OpenTelemetry 实战:从零实现应用指标监控
前言
在上一篇文章:OpenTelemetry 实战:从零实现分布式链路追踪讲解了链路相关的实战,本次我们继续跟进如何使用 OpenTelemetry 集成 metrics 监控。
建议对指标监控不太熟的朋友可以先查看这篇前菜文章:从 Prometheus 到 OpenTelemetry:指标监控的演进与实践
| 名称 | 作用 | 语言 | 版本 |
|---|---|---|---|
| java-demo | 发送 gRPC 请求的客户端 | Java | opentelemetry-agent: 2.4.0/SpringBoot: 2.7.14 |
| k8s-combat | 提供 gRPC 服务的服务端 | Golang | go.opentelemetry.io/otel: 1.28/ Go: 1.22 |
| Jaeger | trace 存储的服务端以及 TraceUI 展示 | Golang | jaegertracing/all-in-one:1.56 |
| opentelemetry-collector-contrib | OpenTelemetry 的 collector 服务端,用于收集 trace/metrics/logs 然后写入到远端存储 | Golang | otel/opentelemetry-collector-contrib:0.98.0 |
| Prometheus | 作为 metrics 的存储和展示组件,也可以用 VictoriaMetrics 等兼容 Prometheus 的存储替代。 | Golang | quay.io/prometheus/prometheus:v2.49.1 |
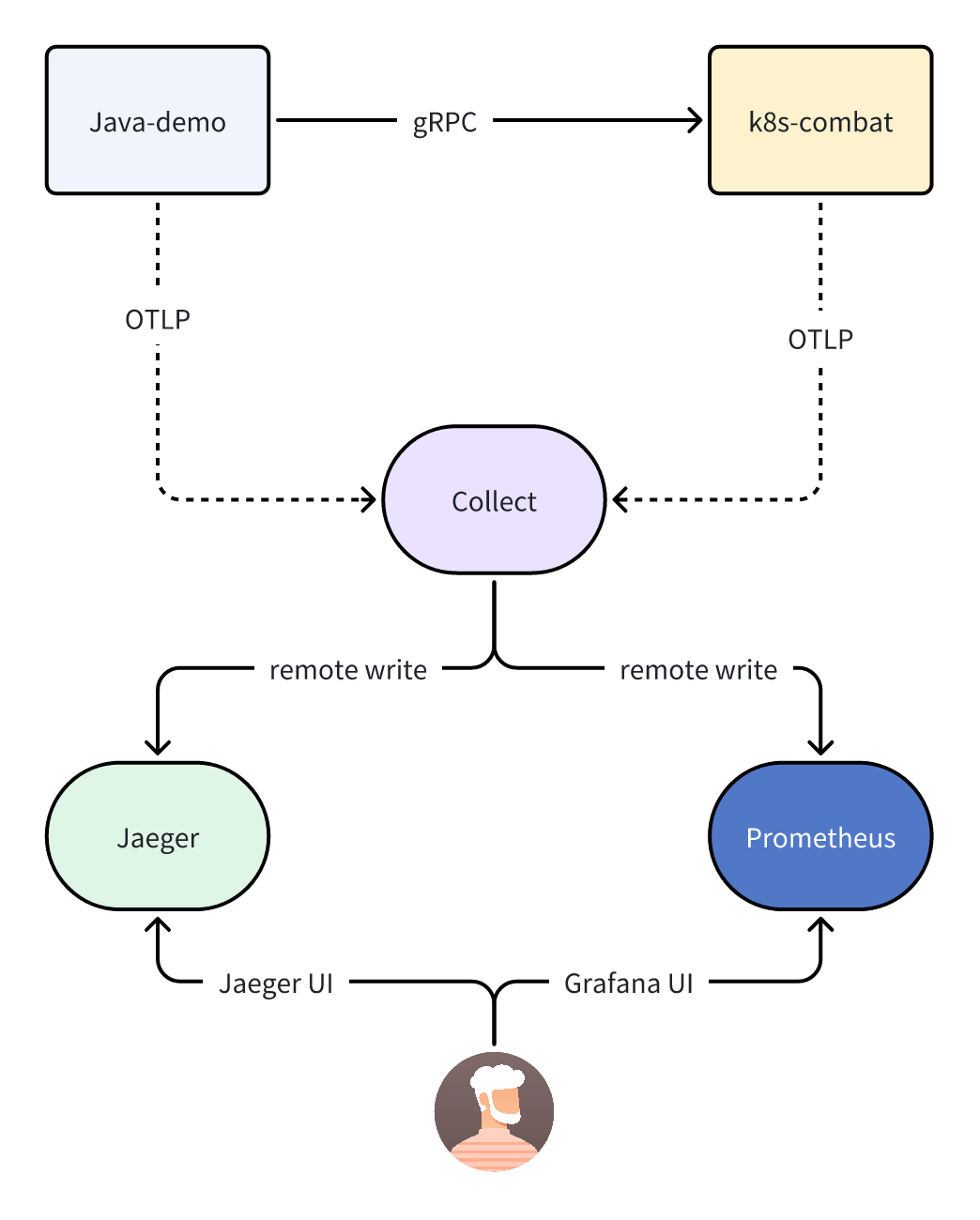 |
快速开始
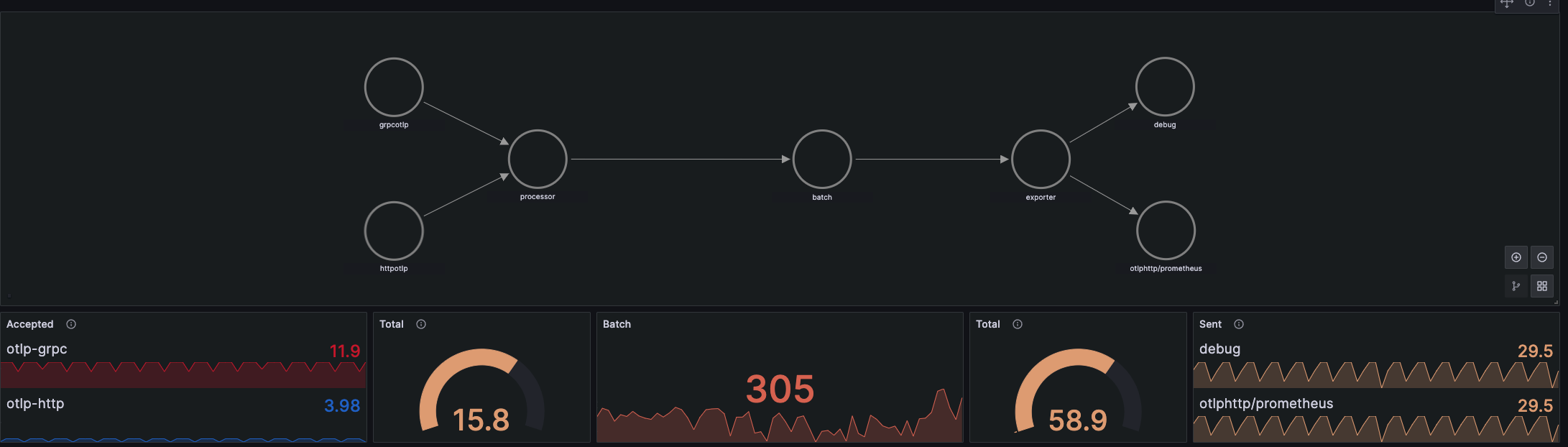
以上是加入 metrics 之后的流程图,在原有的基础上会新增一个 Prometheus 组件,collector 会将 metrics 指标数据通过远程的 remote write 的方式写入到 Prometheus 中。
Prometheus 为了能兼容 OpenTelemetry 写入过来的数据,需要开启相关特性才可以。
如果是 docker 启动的话需要传入相关参数:
docker run -d -p 9292:9090 --name prometheus \
-v /prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
quay.io/prometheus/prometheus:v2.49.1 \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/prometheus \
