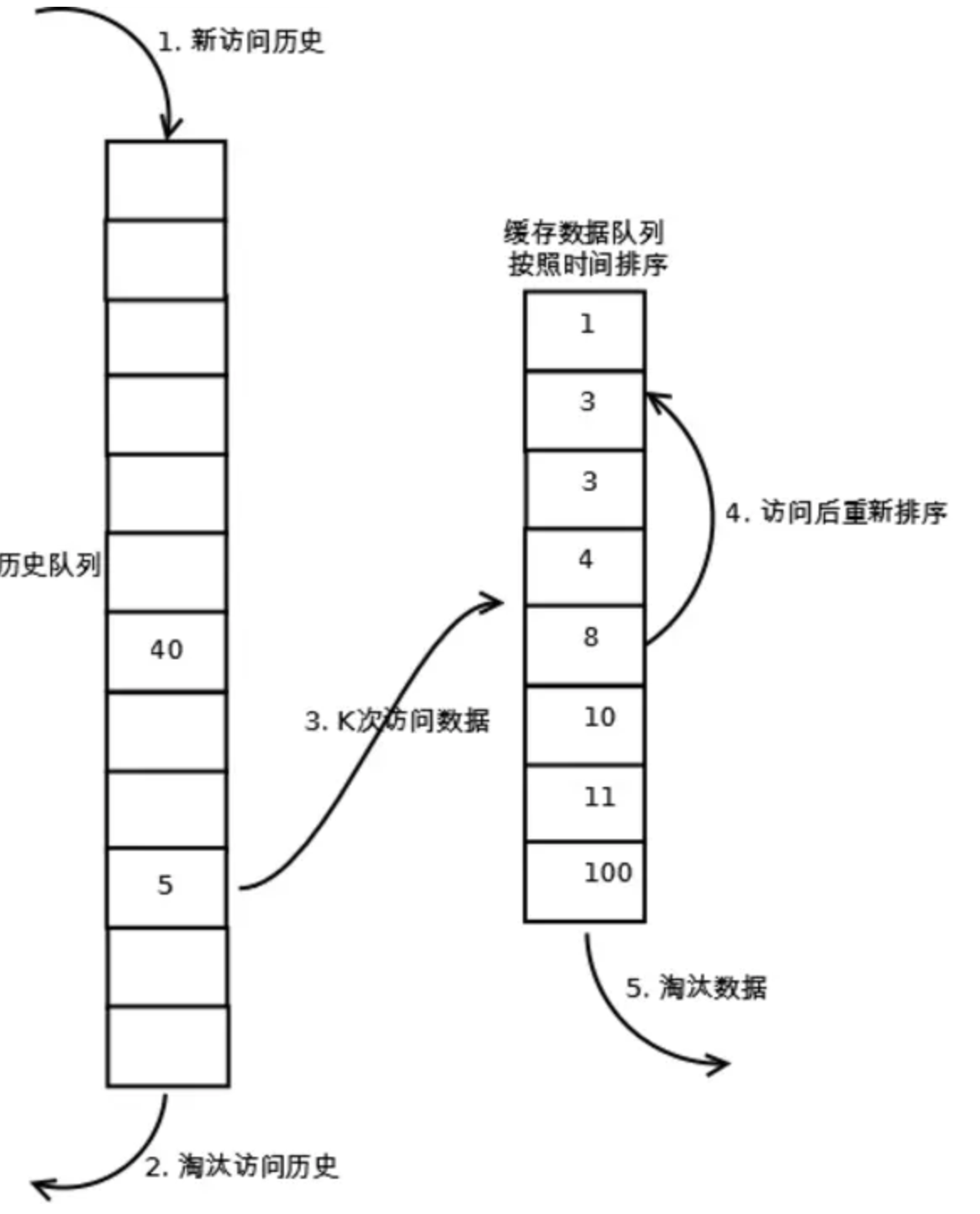
- 1.数据第一次被访问,加入到访问历史列表;
- 2.如果数据在访问历史列表里后没有达到K次访问,则按照一定规则 LRU淘汰;
- 3.当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
- 4.缓存数据队列中被再次访问后,重新排序;
- 5.需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
- 优点
- LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
- 缺点
- LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
- 由于LRU-K还需要维护历史队列,所以消耗的内存会更多。
- 流程图
- 
- 代码实现
/**
* 思路
* 为了避免 LRU 的 '缓存污染' 问题
* 增加一个队列来维护缓存出现的次数。其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
* 原理
* 相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
* 只有当数据的访问次数达到K次的时候,才将数据放入缓存。
* 当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据
* 流程
* 1.数据第一次被访问,加入到访问历史列表;
* 2.如果数据在访问历史列表里后没有达到K次访问,则按照一定规则 LRU淘汰;
* 3.当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
* 4.缓存数据队列中被再次访问后,重新排序;
* 5.需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
* 优点
* LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
* 缺点
* LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
* 由于LRU-K还需要维护历史队列,所以消耗的内存会更多。
*/
class Lru_K
{
public static $historyList = []; // 访问历史队列
public static $lruList = []; // 顺序存储单链表结构
public static $maxLen = ; // 链表允许最大长度
public static $nowLen = ; // 链表当前长度 /**
* LRU_K constructor.
