flink 大批量任务提交 yarn 失败问题
问题现象
用户迁移到新集群后,反馈他们开发平台大量 flink 任务提交失败了,当时集群的 yarn 资源是足够的
排查过程
用户是在他们的开发平台上提交的,查看他们失败的任务,发现是他们提交端主动 Kill 的,接着沟通发现他们提交平台有个逻辑就是提交到 yarn 的 flink 任务,如果在 2分钟内没有在 yarn 上启动起来,也就是提交的 flink yarn application 没有变成 running 状态的话,开发平台会终止这个提交,并判定这个任务的状态为提交失败了.
已知背景如下:
- 旧集群没有这个问题,迁移到新集群后出现的
- 在提交任务的高峰期才会出现这种问题,低峰期没有这个问题
- 提交端客户端的日志是显示在等待,然后超过 2分钟了,cancel 了
2022-07-26 17:45:32,355 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1625727384658_7951
2022-07-26 17:45:32,577 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1625727384658_7951
2022-07-26 17:45:32,578 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2022-07-26 17:45:32,579 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2022-07-26 17:46:32,801 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
2022-07-26 17:46:33,052 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor
......
2022-07-26 17:47:16,655 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
2022-07-26 17:47:16,690 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cancelling deployment from Deployment Failure Hook疑点
把提交平台的 2 分钟判断时间增加到 5分钟是能够保证任务成功提交的.
根据 yarn 任务提交流程 ,application 等 master 启动起来后,并向 rm 注册后, application 就从 accepted 状态变为 running 状态了,所以问题是为什么 master 在 2分钟内拉不起了
am 也是一个 container ,一般来说 container 启动过程耗时比较长的资源本地化 localized resource 过程, 从 nm 日志中也确实证实了这一点.
但是资源本地化是一个很简单的操作,如果慢了,问题不会在应用层,一般都是底层网络或者硬件的问题.
于是接着开始转向排查底层操作系统和硬件的问题
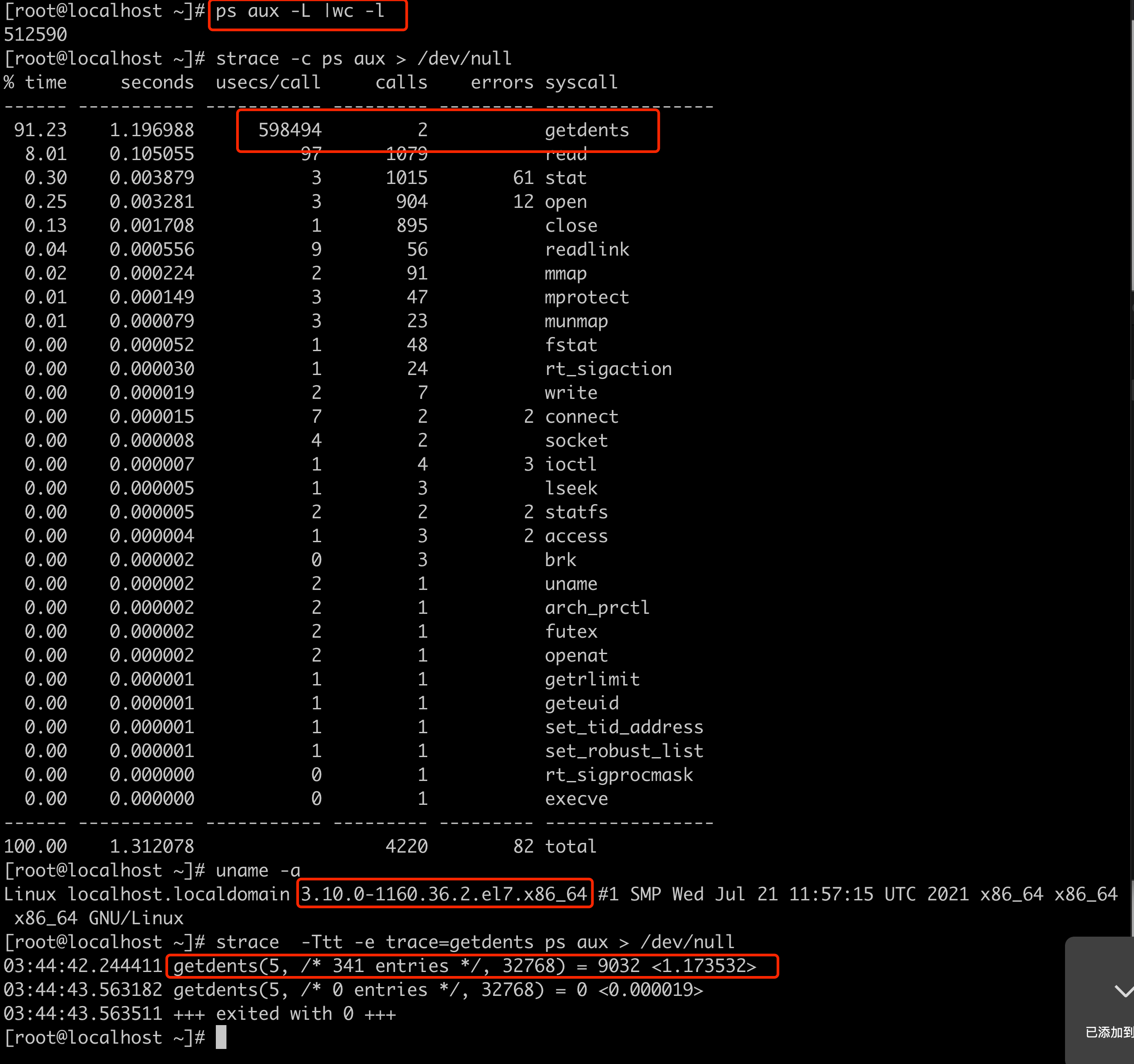
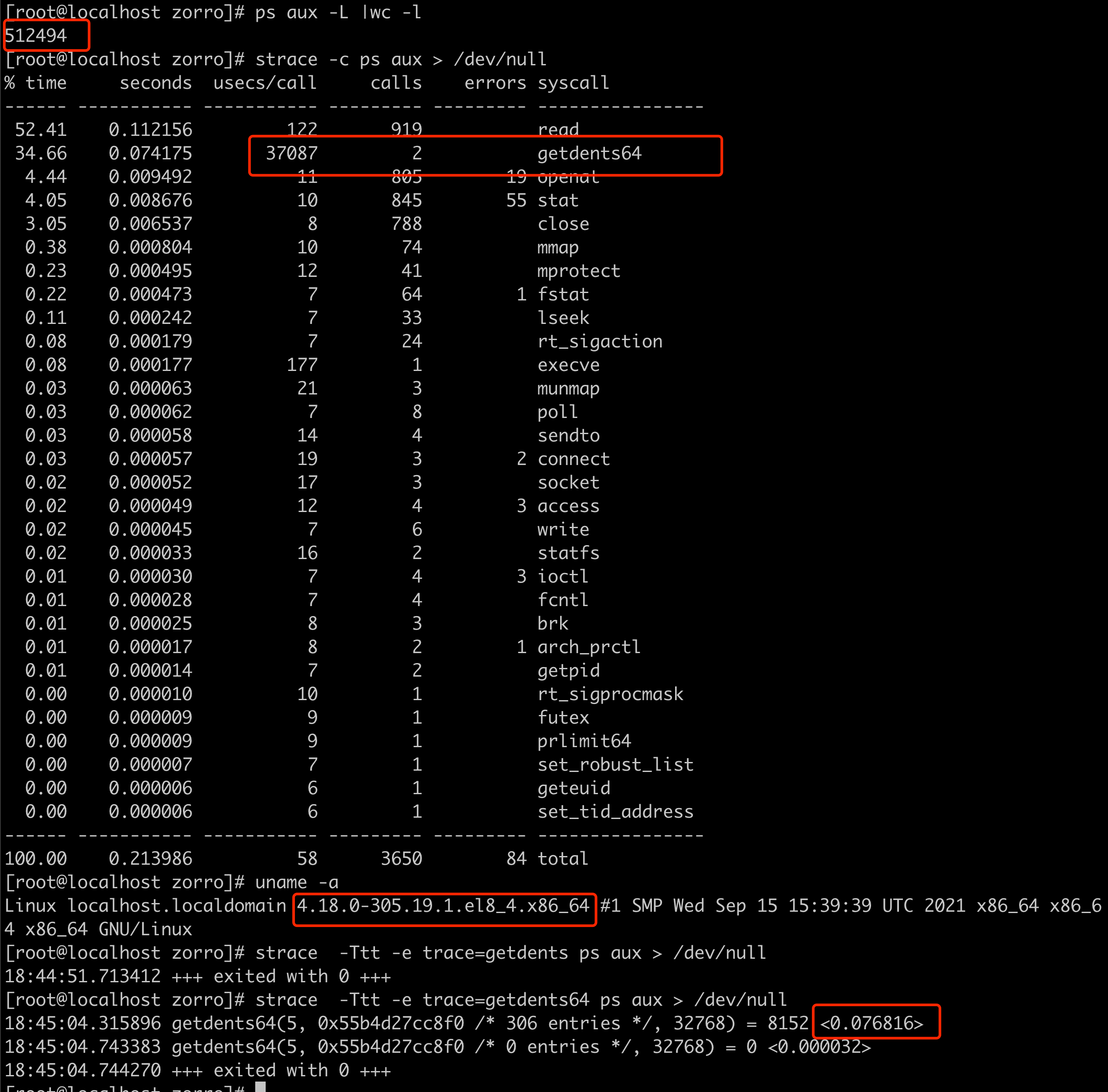
分析发现问题节点上的线程数非常多:ps -efL | grep java | wc -l
有 11 w 个, 当线程数在 5 w 个的时候,是能正常拉起 flink 任务的,这也是旧集群上正常节点上的线程数,但是当提交的任务增加,线程数达到 10 w 以上时,就无法在 2 分钟内拉起提交的 flink 任务.
在问题节点上,发现 ps 执行出现卡顿的现象,从这里排查发现:
因为线程开的太多,导致/proc目录下的子目录过多,导致的遍历这些目录时,getdents 消耗时间过长,只要是会访问/proc目录下的文件,都会因为同样的原因导致处理慢。
于是猜测 flink 提交任务估计也是同样的因素导致拉起超时,接着 使用 strace 工具来跟踪 nodemanager 进程,跟踪启动 am container 的过程:找到下载jar包的进程/线程pid,然后strace -p pid -f -Ttt 2> strace.log 发现 nm 进程底层会有 /proc 目录的操作.
