Scrapy爬豆瓣电影Top250并存入MySQL数据库
d:
进入D盘
scrapy startproject douban
创建豆瓣项目
cd douban
进入项目
scrapy genspider douban_spider movie.douban.com
创建爬虫
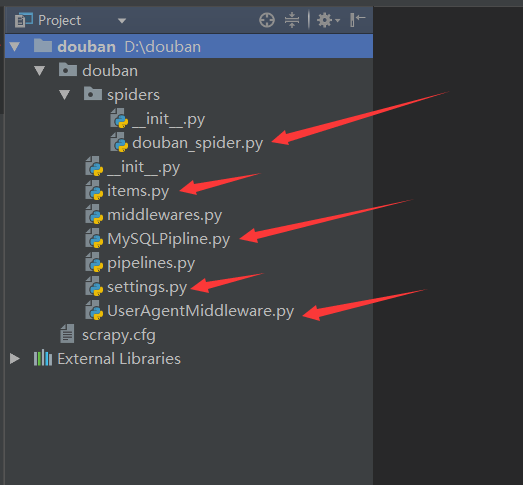
编辑items.py:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() serial_number = scrapy.Field()
# 序号
movie_name = scrapy.Field()
# 电影的名称
introduce = scrapy.Field()
# 电影的介绍
star = scrapy.Field()
# 星级
evaluate = scrapy.Field()
# 电影的评论数
depict = scrapy.Field()
# 电影的描述
编辑douban_spider.py:
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 爬虫的名字
allowed_domains = ['movie.douban.com']
# 允许的域名
start_urls = ['https://movie.douban.com/top250']
# 引擎入口url,扔到调度器里面去 def parse(self, response):
# 默认的解析方法
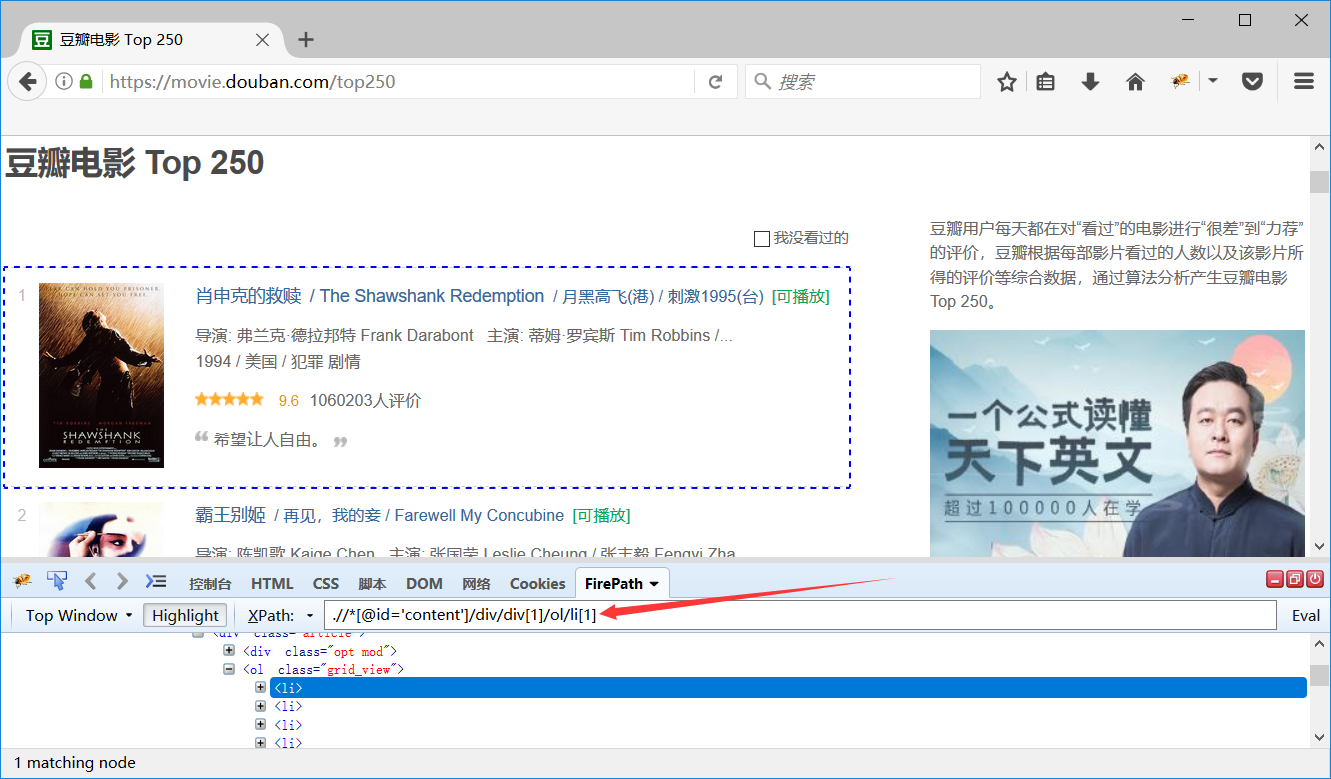
movie_list = response.xpath(".//*[@id='content']/div/div[1]/ol/li")
# 第一页展示的电影的列表
for i_item in movie_list:
# 循环电影的条目
douban_item = DoubanItem()
# 实例化DoubanItem()
douban_item["serial_number"] = i_item.xpath(".//div/div[1]/em/text()").extract_first()
douban_item["movie_name"] = i_item.xpath(".//div/div[2]/div[1]/a/span[1]/text()").extract_first()
content = i_item.xpath(".//div/div[2]/div[2]/p[1]/text()").extract()
for i_content in content:
# 处理电影的介绍中的换行的数据
content_s = "".join(i_content.split())
douban_item["introduce"] = content_s douban_item["star"] = i_item.xpath(".//div/div[2]/div[2]/div/span[2]/text()").extract_first()
douban_item["evaluate"] = i_item.xpath(".//div/div[2]/div[2]/div/span[4]/text()").extract_first()
douban_item["depict"] = i_item.xpath(".//div/div[2]/div[2]/p[2]/span/text()").extract_first() yield douban_item
# 需要把数据yield到pipelines里面去 next_link = response.xpath(".//*[@id='content']/div/div[1]/div[2]/span[3]/a/@href").extract()
# 解析下一页,取后页的xpath
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250" + next_link, callback=self.parse)
