go中的sync.RWMutex源码解读
读写锁
前言
本次的代码是基于go version go1.13.15 darwin/amd64
什么是读写锁
读写锁类比于互斥锁,锁的粒度更小了。互斥锁,我们知道,一个资源被一把互斥锁,锁住了,另外的goroutine,在锁定期间,必定不能操作。
读写锁就不同了:
写锁需要阻塞写锁:一个协程拥有写锁时,其他协程写锁定需要阻塞
写锁需要阻塞读锁:一个协程拥有写锁时,其他协程读锁定需要阻塞
读锁需要阻塞写锁:一个协程拥有读锁时,其他协程写锁定需要阻塞
读锁不能阻塞读锁:一个协程拥有读锁时,其他协程也可以拥有读锁
看下实现
RWMutex提供4个简单的接口来提供服务:
RLock():读锁定
RUnlock():解除读锁定
Lock(): 写锁定,与Mutex完全一致
Unlock():解除写锁定,与Mutex完全一致
看下具体的实现
type RWMutex struct {
w Mutex // 用于控制多个写锁,获得写锁首先要获取该锁,如果有一个写锁在进行,那么再到来的写锁将会阻塞于此
writerSem uint32 // 写阻塞等待的信号量,最后一个读者释放锁时会释放信号量
readerSem uint32 // 读阻塞的协程等待的信号量,持有写锁的协程释放锁后会释放信号量
readerCount int32 // 记录读者个数
readerWait int32 // 记录写阻塞时读者个数
}
读锁
RLock
const rwmutexMaxReaders = 1 << 30
// 读加锁
// 增加读操作计数,即readerCount++
// 阻塞等待写操作结束(如果有的话)
func (rw *RWMutex) RLock() {
// 竞态检测
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// 当有之前有写锁的时候,写锁会先将readerCount减去rwmutexMaxReaders的值
// 这样当有写操作在进行的时候这个值就是一个负数
// 读操作根据这个来判断是否要将自己阻塞
// 如果之前没有写锁,那么readerCount的值将大于等于0
