HDFS原理解析
一、HDFS简介
HDFS为了做到可靠性(reliability)创建了多分数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(computer nodes),MapReduce就可以在它们所在的节点上处理这些数据了。
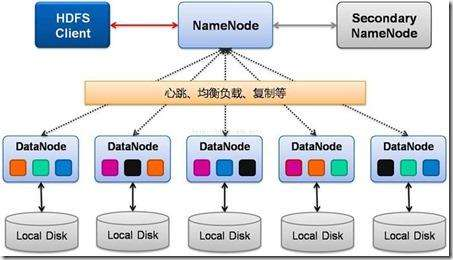
1.1 HDFS数据存储单元(block)
- 文件被切分成固定大小的数据块
- 默认数据块大小为64M(Hadoop 2.x默认为128M),可配置
- 若文件大小不足64M,则单纯存为一个block
- 文件存储方式
- 按大小被切分成若干个block,存储到不同的节点上
- 默认情况下每个block都有三个副本
- Block的大小和副本数通过client端上传文件时设置,文件上传成功后副本数可以变更,block size不可变更
1.2 Namenode(NN)
- NameNode主要功能:接收客户端的读写服务
- NameNode保存metadata信息包括
- 文件owership和permissions
- 文件包含哪些块
- Block保存在哪些DataNode(由DataNode启动时上报)
- NameNode的metadata信息在启动后会加载到内存
- metadata存储到磁盘文件名为 fsimage
- Block的位置信息不会保存到 fsimage
- edits文件记录了对metadata的操作日志
1.3 DataNode(DN)
存储数据(Block)
- 启动DN线程的时候回向NN汇报block信息
- 通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟内没有收到DN的心跳,则认为其已经lost,并copy其上的block到其他的DN
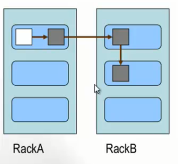
1.2.1 Block的副本放置策略
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在与第一个副本不同的机架上的节点上。
第三个副本:放置在与第二个副本相同机架的节点。
更多副本:随机节点
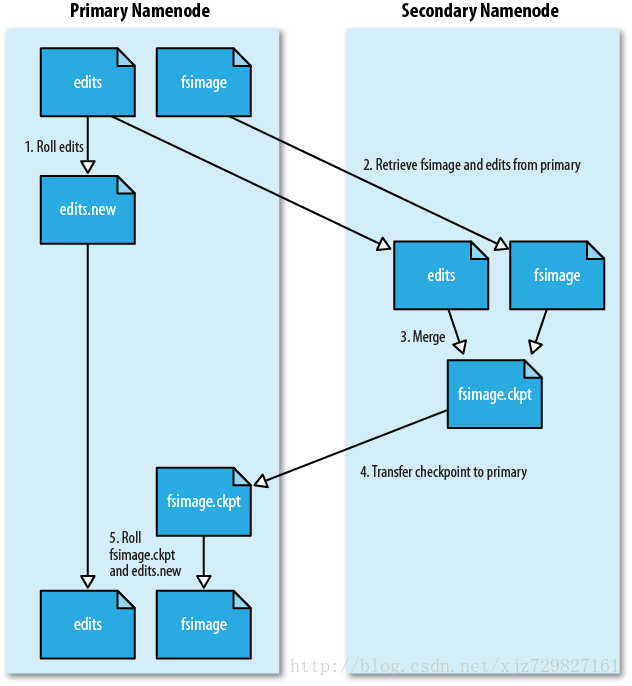
1.4 SecondNameNode
- 它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
- SNN执行合并时机
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值,默认64M
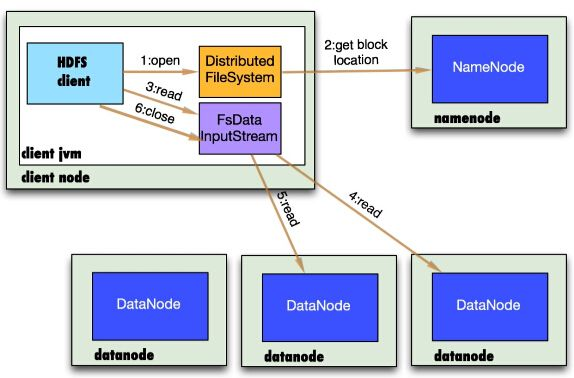
1.5 HDFS读流程
1.6 HDFS写流程
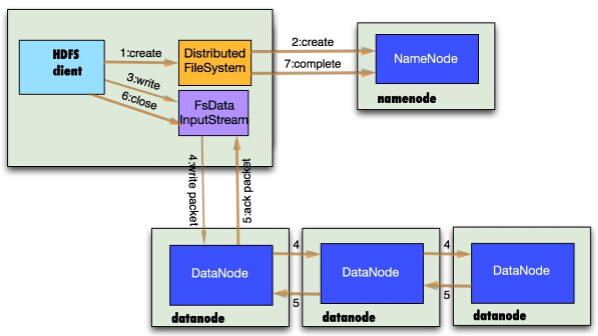
1.7 HDFS优缺点:
优点:
- 高容错性
- 数据自动保存多个副本
- 副本丢失后,自动回复
- 适合批处理适合大数据处理
- 移动计算而非数据
- 数据位置暴露给计算框架
- 可构架在廉价机器上
缺点:
- 低延迟数据访问
- 比如毫秒级
- 低延迟与高吞吐率
- 小文件存取
- 占用NameNode大量内存
- 寻道时间超过读取时间
- 并发写入、文件随机修改
- 一个文件只能有一个写者
- 仅支持append
二、HDFS2.x
2.1 Hadoop 2.0产生背景
- Hadoop1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
- HDFS存在的问题
- NameNode单点故障,男衣应用于在线场景
- NameNode压力过大,且内存受限,影响系统扩展性
- MapReduce存在的问题
- JboTracker访问压力大,影响系统扩展性
- 难以支持除MapReduce之外的计算框架,比如Spark、Storm等
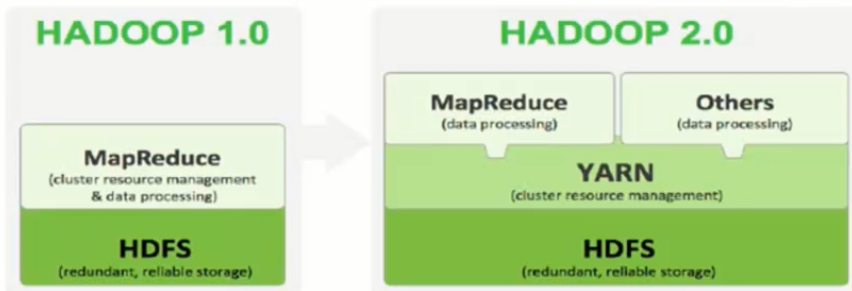
- Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成
- HDFS:NN Federation、HA