新建MySQLPipline.py:
from pymysql import connect class MySQLPipeline(object):
def __init__(self):
self.connect = connect(
host='192.168.1.23',
port=3306,
db='scrapy',
user='root',
passwd='Abcdef@123456',
charset='utf8',
use_unicode=True)
# 连接数据库
self.cursor = self.connect.cursor()
# 使用cursor()方法获取操作游标 def process_item(self, item, spider):
self.cursor.execute(
"""insert into douban(serial_number, movie_name, introduce, star, evaluate, depict)
value (%s, %s, %s, %s, %s, %s)""",
(item['serial_number'],
item['movie_name'],
item['introduce'],
item['star'],
item['evaluate'],
item['depict']
))
# 执行sql语句,item里面定义的字段和表字段一一对应
self.connect.commit()
# 提交
return item
# 返回item def close_spider(self, spider):
self.cursor.close()
# 关闭游标
self.connect.close()
# 关闭数据库连接
新建UserAgentMiddleware.py:
import random class UserAgentMiddleware(object):
def process_request(self, request, spider):
user_agent_list = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
]
agent = random.choice(user_agent_list)
request.headers["User-Agent"] = agent
修改settings.py配置文件:
第57行修改为:
DOWNLOADER_MIDDLEWARES = {
'douban.UserAgentMiddleware.UserAgentMiddleware': 543,
}
# 启用middleware
第69行修改为:
ITEM_PIPELINES = {
'douban.MySQLPipline.MySQLPipeline': 300,
}
# 启用pipeline
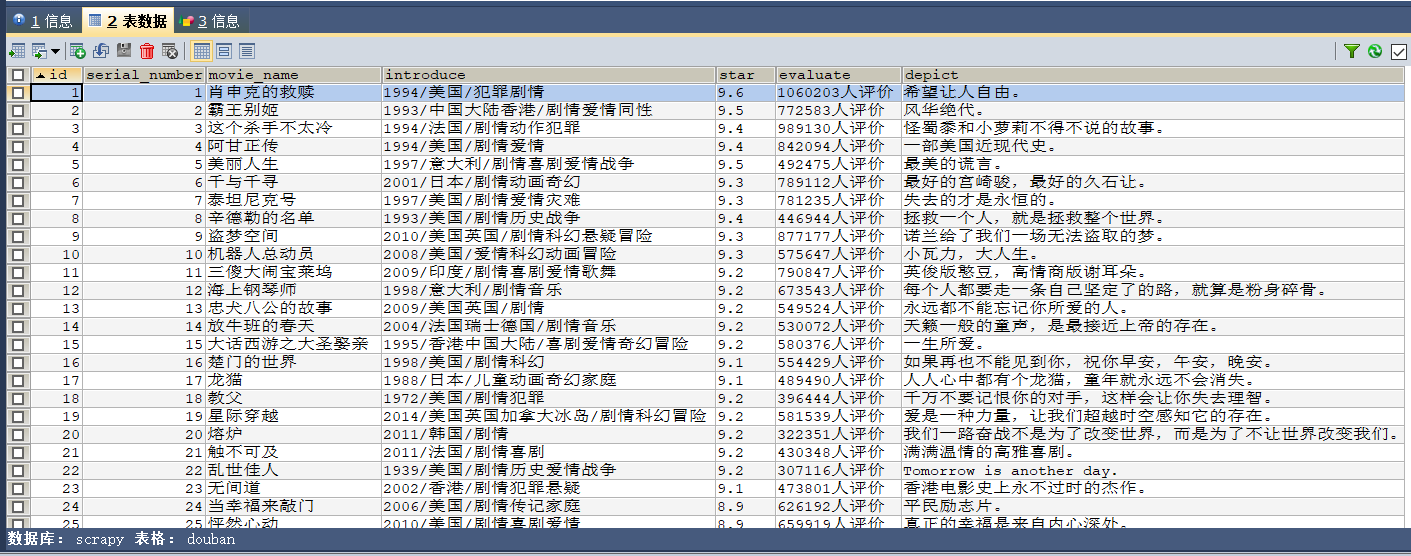
CREATE DATABASE scrapy;
创建数据库
CREATE TABLE `douban` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`serial_number` INT(11) DEFAULT NULL COMMENT '序号',
`movie_name` VARCHAR(255) DEFAULT NULL COMMENT '电影的名称',
`introduce` VARCHAR(255) DEFAULT NULL COMMENT '电影的介绍',
`star` VARCHAR(255) DEFAULT NULL COMMENT '星级',
`evaluate` VARCHAR(255) DEFAULT NULL COMMENT '电影的评论数',
`depict` VARCHAR(255) DEFAULT NULL COMMENT '电影的描述',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT '豆瓣表';
创建表