// 写锁同样根据这个值来判断在本次写锁之前是已经有读锁存在了
// 首先通过atomic的原子性使readerCount+1
// 1、如果readerCount<0。说明写锁已经获取了,那么这个读锁需要等待写锁的完成
// 2、如果readerCount>=0。当前读直接获取锁
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// 当前有个写锁, 读操作阻塞等待写锁释放
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
// 是否开启检测race
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
梳理下流程:
1、首先当有写操作的时候,会先将readerCount减去rwmutexMaxReaders的值,这在写锁定(Lock())中可以看到;
2、原子的修改readerCount,如果结果小于0说明有写锁存在,需要阻塞读锁;
3、通过runtime_SemacquireMutex将当前的读锁加入到阻塞队列的尾部。
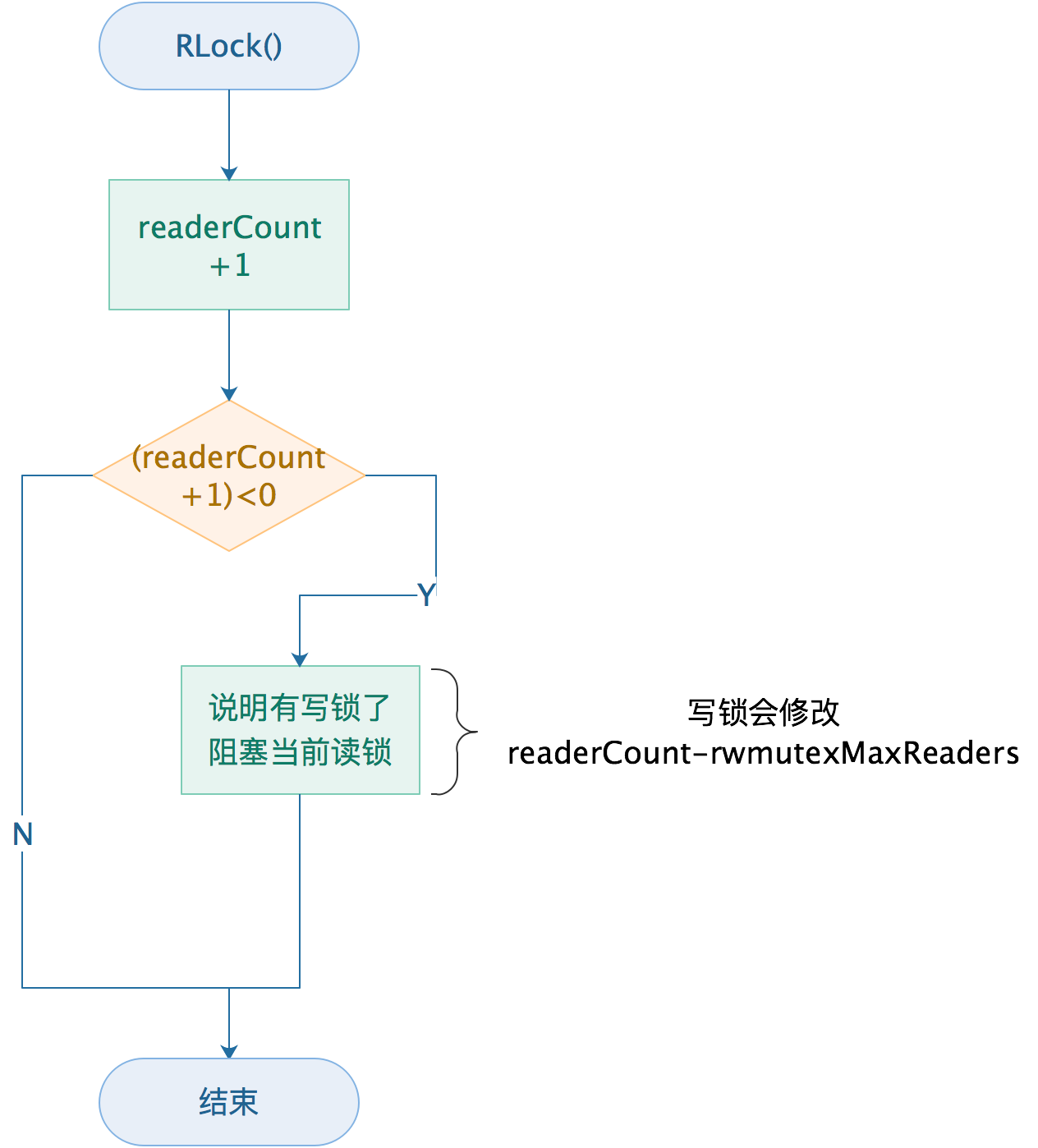
RUnlock
// 减少读操作计数,即readerCount--
// 唤醒等待写操作的协程(如果有的话)
func (rw *RWMutex) RUnlock() {
// 是否开启检测race
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
// 首先通过atomic的原子性使readerCount-1
// 1.若readerCount大于0, 证明当前还有读锁, 直接结束本次操作
// 2.若readerCount小于0, 证明已经没有读锁, 但是还有因为读锁被阻塞的写锁存在
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// 尝试唤醒被阻塞的写锁
rw.rUnlockSlow(r)
}
// 是否开启检测race
