[CLPR]BP神经网络的C++实现
文章翻译自: http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi
如何在C++中实现一个神经网络类?
主要有四个不同的类需要我们来考虑:
- 层 - layers
- 层中的神经元 - neurons
- 神经元之间的连接 - connections
- 连接的权值 - weights
这四类都在下面的代码中体现, 集中应用于第五个类 - 神经网络(neural network)上. 它就像一个容器, 用于和外部交流的接口. 下面的代码大量使用了STL的vector.
// simplified view: some members have been omitted,
// and some signatures have been altered // helpful typedef's typedef std::vector< NNLayer* > VectorLayers;
typedef std::vector< NNWeight* > VectorWeights;
typedef std::vector< NNNeuron* > VectorNeurons;
typedef std::vector< NNConnection > VectorConnections; // Neural Network class class NeuralNetwork
{
public:
NeuralNetwork();
virtual ~NeuralNetwork(); void Calculate( double* inputVector, UINT iCount,
double* outputVector = NULL, UINT oCount = ); void Backpropagate( double *actualOutput,
double *desiredOutput, UINT count ); VectorLayers m_Layers;
}; // Layer class class NNLayer
{
public:
NNLayer( LPCTSTR str, NNLayer* pPrev = NULL );
virtual ~NNLayer(); void Calculate(); void Backpropagate( std::vector< double >& dErr_wrt_dXn /* in */,
std::vector< double >& dErr_wrt_dXnm1 /* out */,
double etaLearningRate ); NNLayer* m_pPrevLayer;
VectorNeurons m_Neurons;
VectorWeights m_Weights;
}; // Neuron class class NNNeuron
{
public:
NNNeuron( LPCTSTR str );
virtual ~NNNeuron(); void AddConnection( UINT iNeuron, UINT iWeight );
void AddConnection( NNConnection const & conn ); double output; VectorConnections m_Connections;
}; // Connection class class NNConnection
{
public:
NNConnection(UINT neuron = ULONG_MAX, UINT weight = ULONG_MAX);
virtual ~NNConnection(); UINT NeuronIndex;
UINT WeightIndex;
}; // Weight class class NNWeight
{
public:
NNWeight( LPCTSTR str, double val = 0.0 );
virtual ~NNWeight(); double value;
};
类NeuralNetwork存储的是一个指针数组, 这些指针指向NN中的每一层, 即NNLayer. 没有专门的函数来增加层, 只需要使用std::vector::push_back()即可. NeuralNetwork类提供了两个基本的接口, 一个用来得到输出(Calculate), 一个用来训练(Backpropagete).
每一个NNLayer都保存一个指向前一层的指针, 使用这个指针可以获取上一层的输出作为输入. 另外它还保存了一个指针向量, 每个指针指向本层的神经元, 即NNNeuron, 当然, 还有连接的权值NNWeight. 和NeuralNetwork相似, 神经元和权值的增加都是通过std::vector::push_back()方法来执行的. NNLayer层还包含了函数Calculate()来计算神经元的输出, 以及Backpropagate()来训练它们. 实际上, NeuralNetwork类只是简单地调用每层的这些函数来实现上小节所说的2个同名方法.
每个NNNeuron保存了一个连接数组, 使用这个数组可以使得神经元能够获取输入. 使用NNNeuron::AddConnection()来增加一个Connection, 输入神经元的标号和权值的标号, 从而建立一个NNConnection对象, 并将它push_back()到神经元保存的连接数组中. 每个神经元同样保存着它自己的输出值(double). NNConnection和NNWeight类分别存储了一些信息.
你可能疑惑, 为何权值和连接要分开定义? 根据上述的原理, 每个连接都有一个权值, 为何不直接将它们放在一个类里?
原因是: 权值经常被连接共享.
实际上, 在卷积神经网络中就是共享连接的权值的. 所以, 举例来说, 就算一层可能有几百个神经元, 权值却可能只有几十个. 通过分离这两个概念, 这种共享可以很轻易地实现.
前向传递
前向传递是指所有的神经元基于接收的输入, 计算输出的过程.