所以得出结论还是由于起的线程过多,导致proc下的目录过多,引起底层的相关调用变慢,进而导致上层的 java 程序变慢.
但是用户接着提出疑问,新集群 cpu 和内存配置都是旧集群的两倍,为什么支撑不了两倍的 flink 任务提交,并且当时问题节点的 cpu load 并没满
没有其他排查线索了
这时发现问题节点使用的 linux 内核版本是3.10 的,版本比较老,怀疑是内核层面对于多核多线程的处理能力导致的,于是构造环境使用 strace 进行测试,发现确实高版本内核 getdents 调用性能差异巨大
结论
linux 内核版本3.10低版本 对多核数大量线程相关处理缺少优化,导致某些底层系统调用处理性能不高.
升级内核到 4.18 版本即可解决
flink 大批量任务提交 yarn 失败问题的更多相关文章
- Flink命令行提交job (源码分析)
这篇文章主要介绍从命令行到任务在Driver端运行的过程 通过flink run 命令提交jar包运行程序 以yarn 模式提交任务命令类似于: flink run -m yarn-cluster X ...
- 怎样通过Java程序提交yarn的mapreduce计算任务
因为项目需求,须要通过Java程序提交Yarn的MapReduce的计算任务.与一般的通过Jar包提交MapReduce任务不同,通过程序提交MapReduce任务须要有点小变动.详见下面代码. 下面 ...
- windows phone 应用提交商店失败总结
应用完成后,在提交微软商店时,可能因为各种各样的问题导致提交审核失败.以前的审核失败并没有总结,希望今后 把各种提交审核失败的情况总结一下,以减少今后提交认证时浪费时间. 1.商店的屏幕截图上不能包含 ...
- [SourceTree] - 提交代码失败 "git -c diff.mnemonicprefix=false -c core.quotepath=false" 之解决
背景 使用 SourceTree 提交代码失败,尝试了重装 SourceTree 和 Git 问题依旧. 错误信息 git -c diff.mnemonicprefix=false -c core.q ...