--web.console.libraries=/etc/prometheus/console_libraries \
--web.console.templates=/etc/prometheus/consoles \
--enable-feature=exemplar-storage \
--enable-feature=otlp-write-receiver
--enable-feature=otlp-write-receiver 最主要的就是这个参数,用于开启接收 OTLP 格式的数据。
但使用这个 Push 特性就会丧失掉 Prometheus 的许多 Pull 特性,比如服务发现,定时抓取等,不过也还好,Push 和 Pull 可以同时使用,原本使用 Pull 抓取的组件依然不受影响。
修改 OpenTelemetry-Collector
接着我们需要修改下 Collector 的配置:
exporters:
debug:
otlp:
endpoint: "jaeger:4317"
tls:
insecure: true
otlphttp/prometheus:
endpoint: http://prometheus:9292/api/v1/otlp
tls:
insecure: true
processors:
batch:
service:
pipelines:
traces:
receivers:
- otlp
processors: [batch]
exporters:
- otlp
- debug
metrics:
exporters:
- otlphttp/prometheus
- debug
processors:
- batch
receivers:
- otlp
这里我们在 exporter 中新增了一个 otlphttp/prometheus 的节点,用于指定导出 prometheus 的 endpoint 地址。
同时我们还需要在 server.metrics.exporters 中配置相同的 key: otlphttp/prometheus。
需要注意的是这里我们一定得是配置在 metrics.exporters 这个节点下,如果配置在 traces.exporters 下时,相当于是告诉 collector 讲 trace 的数据导出到 otlphttp/prometheus.endpoint 这个 endpoint 里了。
所以重点是需要理解这里的配对关系。
运行效果
这样我们只需要将应用启动之后就可以在 Prometheus 中查询到应用上报的指标了。
java -javaagent:opentelemetry-javaagent-2.4.0-SNAPSHOT.jar \
-Dotel.traces.exporter=otlp \
-Dotel.metrics.exporter=otlp \
-Dotel.logs.exporter=none \