- MapReduce:运行在YARN上的MR
- YARN:资源管理系统
2.2 HDFS 2.x特点
- 解决HDFS 1.0中单点故障和内存受限问题
- 解决单点故障
- HDFS HA:通过主备NameNode解决
- 如果主NameNode发生故障,则切换到备NameNode上
- 解决内存受限问题
- HDFS Federation(联邦)
- 水平扩展,支持多个NameNode
- 每个NameNode分管一部分目录
- 所有NameNode共享所有的DataNode存储资源
- 2.x仅是架构上发生了变化,使用方式不变
- 对HDFS使用者透明
- HDFS1.x中的命令和API仍可以使用
2.3 HDFS 2.x HA
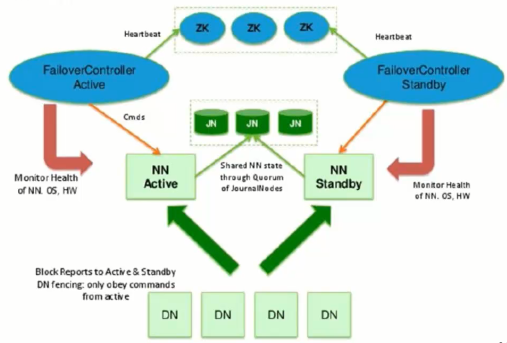
- 主备NameNode
- 解决单点故障
- 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
- 所有DataNode同时向两个NameNode汇报数据块信息
- 两种切换选择
- 手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
- 自动切换:基于Zookeeper实现
- 基于Zookeeper自动切换方案
- Zookeeper Failover Controller:监控NameNode健康状态
- 并向Zookeeper注册NameNode
- NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC锁的NameNode变为active
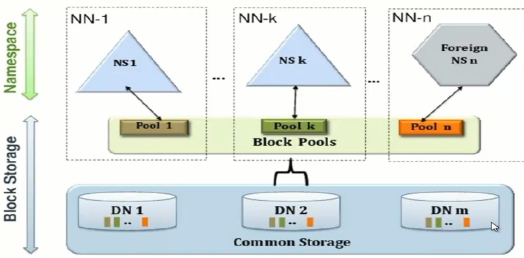
2.4 HDFS 2.x Federation
- 通过多个NameNode/namespace把元数据的存储和管理分散到多个节点中,使得NameNode/namespace可以通过增加机器来进行水平扩展。
- 能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会降低HDFS的性能。可以通过多个namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中。
2.5 YARN
- YARN:Yet Another Resource Negotiator
- Hadoop 2.0新引入的资源管理系统,直接从MRv1演化二来的
- 核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现
- ResourceManager:负责整个集群的资源管理和调度
- ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等
- YARN的引入,使得多个计算框架可运行在一个集群中
- 每个应用程序对应一个ApplicationMaster
- 目前多个计算框架可以运行在YARN中,比如MapReduce、Spark、Storm等
2.6 MapReduce On YARN
- MapReduce On YARN:MRv2
- 将MapReduce作业直接运行在YARN中,而不是由JobTracker和TaskTracker构建的MRv1中
- 基本功能模块
- YARN:复制资源管理和调度
- MRAppMaster:负责任务切分、任务调度、任务监控和容错等
- MapTask/ReduceTask:任务驱动引擎,与MRv1一致
- 每个MapReduce作业对应一个MRAppMaster
- MRAppMaster任务调度
- YARN将资源分配给MRAppMaster
- MRAppMaster进一步将资源分配给内部的任务
- MRAppMaster容错
- 失败后,由YARN重新启动
- 任务失败后,MRAppMaster重新申请资源
HDFS原理解析的更多相关文章
- HDFS 原理解析
源自https://www.cnblogs.com/duanxz/p/3874009.html Namenode是整个文件系统的管理节点.它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件 ...