- storm on yarn安装时 提交到yarn失败 failed
最近在部署storm on yarn ,部署参考文章 http://www.tuicool.com/articles/BFr2Yvhttp://blog.csdn.net/jiushuai/artic ...
- JMeter Http请求POST提交token失败,取样器结果Response Code 415
Jmeter脚本,http请求以post方式提交token,执行脚本在察看结果中显示失败,取样器结果响应状态Response Code 415,如图:
- SVN提交文件失败:系统找不到指定路径
完成程序代码工作后,进行SVN的文件提交.先进行项目的更新,然后在修改的文件上进行提交操作,发现SVN弹出提示信息,“系统找不到指定路径”提交失败,如下图: ...
- 织梦更换Ueditor编辑器后栏目内容提交更新失败
今天在使用网友的相关经验<百度编辑器(Ueditor)整合到dedecms>,给织梦dedecms系统更换编辑器后,文章编辑器使用正常,在编辑栏目内容的时候,出现提交后不更新内容的情况,上 ...
- SVN提交数据失败问题(提示 svn:MKACTIVITY ... 403 Forbidden )
注册了淘宝svn,结果在代码提交是老是出问题,如下截图所示: 网上有常用的一种方法是: http://jingyan.baidu.com/article/67508eb4d3f2e29ccb1ce47 ...
- github提交代码失败
向github上面提交代码,提示代码里面有大文件,建议使用git-lfs. 1,安装git-lfs yum install git-lfs 2,配置需要追踪的打文件(由于我这里提交的是jar包) gi ...
随机推荐
- 如何用 WinDbg 调试Linux上的 .NET程序
一:背景 1. 讲故事 最新版本 1.2402.24001.0 的WinDbg真的让人很兴奋,可以将自己伪装成 GDB 来和远程的 GDBServer 打通来实现对 Linux 上 .NET程序进行调 ...
- Python项目批量管理第三方包(requirements.txt)
python项目中必须包含一个 requirements.txt 文件,用于记录所有依赖包及其精确的版本号,以便新环境部署. requirements.txt可以通过pip命令自动生成和安装 生成re ...
- 断点续传:使用java对大文件进行分块与合并
通常我们下载上传的视频文件比较大.虽然https协议没有规定上传文件大小的限制,但是网络的质量,电脑硬件的参差不齐可能会导致大文件快要上传完成的时候突然断网了要重新上传,非常影响用户体验.以此我们引入 ...
- 写写java中的optional
当我们写代码的时候经常会碰见nullpointer,所以在很多情况下我们需要做各种非空的判断.JDK8中引入了optional,他是一个包装好的类,我们可以把对象传入optional对象中,接下来就可 ...
- 题解 WD与数列
P5161 WD与数列 可以想到原条件是一个差分形式,所以我们对原数组差分.然后发现答案其实就是 \(\sum_{i<j} \min(lcp(i+1,j+1)+1,j-i)\). 这个东西先跑 ...
- RHCA rh442 002 监控工具 脏页 块设备名 缓存
sar 看某一个时间的数据 sar -d 1 5 与iostat类似 计算机识别设备按编号识别 0-15预留出 8 为iscsi设备 做一个块设备名 名字不重要是给人看的,重要的是编号 8 17(主编 ...
- BCLinux 8.2安装配置图解教程--龙蜥社区国产移动云系统
社区镜像下载地址:https://openanolis.cn/download 安装参考地址:https://www.osyunwei.com/archives/13017.html 1安装系统 界面 ...
- 【转载】 一块GPU顶数千个CPU内核,英伟达的这个强化学习利器技术细节终于公开了
原文地址: https://mp.weixin.qq.com/s/FmFqmIqmknkpBQbNb2ioDA ============================================ ...
- 使用Linux桌面壁纸应用variety发现的一些问题
本人Ubuntu18.04 Desktop系统安装桌面壁纸应用variety,设置如下: 使用大致两个小时,主机为NVIDIA显卡,查看显存使用情况: 可以发现随着使用时间的增加variety会逐渐增 ...
- 【转载】 HTTP中的响应协议及302、304的含义
原文地址: https://www.cnblogs.com/chenyablog/p/9197305.html ============================== 响应协议 HTTP/1.1 ...