在代码中, 这个过程通过调用NeuralNetwork::Calculate()来实现. NeuralNetwork::Calculate()直接设置输入层的神经元的值, 随后迭代剩下的层, 调用每一层的NNLayer::Calculate(). 这就是所谓的前向传递的串行实现方式. 串行计算并非是实现前向传递的唯一方法, 但它是最直接的. 下面是一个简化后的代码, 输入一个代表输入数据的C数组和一个代表输出数据的C数组.
// simplified code void NeuralNetwork::Calculate(double* inputVector, UINT iCount,
double* outputVector /* =NULL */,
UINT oCount /* =0 */) {
VectorLayers::iterator lit = m_Layers.begin();
VectorNeurons::iterator nit; // 第一层是输入层:
// 直接设置所有的神经元输出为给定的输入向量即可 if ( lit < m_Layers.end() )
{
nit = (*lit)->m_Neurons.begin();
int count = ; ASSERT( iCount == (*lit)->m_Neurons.size() );
// 输入和神经元个数应当一一对应 while( ( nit < (*lit)->m_Neurons.end() ) && ( count < iCount ) )
{
(*nit)->output = inputVector[ count ];
nit++;
count++;
}
} // 调用Calculate()迭代剩余层 for( lit++; lit<m_Layers.end(); lit++ )
{
(*lit)->Calculate();
} // 使用结果设置每层输出 if ( outputVector != NULL )
{
lit = m_Layers.end();
lit--; nit = (*lit)->m_Neurons.begin(); for ( int ii=; ii<oCount; ++ii )
{
outputVector[ ii ] = (*nit)->output;
nit++;
}
}
}
在层中的Calculate()函数中, 层会迭代其中的所有神经元, 对于每一个神经元, 它的输出通过前馈公式给出: 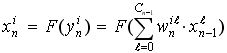
这个公式通过迭代每个神经元的所有连接来实现, 获取对应的权重和对应的前一层神经元的输出. 如下:
// simplified code void NNLayer::Calculate()
{
ASSERT( m_pPrevLayer != NULL ); VectorNeurons::iterator nit;
VectorConnections::iterator cit; double dSum; for( nit=m_Neurons.begin(); nit<m_Neurons.end(); nit++ )
{
NNNeuron& n = *(*nit); // 取引用 cit = n.m_Connections.begin(); ASSERT( (*cit).WeightIndex < m_Weights.size() ); // 第一个权值是偏置
// 需要忽略它的神经元下标 dSum = m_Weights[ (*cit).WeightIndex ]->value; for ( cit++ ; cit<n.m_Connections.end(); cit++ )
{
ASSERT( (*cit).WeightIndex < m_Weights.size() );
ASSERT( (*cit).NeuronIndex <
m_pPrevLayer->m_Neurons.size() ); dSum += ( m_Weights[ (*cit).WeightIndex ]->value ) *
( m_pPrevLayer->m_Neurons[
(*cit).NeuronIndex ]->output );
} n.output = SIGMOID( dSum ); } }
SIGMOID是一个宏定义, 用于计算激励函数.
反向传播
BP是从最后一层向前移动的一个迭代过程. 假设在每一层我们都知道了它的输出误差. 如果我们知道输出误差, 那么修正权值来减少这个误差就不难. 问题是我们只能观测到最后一层的误差.
BP给出了一种通过当前层输出计算前一层的输出误差的方法. 它是一种迭代的过程: 从最后一层开始, 计算最后一层权值的修正, 然后计算前一层的输出误差, 反复.
BP的公式在下面. 代码中就用到了这个公式. 距离来说, 第一个公式告诉了我们如何去计算误差EP对于激励值yi的第n层的偏导数. 代码中, 这个变量名为dErr_wrt_dYn[ ii ].
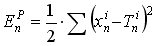
对于最后一层神经元的输出, 计算一个单输入图像模式的误差偏导的方法如下:
(equation 1)
其中, 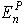 是对于模式P再第n层的误差,
是对于模式P再第n层的误差, 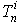 是最后一层的期望输出,
是最后一层的期望输出, 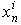 是最后一层的实际输出.
是最后一层的实际输出.