if race.Enabled {
race.Enable()
}
}
func (rw *RWMutex) rUnlockSlow(r int32) {
// 判断RUnlock被过多使用了
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// readerWait--操作,如果readerWait--操作之后的值为0,说明,写锁之前,已经没有读锁了
// 通过writerSem信号量,唤醒队列中第一个阻塞的写锁
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// 唤醒一个写锁
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
梳理下流程:
1、首先还是操作readerCount,对进行--操作;
- 1、如果操作之后的值大于0,说明还有读锁存在,直接结束本次操作;
- 2、如果操作之后值小于0,说明还有写锁存在,尝试在最后一个读锁完成的时候去唤醒写锁;
2、readerWait--操作,如果readerWait--操作之后的值为0,说明,写锁之前,已经没有读锁了;
3、通过信号量唤醒队列中第一个被阻塞的写锁。
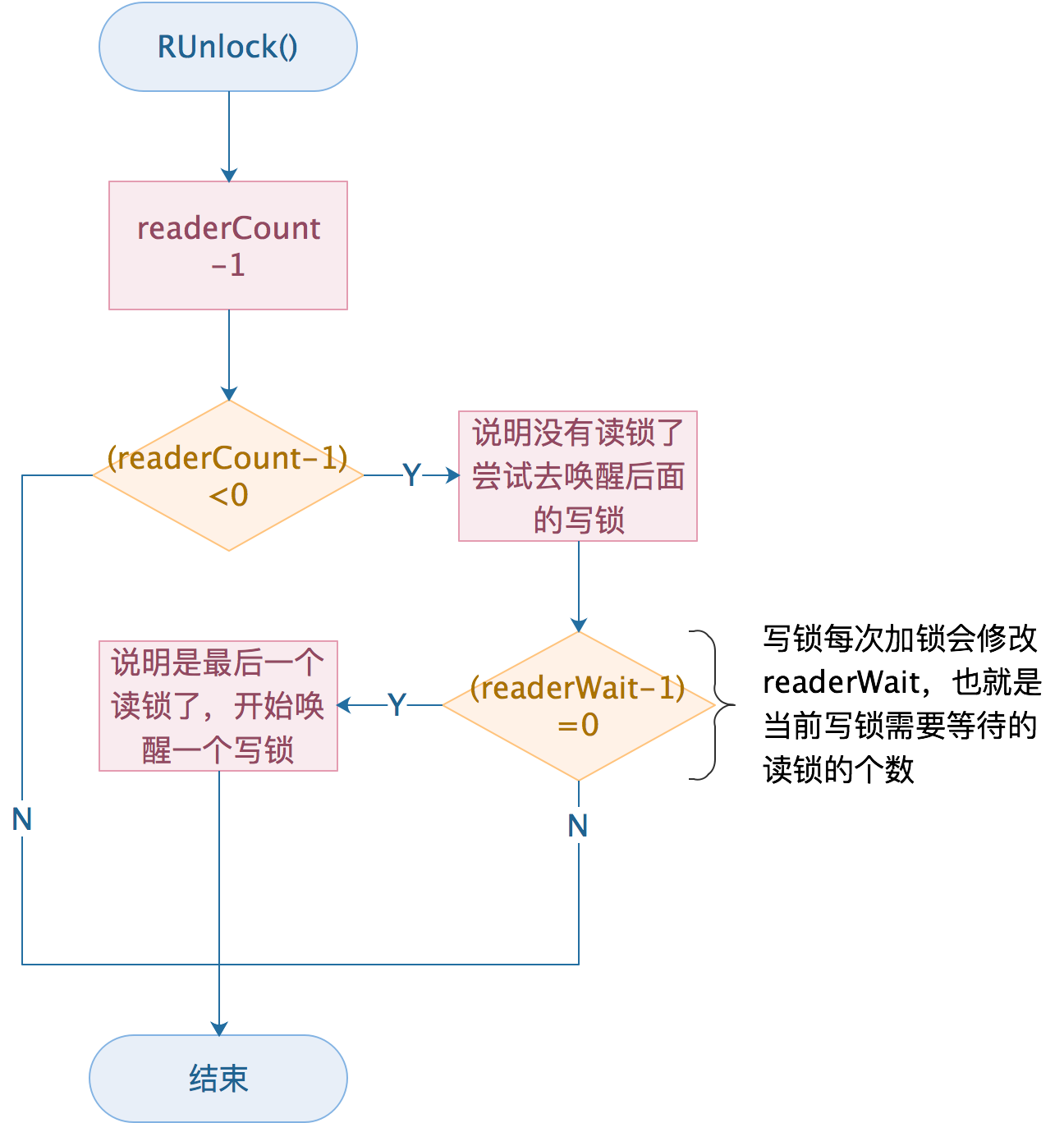
写锁
Lock
// 获取互斥锁
// 阻塞等待所有读操作结束(如果有的话)
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// 获取互斥锁
rw.w.Lock()
// 原子的修改readerCount的值,直接将readerCount减去rwmutexMaxReaders
// 说明,有写锁进来了,这在上面的读锁中也有体现
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 当r不为0说明,当前写锁之前有读锁的存在
// 修改下readerWait,也就是当前写锁需要等待的读锁的个数
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