-Dotel.service.name=java-demo \
-Dotel.exporter.otlp.protocol=grpc \
-Dotel.propagators=tracecontext,baggage \
-Dotel.exporter.otlp.endpoint=http://127.0.0.1:5317 -jar target/demo-0.0.1-SNAPSHOT.jar
# Run go app
export OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:5317 OTEL_RESOURCE_ATTRIBUTES=service.name=k8s-combat
./k8s-combat
因为我们在 collector 中开启了 Debug 的 exporter,所以可以看到以下日志:
2024-07-22T06:34:08.060Z info MetricsExporter {"kind": "exporter", "data_type": "metrics", "name": "debug", "resource metrics": 1, "metrics": 18, "data points": 44}
此时是可以说明指标上传成功的。
然后我们打开 Prometheus 的地址:http://127.0.0.1:9292/graph
便可以查询到 Java 应用和 Go 应用上报的指标。
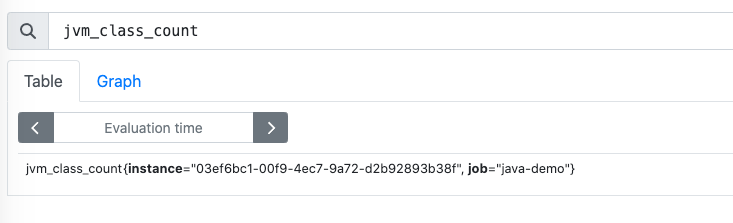
OpenTelemetry 的 javaagent 会自动上报 JVM 相关的指标。
而在 Go 程序中我们还是需要显式的配置一些埋点:
func initMeterProvider() *sdkmetric.MeterProvider {
ctx := context.Background()
exporter, err := otlpmetricgrpc.New(ctx)
if err != nil {
log.Printf("new otlp metric grpc exporter failed: %v", err)
}
mp := sdkmetric.NewMeterProvider(
sdkmetric.WithReader(sdkmetric.NewPeriodicReader(exporter)),
sdkmetric.WithResource(initResource()),
) otel.SetMeterProvider(mp)
return mp
}
mp := initMeterProvider()
defer func() {
if err := mp.Shutdown(context.Background()); err != nil {
log.Printf("Error shutting down meter provider: %v", err)