给定上式, 我们可以得到偏导表达式:
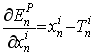 (equation 2)
(equation 2)
式2给出了BP过程的起始值. 我们使用这个数值作为式2的右值从而计算偏导的值. 使用偏导的值, 我们可以计算权值的修正量, 通过应用下式:
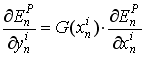 (equation 3), 其中
(equation 3), 其中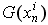 是激励函数的导数.
是激励函数的导数.
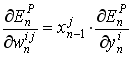 (equation 4)
(equation 4)
使用式2和式3, 我们可以计算前一层的误差, 使用下式5:
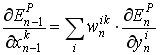 (equation 5)
(equation 5)
从式5中获取的值又可以立刻用作前一层的起始值. 这是BP的核心所在.
式4中获取的值告诉我们该如何去修正权值, 按照下式:
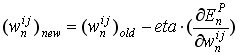 (equation 6)
(equation 6)
其中eta是学习速率, 常用值是0.0005, 并随着训练减小.
本代码中, 上述等式在NeuralNetwork::Backpropagate()中实现. 输入实际上是神经网络的实际输出和期望输出. 使用这两个输入, NeuralNetwork::Backpropagate()计算式2的值并迭代所有的层, 从最后一层一直迭代到第一层. 对于每层, 都调用了NNLayer::Backpropagate(). 输入是梯度值, 输出则是式5.
这些梯度都保存在一个两维数组differentials中.
本层的输出则作为前一层的输入.
// simplified code
void NeuralNetwork::Backpropagate(double *actualOutput,
double *desiredOutput, UINT count)
{
// 神经网络的BP过程,
// 从最后一层迭代向前处理到第一层为止.
// 首先, 单独计算最后一层,
// 因为它提供了前一层所需的梯度信息
// (i.e., dErr_wrt_dXnm1) // 变量含义:
//
// Err - 整个NN的输出误差
// Xn - 第n层的输出向量
// Xnm1 - 前一层的输出向量
// Wn - 第n层的权值向量
// Yn - 第n层的激励函数输入值
// 即, 在应用压缩函数(squashing function)前的权值和// F - 挤压函数: Xn = F(Yn)
// F' - 压缩函数(squashing function)的梯度
// 比如, 令 F = tanh,
// 则 F'(Yn) = 1 - Xn^2, 梯度可以通过输出来计算, 不需要输入信息 VectorLayers::iterator lit = m_Layers.end() - ; // 取最后一层 std::vector< double > dErr_wrt_dXlast( (*lit)->m_Neurons.size() ); // 记录后层神经元误差对输入的梯度
std::vector< std::vector< double > > differentials; //记录每一层输出对输入的梯度 int iSize = m_Layers.size(); // 层数 differentials.resize( iSize ); int ii; // 计算最后一层的 dErr_wrt_dXn 来开始整个迭代.
// 对于标准的MSE方程
// (比如, 0.5*sumof( (actual-target)^2 ),
// 梯度表达式就仅仅是期望和实际的差: Xn - Tn for ( ii=; ii<(*lit)->m_Neurons.size(); ++ii )
{
dErr_wrt_dXlast[ ii ] =
actualOutput[ ii ] - desiredOutput[ ii ];
} // 保存 Xlast 并分配内存存储剩余的梯度 differentials[ iSize- ] = dErr_wrt_dXlast; // 最后一层的梯度 for ( ii=; ii<iSize-; ++ii )
{
differentials[ ii ].resize(
m_Layers[ii]->m_Neurons.size(), 0.0 );
} // 迭代每个层, 包括最后一层但不包括第一层
// 同时求得每层的BP误差并矫正权值// 返回梯度dErr_wrt_dXnm1用于下一次迭代 ii = iSize - ;
for ( lit; lit>m_Layers.begin(); lit--)
{
(*lit)->Backpropagate( differentials[ ii ],
differentials[ ii - ], m_etaLearningRate ); // 调用每一层的BP接口
--ii;
} differentials.clear();
}
在NNLayer::Backpropagate()中, 层实现了式3~5, 计算出了梯度. 实现了式6来更新本层的权重. 在下面的代码中, 激励函数的梯度被定义为 DSIGMOID.