// 阻塞当前写锁
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
梳理下流程:
1、修改下readerCount的数量,直接减去rwmutexMaxReaders;
2、判断当前写锁之前,是否有读锁的存在;
我们知道,写操作要等待读操作结束后才可以获得锁,写操作等待期间可能还有新的读操作持续到来,如果写操作等待所有读操作结束,很可能被饿死。然而,通过RWMutex.readerWait可完美解决这个问题。
写操作到来时,会把RWMutex.readerCount值拷贝到RWMutex.readerWait中,用于标记排在写操作前面的读者个数。
前面的读操作结束后,除了会递减RWMutex.readerCount,还会递减RWMutex.readerWait值,当RWMutex.readerWait值变为0时唤醒写操作。
写操作之后产生的读操作就会加入到readerCount,阻塞直到写锁释放。
3、如果有读锁,阻塞当前写锁;
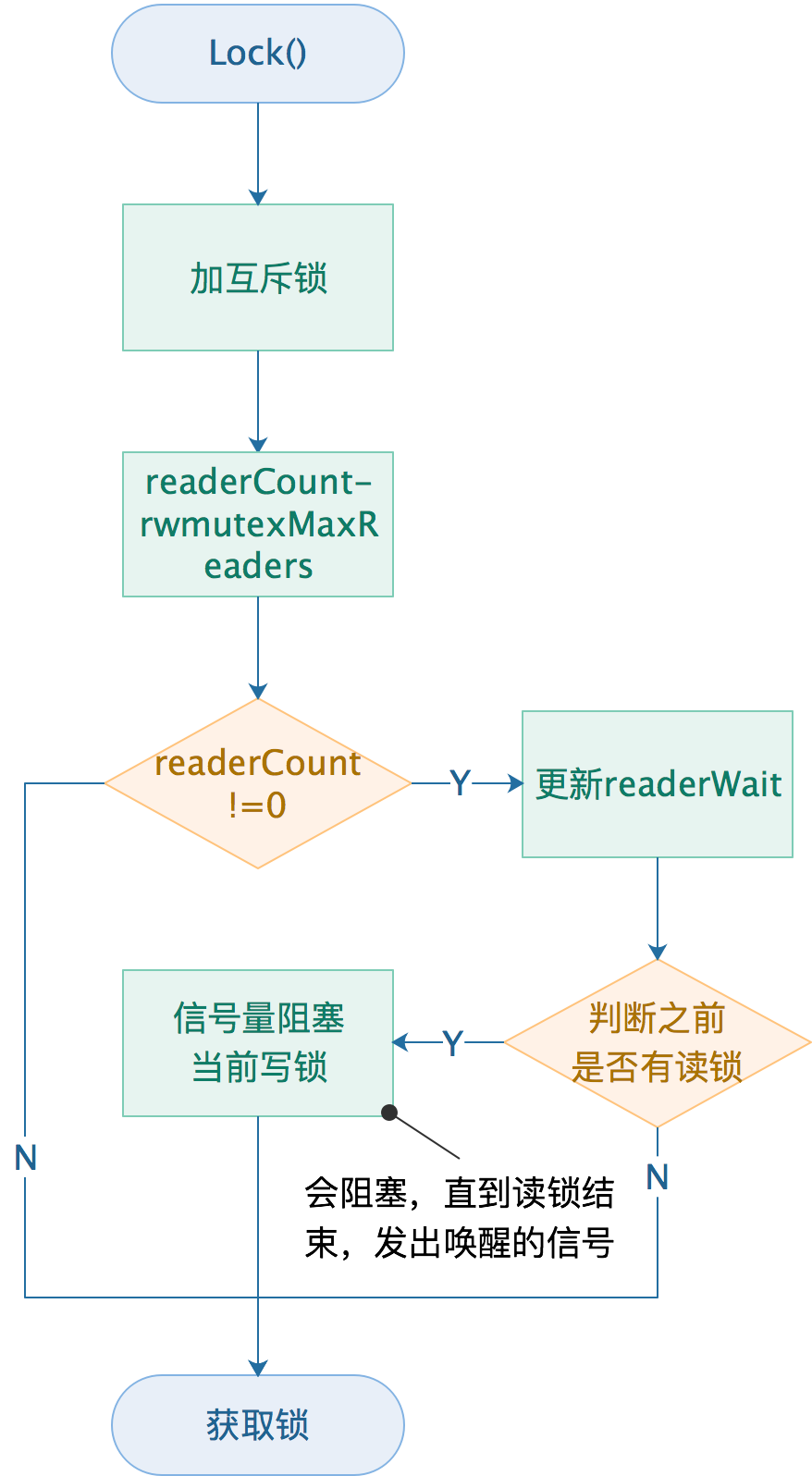
Unlock
// 如果写锁未锁定,解锁将会触发panic
//一个锁定的互斥锁与一个特定的goroutine没有关联。
// 它允许一个goroutine锁定一个写锁然后
// 安排另一个goroutine解锁它。
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// 增加readerCount, 若超过读锁的最大限制, 触发panic
// 和写锁定的-rwmutexMaxReaders,向对应
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// 如果r>0,说明当前写锁后面,有阻塞的读锁
// 然后,通过信号量一一释放阻塞的读锁
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 释放互斥锁
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