- HDFS原理解析(总体架构,读写操作流程)
前言 HDFS 是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统.是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和 存储空间.让实际上是通过网络来访问文件 ...
- HDFS原理解析(整体架构,读写操作流程及源代码查看等)
前言 HDFS 是一个能够面向大规模数据使用的.可进行扩展的文件存储与传递系统.是一种同意文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间.让实际上是通过网络来訪问文件的 ...
- HDFS之四:HDFS原理解析(总体架构,读写操作流程)
前言 HDFS 是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统.是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和 存储空间.让实际上是通过网络来访问文件 ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- HDFS 原理、架构与特性介绍
本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前HDFS架构详尽分析 HDFS架构 •NameNode •DataNode •Senc ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
随机推荐
- 最新版chrome浏览器如何离线安装crx插件?(转载)
原文链接:https://newsn.net/say/chrome-crx-offline.html mac新版chrome开启离线插件安装 对于mac新版chrome,注意,大家一定要按照顺序来.m ...
- 博客主题皮肤探索-主题的本地化和ChromeCacheView使用
还有前言 用了大佬的主题之后,有些资源是无法在暴露的接口处更改的,需要自己去css更改.但后台给的都是压缩过的,找起来比较困难,所以特意记录了这篇. 本地资源替换 侧边栏: .introduce-bo ...
- 20190416 OSX系统使用VMware Fusion安装CentOS7踩的那些坑
一.创建虚拟机 (1)在虚拟机资源库中点击[+添加]按钮,选择“新建...”选项 (2)选择创建自定义虚拟机 (3)选择系统类型为CentOS (4)选择虚拟磁盘类型 (5)选择虚拟机存储位置:点击[ ...
- io流之转换流InputStreamReader、OutputStreamWriter
例子程序: package io; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.File ...
- 在Android中调用KSOAP2库访问webservice服务出现的服务端传入参数为null的问题解决
ksoap2-android-3.0.0-jar 第三方库来调用.net 写的Web Service 如果没有参数,那么调用一切顺利,但是如果服务是带参数的,那么服务端接收的参数都是nul. ...
- InnoDB的B+树索引使用
何时使用索引 并不是在所有的查询条件下出现的列都需要添加索引.对于什么时候添加B+树索引,我的经验是访问表中很少一部分行时,使用B+树索引才有意义.对于性别字段.地区字段.类型字段,它们可取值的范围很 ...
- TimerJob无法发布新版本问题
最近遭遇发布TimerJob在测试环境发布没有问题,但是到正式环境发布总是无法执行及调试的问题,经过几天的努力,终于解决了这个问题,下面记录下遭遇的问题. Windows 2008,SharePoin ...
- Entity Framework 6.0 Code First(转)
源自:http://www.cnblogs.com/panchunting/tag/Code%20First/ 1 Conventions 2 Custom Conventions 3 Data An ...
- 10种jquery选择器操作详解(转)
jquery选择器大体上可分为4 类: 1.基本选择器2.层次选择器3.过滤选择器4.表单选择器 其中过滤选择器可以分为:1.简单过滤选择器2.内容过滤选择器3.可见性过滤选择器4.属性过滤选择器5. ...
- 【LeetCode题解】94_二叉树的中序遍历
目录 [LeetCode题解]94_二叉树的中序遍历 描述 方法一:递归 Java 代码 Python代码 方法二:非递归 Java 代码 Python 代码 [LeetCode题解]94_二叉树的中 ...