// simplified code void NNLayer::Backpropagate( std::vector< double >& dErr_wrt_dXn /* in */,
std::vector< double >& dErr_wrt_dXnm1 /* out */,
double etaLearningRate )
{
double output; // 计算式 (3): dErr_wrt_dYn = F'(Yn) * dErr_wrt_Xn for ( ii=; ii<m_Neurons.size(); ++ii ) // 遍历所有神经元
{
output = m_Neurons[ ii ]->output; // 神经元输出 dErr_wrt_dYn[ ii ] = DSIGMOID( output ) * dErr_wrt_dXn[ ii ]; // 误差对输入的梯度
} // 计算式 (4): dErr_wrt_Wn = Xnm1 * dErr_wrt_Yn
// 对于本层的每个神经元, 遍历前一层的连接
// 更新对应权值的梯度 ii = ;
for ( nit=m_Neurons.begin(); nit<m_Neurons.end(); nit++ ) // 迭代本层所有神经元
{
NNNeuron& n = *(*nit); // 取引用 for ( cit=n.m_Connections.begin(); cit<n.m_Connections.end(); cit++ ) // 遍历每个神经元的后向连接
{
kk = (*cit).NeuronIndex; // 连接的前一层神经元标号
if ( kk == ULONG_MAX ) // 偏置的标号固定为最大整形量
{
output = 1.0; // 偏置
}
else // 其他情况下 神经元输出等于前一层对应神经元的输出 Xn-1
{
output = m_pPrevLayer->m_Neurons[ kk ]->output;
}
// 误差对权值的梯度
// 每次使用对应神经元的误差对输入的梯度
dErr_wrt_dWn[ (*cit).WeightIndex ] += dErr_wrt_dYn[ ii ] * output;
} ii++;
} // 计算式 (5): dErr_wrt_Xnm1 = Wn * dErr_wrt_dYn,// 需要dErr_wrt_Xn的值来进行前一层的BP ii = ;
for ( nit=m_Neurons.begin(); nit<m_Neurons.end(); nit++ ) // 迭代所有神经元
{
NNNeuron& n = *(*nit); // 取引用 for ( cit=n.m_Connections.begin();
cit<n.m_Connections.end(); cit++ ) // 遍历每个神经元所有连接
{
kk=(*cit).NeuronIndex;
if ( kk != ULONG_MAX )
{
// 排除了ULONG_MAX, 提高了偏置神经元的重要性// 因为我们不能够训练偏置神经元 nIndex = kk; dErr_wrt_dXnm1[ nIndex ] += dErr_wrt_dYn[ ii ] *
m_Weights[ (*cit).WeightIndex ]->value;
} } ii++; // ii 跟踪神经元下标 } // 计算式 (6): 更新权值
// 在本层使用 dErr_wrt_dW (式4)
// 以及训练速率eta for ( jj=; jj<m_Weights.size(); ++jj )
{
oldValue = m_Weights[ jj ]->value;
newValue = oldValue.dd - etaLearningRate * dErr_wrt_dWn[ jj ];
m_Weights[ jj ]->value = newValue;
}
}
[CLPR]BP神经网络的C++实现的更多相关文章
- BP神经网络原理及python实现
[废话外传]:终于要讲神经网络了,这个让我踏进机器学习大门,让我读研,改变我人生命运的四个字!话说那么一天,我在乱点百度,看到了这样的内容: 看到这么高大上,这么牛逼的定义,怎么能不让我这个技术宅男心 ...
- BP神经网络
秋招刚结束,这俩月没事就学习下斯坦福大学公开课,想学习一下深度学习(这年头不会DL,都不敢说自己懂机器学习),目前学到了神经网络部分,学习起来有点吃力,把之前学的BP(back-progagation ...
- 数据挖掘系列(9)——BP神经网络算法与实践
神经网络曾经很火,有过一段低迷期,现在因为深度学习的原因继续火起来了.神经网络有很多种:前向传输网络.反向传输网络.递归神经网络.卷积神经网络等.本文介绍基本的反向传输神经网络(Backpropaga ...