梳理下流程:
1、首先修改readerCount的值,加上rwmutexMaxReaders,和上文的-rwmutexMaxReaders相呼应;
2、然后判断后面是否有读锁被阻塞,如果有一一唤醒。
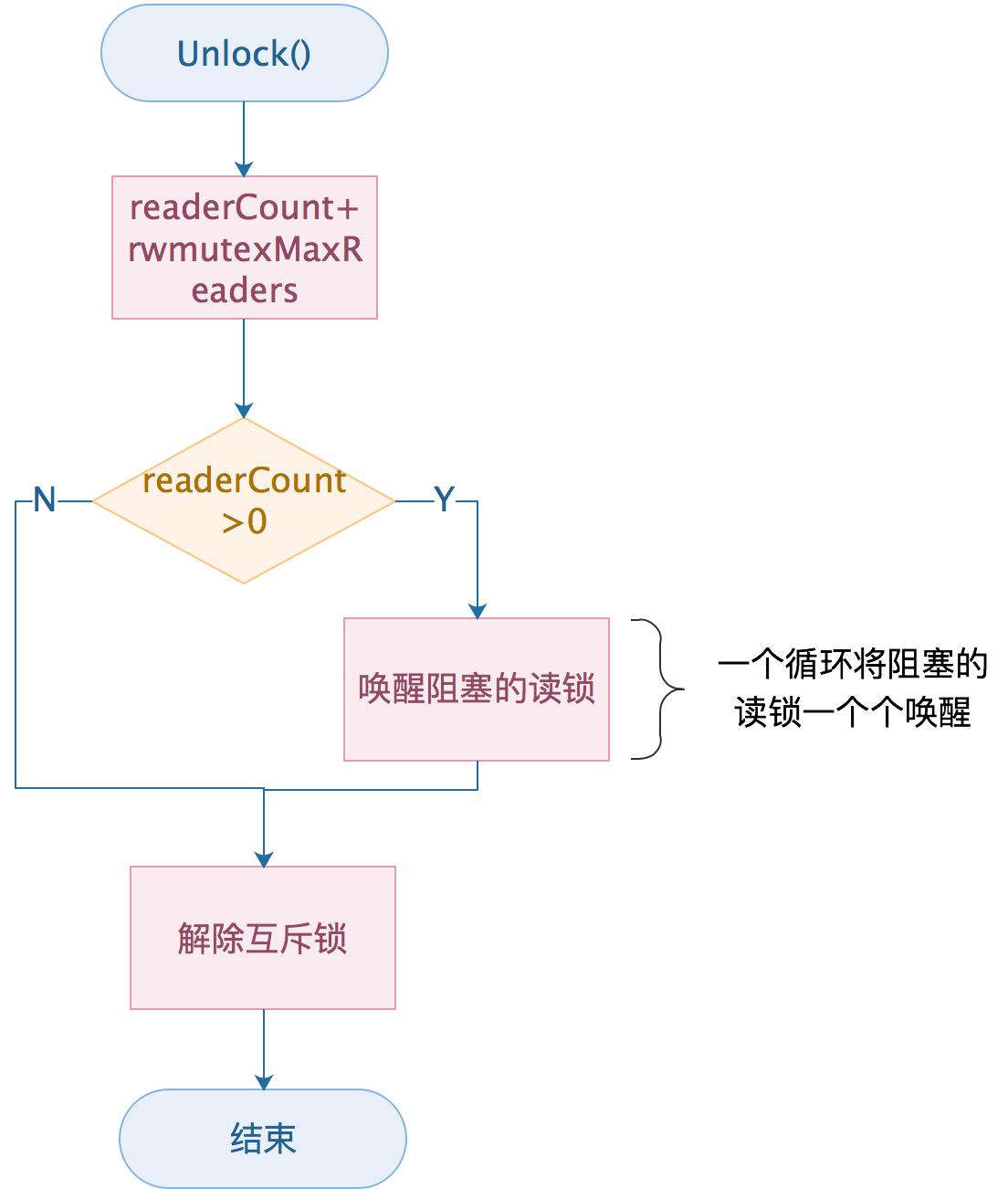
问题要论
写操作是如何阻止写操作的
读写锁包含一个互斥锁(Mutex),写锁定必须要先获取该互斥锁,如果互斥锁已被协程A获取(或者协程A在阻塞等待读结束),意味着协程A获取了互斥锁,那么协程B只能阻塞等待该互斥锁。
所以,写操作依赖互斥锁阻止其他的写操作。
写操作是如何阻止读操作的
我们知道RWMutex.readerCount是个整型值,用于表示读者数量,不考虑写操作的情况下,每次读锁定将该值+1,每次解除读锁定将该值-1,所以readerCount取值为[0, N],N为读者个数,实际上最大可支持2^30个并发读者。
当写锁定进行时,会先将readerCount减去230,从而readerCount变成了负值,此时再有读锁定到来时检测到readerCount为负值,便知道有写操作在进行,只好阻塞等待。而真实的读操作个数并不会丢失,只需要将readerCount加上230即可获得。
所以,写操作将readerCount变成负值来阻止读操作的。
读操作是如何阻止写操作的
写操作到来时,会把RWMutex.readerCount值拷贝到RWMutex.readerWait中,用于标记排在写操作前面的读者个数。
前面的读操作结束后,除了会递减RWMutex.readerCount,还会递减RWMutex.readerWait值,当RWMutex.readerWait值变为0时唤醒写操作。
为什么写锁定不会被饿死
我们知道,写操作要等待读操作结束后才可以获得锁,写操作等待期间可能还有新的读操作持续到来,如果写操作等待所有读操作结束,很可能被饿死。然而,通过RWMutex.readerWait可完美解决这个问题。
写操作到来时,会把RWMutex.readerCount值拷贝到RWMutex.readerWait中,用于标记排在写操作前面的读者个数。