scrapy crawl douban_spider --nolog
运行爬虫(不打印日志)
Scrapy爬豆瓣电影Top250并存入MySQL数据库的更多相关文章
- python之scrapy爬取jingdong招聘信息到mysql数据库
1.创建工程 scrapy startproject jd 2.创建项目 scrapy genspider jingdong 3.安装pymysql pip install pymysql 4.set ...
- [151116 记录] 使用Python3.5爬取豆瓣电影Top250
这一段时间,一直在折腾Python爬虫.已有的文件记录显示,折腾爬虫大概个把月了吧.但是断断续续,一会儿鼓捣python.一会学习sql儿.一会调试OpenCV,结果什么都没学好.前几天,终于耐下心来 ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架--Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影To ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集及MySQL数据库操作
转载请注明出处 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集 1.任务 采集豆瓣电影名称.链接.评分.导演.演员.年份.国家.评论人数.简评等信息 将以上数据存入MySQL数 ...
随机推荐
- Tomcat中日志组件
Tomcat日志组件 AccessLog接口 public interface AccessLog { public void log(Request request, Response respon ...
- C# windows服务安装及卸载
--C# windows服务安装及卸载 保存BAT文件 执行即可 @SET FrameworkDir=%WINDIR%\Microsoft.NET\Framework@SET Framework ...
- ts简单点
typescript 简洁使用 *做最简洁核心的记录,可以节约时间.再是提炼概括,理解归纳.便于日后查阅联想* > typescript原则之一: 对值所具有的结构进行类型检查 #### 基础类 ...
- [iOS]被忽略的main函数
如同任何基于C的应用程序,程序启动的主入口点为iOS应用程序的main函数.在iOS应用程序,main函数的作用是很少的.它的主要工作是控制UIKit framework.因此,你在Xcode中创建任 ...
- Extjs 中callParent的作用
callParent 是 Sencha 类系统提供的一个用于调用你父/祖先类中的方法. 这个通常用于当你 继承一个框架类 或者 覆写一个类中提供的方法(比如 onRender) 时. 当你在一个带参数 ...
- Tarjan算法初探(3):求割点与桥以及双连通分量
接上一节Tarjan算法初探(2):缩点 在此首先提出几个概念: 割点集合:一个无向连通图G 若删除它的一个点集 以及点集中所有点相连的边(任意一端在点集中)后 G中有点之间不再连通则称这个点集是它的 ...
- MVC三层架构的分层开发思想
- 关于IScroll使用中的常见问题与解决方案
1.在iscroll4的滚动容器范围内,点击input框.select等表单元素时没有响应这个问题原因在于iscroll需要一直监听用户的touch操作,以便灵敏的做出对应效果,所以它把其余的默认事件 ...
- java 一个数字的位数不够怎么在前面加0
import java.text.DecimalFormat; //(1).如果数字1是字符串,如下处理: String str1="1"; DecimalFormat df=ne ...
- linux不重启挂载磁盘安装grub
挂载.分区.grub 通过给一块新磁盘安装grub回顾磁盘挂载.分区文件系统创建等操作: 该实验基于(CtonOS6.8:kernel:2.6.32-642.15.1.el6.x86_64) 1.通过 ...