- BP神经网络推导过程详解
BP算法是一种最有效的多层神经网络学习方法,其主要特点是信号前向传递,而误差后向传播,通过不断调节网络权重值,使得网络的最终输出与期望输出尽可能接近,以达到训练的目的. 一.多层神经网络结构及其描述 ...
- 极简反传(BP)神经网络
一.两层神经网络(感知机) import numpy as np '''极简两层反传(BP)神经网络''' # 样本 X = np.array([[0,0,1],[0,1,1],[1,0,1],[1, ...
- BP神经网络
BP神经网络基本原理 BP神经网络是一种单向传播的多层前向网络,具有三层或多层以上的神经网络结构,其中包含输入层.隐含层和输出层的三层网络应用最为普遍. 网络中的上下层之间实现全连接,而每层神经元之 ...
- BP神经网络学习笔记_附源代码
BP神经网络基本原理: 误差逆传播(back propagation, BP)算法是一种计算单个权值变化引起网络性能变化的较为简单的方法.由于BP算法过程包含从输出节点开始,反向地向第一隐含层(即最接 ...
- 机器学习(一):梯度下降、神经网络、BP神经网络
这几天围绕论文A Neural Probability Language Model 看了一些周边资料,如神经网络.梯度下降算法,然后顺便又延伸温习了一下线性代数.概率论以及求导.总的来说,学到不少知 ...
- 基于Storm 分布式BP神经网络,将神经网络做成实时分布式架构
将神经网络做成实时分布式架构: Storm 分布式BP神经网络: http://bbs.csdn.net/topics/390717623 流式大数据处理的三种框架:Storm,Spark和Sa ...
随机推荐
- CF337C - Quiz
/*题目大意,给出n道题,假设答对了m道题,求最小的分数,有一个规则,就是连续答对num==k道题那么分数就翻倍,然后num清零,从新开始计数,到大连续k道的时候 要先加上这道题的分数1,再乘以2, ...
- jQuery:$(document).ready()用法
jQuery:$(document).ready()用法 $(document).ready() 方法允许我们在文档完全加载完后执行函数;
- 20145307陈俊达《网络对抗》shellcode注入&return to libc
20145307陈俊达<网络对抗>shellcode注入 Shellcode注入 基础知识 Shellcode实际是一段代码,但却作为数据发送给受攻击服务器,将代码存储到对方的堆栈中,并将 ...
- tensorflow 安装GPU版本,个人总结,步骤比较详细【转】
本文转载自:https://blog.csdn.net/gangeqian2/article/details/79358543 手把手教你windows安装tensorflow的教程参考另一篇博文ht ...
- 【找不到符号】Maven打包找不到符号的问题排查
当碰到maven错误:找不到符号问题时,通常第一反应应该是执行eclipse的Project -> Clean … -> Clean all projects,然后再执行maven cle ...
- UVa 1635 无关的元素(唯一分解定理+二项式定理)
https://vjudge.net/problem/UVA-1635 题意: 给定n个数a1,a2,...an,依次求出相邻两数之和,将得到一个新数列.重复上述操作,最后结果将变成一个数.问这个数除 ...
- adb 安装软件
一.连接 adb connect 192.168.1.10 输出 connected to 二.查看设备 adb devices 输出 List of devices attached device ...
- 雷林鹏分享:Ruby Socket 编程
Ruby Socket 编程 Ruby提供了两个级别访问网络的服务,在底层你可以访问操作系统,它可以让你实现客户端和服务器为面向连接和无连接协议的基本套接字支持. Ruby 统一支持应用程的网络协议, ...
- C#皮肤之IrisSkin4.dll
1. 将IrisSkin4.dll动态文件导入当前项目引用中.具体操作为:解决方案资源管理器->当前项目->引用->右键->添加引用,找到IrisSkin4.dll文件,然后加 ...
- Leetcode 34
//二分查找后,向两边扩展,二分错了两次,现在是对的.//还有就是vector可以用{}直接赋值很棒 class Solution { public: vector<int> search ...