前面的读操作结束后,除了会递减RWMutex.readerCount,还会递减RWMutex.readerWait值,当RWMutex.readerWait值变为0时唤醒写操作。
两个读锁之间穿插了一个写锁
type test struct {
data map[string]string
r sync.RWMutex
}
func (t test) read() {
t.r.RLock()
t.r.Lock()
fmt.Println(t.data)
t.r.Unlock()
t.r.RUnlock()
}
上面的代码将会发什么?
deadlock!
分析下原因
1、读锁是会阻塞写锁的,上面的读锁已经上锁了;
2、后面的写锁来加锁。发现已经有读锁了,然后使用信号量阻塞当前的写锁,等待读锁解锁时被唤醒;
3、然后这个写锁马上解锁,但是当前的写锁,一直在等待被信号量唤醒,读锁的解锁又一直在等待写锁的解锁;
4、然后就死循环,deadlock。
参考
【Package race】https://golang.org/pkg/internal/race/
【sync.RWMutex源码分析】http://liangjf.top/2020/07/20/141.sync.RWMutex源码分析/
【剖析Go的读写锁】http://zablog.me/2017/09/27/go_sync/
【《Go专家编程》GO 读写锁实现原理剖析】https://my.oschina.net/renhc/blog/2878292
本文作者:liz
本文链接:https://boilingfrog.github.io/2021/03/17/sync.RWMutex/
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
go中的sync.RWMutex源码解读的更多相关文章
- go中sync.Mutex源码解读
互斥锁 前言 什么是sync.Mutex 分析下源码 Lock 位运算 Unlock 总结 参考 互斥锁 前言 本次的代码是基于go version go1.13.15 darwin/amd64 什么 ...