* 由于 PHP 不是常驻进程程序,所以链表初始化可以通过 Mysql/Redis 实现
*/
public function __construct()
{
self::$lruList = [];
self::$historyList = [];
self::$nowLen = count(self::$lruList);
} /**
* 获取 key => value
* @param $key
* @return null
*/
public function get($key)
{
$value = null; // 查找 lru 缓存
for ($i = ; $i < self::$nowLen; $i++) { // 如果存在缓存,则直接返回,并将数据重新插入链表头部
if (isset(self::$lruList[$i][$key])) { $value = self::$lruList[$i][$key]; unset(self::$lruList[$i]); array_unshift(self::$lruList, [$key => $value]); break;
}
} // 如果没有找到 lru 缓存, 则进入历史队列进行计数,当次数大于等于5时候,进入缓存队列
if (!isset($value)) {
self::$historyList[$key]++; $value = $this->getData($key); // 进入缓存队列
if (self::$historyList[$key] >= ) {
array_unshift(self::$lruList, [$key => $value]); // 根据实际项目情况获取数据
self::$nowLen++; if (self::$nowLen > self::$maxLen) {
self::$nowLen--;
array_pop(self::$lruList);
} unset(self::$historyList[$key]); // 历史队列推出
}
} return $value; } /**
* 输出 Lru 队列
*/
public function echoLruList()
{
var_dump(self::$lruList);
var_dump(self::$historyList);
} /**
* 根据真实环境获取数据
* @param $key
* @return string
*/
public function getData($key)
{
return 'data';
}
}
《算法 - Lru算法》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- 基于麦克风阵列的声源定位算法之GCC-PHAT
目前基于麦克风阵列的声源定位方法大致可以分为三类:基于最大输出功率的可控波束形成技术.基于高分辨率谱图估计技术和基于声音时间差(time-delay estimation,TDE)的声源定位技术. 基 ...
- LeetCode 855. Exam Room
原题链接在这里:https://leetcode.com/problems/exam-room/ 题目: In an exam room, there are N seats in a single ...
- s3git 使用git 管理云存储
使用s3git 我们可以方便的基于git协议进行s3存储数据的版本管理,同时也提供了一个方便的golang 包, 我们可以集成到我们的应用中,但是有一点,目前已经没有再更新过了,但是设计理论很不错,实 ...
- THUWC2020 划船记
PS:THUWC2020在2019年 Day 1 考场外的太懒了不写了. 三题题目大意: T1: T2: 给定一个\(n(\leq 10^5)\)个结点的有向图,每条边有个limit,表示经过这条边l ...
- lower_bound( )和upper_bound( )怎么用嘞↓↓↓
lower_bound( )和upper_bound( )都是利用二分查找的方法在一个排好序的数组中进行查找的. 在从小到大的排序数组中, lower_bound( begin,end,num):从数 ...
- mysql find_in_set 函数 使用方法
mysql> select * from user; +------+----------+-----------+ | id | name | address | +------+------ ...
- 【牛客】小w的魔术扑克 (并查集?? 树状数组)
题目描述 小w喜欢打牌,某天小w与dogenya在一起玩扑克牌,这种扑克牌的面值都在1到n,原本扑克牌只有一面,而小w手中的扑克牌是双面的魔术扑克(正反两面均有数字,可以随时进行切换),小w这个人就准 ...
- element ui里面table分页,页数从0开始的怎么做?
需求: 后台请求的接口是从0页开始的,但是pagination是从1开始的,就是在点击pagination的第1页是后台转0 1首先在data里面定义为1,其他地方也是定义1 return { for ...
- ICEM——对msh文件或者cas文件重新划分边界
原视频下载地址:https://pan.baidu.com/s/1jIoKSuy 密码: m3uv
- 卸载nginx之后重新安装
Ubuntu 14.04上卸载nginx之后重新安装没有重新生成配置文件的解决方法 在配置nginx做实验时配置错了,导致访问不了虚拟主机.一狠心把nginx的配置文件目录(/etc/nginx)都删 ...