- 【原】Spark中Job的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. Spark程序程序job的运行是通过actions算子触发的,每一个action算子其实是一个runJob方法的运行,详见文章 SparkContex源码 ...
- HttpServlet中service方法的源码解读
前言 最近在看<Head First Servlet & JSP>这本书, 对servlet有了更加深入的理解.今天就来写一篇博客,谈一谈Servlet中一个重要的方法-- ...
- go中sync.Cond源码解读
sync.Cond 前言 什么是sync.Cond 看下源码 Wait Signal Broadcast 总结 sync.Cond 前言 本次的代码是基于go version go1.13.15 da ...
- sklearn中LinearRegression使用及源码解读
sklearn中的LinearRegression 函数原型:class sklearn.linear_model.LinearRegression(fit_intercept=True,normal ...
- go中sync.Once源码解读
sync.Once 前言 sync.Once的作用 实现原理 总结 sync.Once 前言 本次的代码是基于go version go1.13.15 darwin/amd64 sync.Once的作 ...
- 【原】 Spark中Task的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Stage的提交 http://www.cnblogs.com/yourarebest/p/5356769.html Spark中 ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- 【原】Spark不同运行模式下资源分配源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Task的提交源码解读 http://www.cnblogs.com/yourarebest/p/5423906.html Sch ...
- AbstractCollection类中的 T[] toArray(T[] a)方法源码解读
一.源码解读 @SuppressWarnings("unchecked") public <T> T[] toArray(T[] a) { //size为集合的大小 i ...
随机推荐
- 【设计模式】分享 Java 开发中常用到的设计模式(一)
分享 Java 开发中常用到的设计模式(一) 前言 不知道大家在开发的时候,有没有想过(遇到)这些问题: 大家都是按需要开发,都是一个职级的同事,为什么有些人的思路就很清晰,代码也很整洁.易懂:而自己 ...
- 成为一个合格程序员所必备的三种常见LeetCode排序算法
排序算法是一种通过特定的算法因式将一组或多组数据按照既定模式进行重新排序的方法.通过排序,我们可以得到一个新的序列,该序列遵循一定的规则并展现出一定的规律.经过排序处理后的数据可以更方便地进行筛选和计 ...
- 面试官:请聊一聊String、StringBuilder、StringBuffer三者的区别
面试官:"小伙子,在日常的写代码过程中,使用过String,StringBuilder和StringBuffer没?" 我:"用过的呀!" 面试官:" ...
- 关于“Github上传以及Clone时发生的 Failed to connect to github.com port 443: Timed out 问题解法记录
本文是记录关于如何解决 "Github上传以及Clone时发生的 Failed to connect to github.com port 443: Timed out 错误" 看 ...
- 0x03~04 前缀和与差分、二分
A题:HNOI2003]激光炸弹 按照蓝书上的教程做即可,注意这道题卡空间用int 而不是 long long. int g[5010][5010]; int main() { ios_base::s ...
- <vue 组件 4、插槽的使用>
代码结构 一. 01-slot-插槽的基本使用 1. 效果 同样的一个插槽,父组件调用的时候不同展现的内容就不同 2.代码 01-slot-插槽的基本使用.html <!DOCTYPE ...
- 使用element-plus的el-scrollbar时滚动条没有显示出来但是页面可以滚动的解决办法
如果使用 Element UI 的 el-scrollbar 组件时,滚动条没有显示出来但页面可以滚动,可以尝试调用其 update 方法来更新滚动条. 在适当的时机(例如在数据加载完成后或组件更新后 ...
- Oracle数据库学习总结
SQL 笔记 ch3_cn 1.数据类型记录 char(n) 定长字符 varchar(n) 可变长字符 numeric(p,d) 定点数,总位数p,小数点后位数q float(n) n位浮点数 2. ...
- PMP-干系人管理
转载请注明出处: 1.分析干系人管理的两大工具 1.1.权力-利益方阵 第一象限:严防死守(重点管理) 第二象限:投其所好(令其满意) 第三象限:保存 ...
- for-each循环使用iterator进行遍历
示例如下: public static void main(String args[]) { List list = new LinkedList(); list.add("aa" ...