}
}()
和 Tracer 类似,我们首先也得在 main 函数中调用 initMeterProvider() 函数来初始化 Meter,此时它会返回一个 sdkmetric.MeterProvider 对象。
OpenTelemetry Go 的 SDK 中已经提供了对 go runtime 的自动埋点,我们只需要调用相关函数即可:
err := runtime.Start(runtime.WithMinimumReadMemStatsInterval(time.Second))
if err != nil {
log.Fatal(err)
}
之后我们启动应用,在 Prometheus 中就可以看到 Go 应用上报的相关指标了。
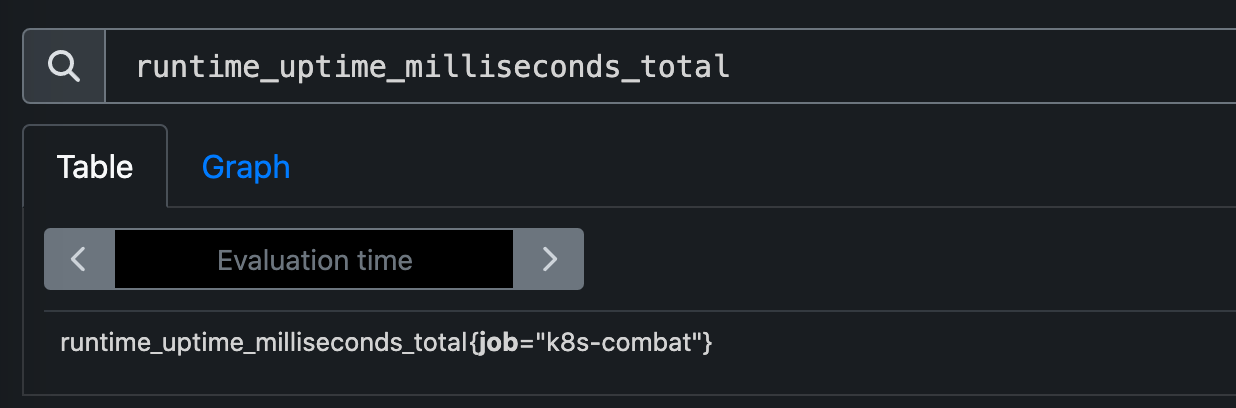
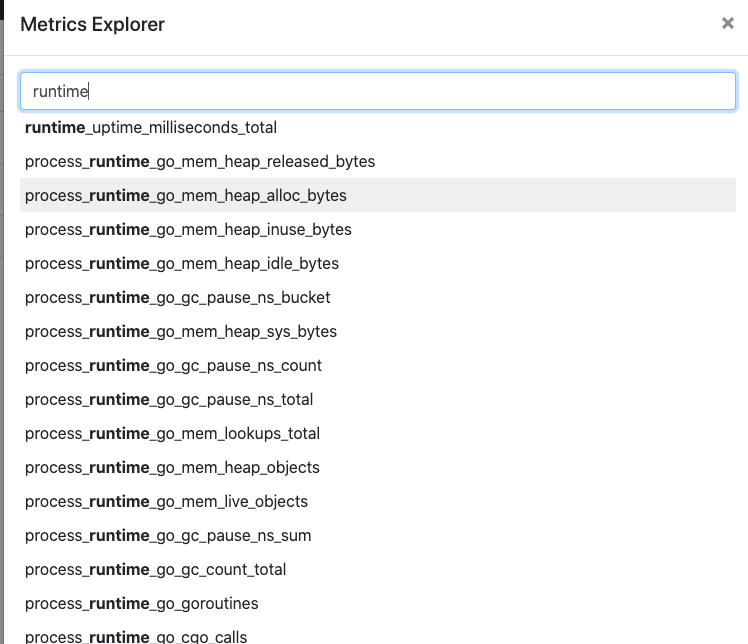
runtime_uptime_milliseconds_total Go 的运行时指标
Prometheus 中展示指标的 UI 能力有限,通常我们都是配合 grafana 进行展示的。
手动上报指标
当然除了 SDK 自动上报的指标之外,我们也可以类似于 trace 那样手动上报一些指标;
比如我就想记录某个函数调用的次数。
var meter = otel.Meter("test.io/k8s/combat")
apiCounter, err = meter.Int64Counter(
"api.counter",
metric.WithDescription("Number of API calls."),
metric.WithUnit("{call}"),
)
if err != nil {
log.Err(err)
}
func (s *server) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) {
defer apiCounter.Add(ctx, 1)
return &pb.HelloReply{Message: fmt.Sprintf("hostname:%s, in:%s, md:%v", name, in.Name, md)}, nil
}
只需要创建一个 Int64Counter 类型的指标,然后在需要埋点处调用它的函数 apiCounter.Add(ctx, 1) 即可。

之后便可以在 Prometheus 中查到这个指标了。
除此之外 OpenTelemetry 中的 metrics 定义和 Prometheus 也是类似的,还有以下几种类型:
- Counter:单调递增计数器,比如可以用来记录订单数、总的请求数。
- UpDownCounter:与 Counter 类似,只不过它可以递减。
- Gauge:用于记录随时在变化的值,比如内存使用量、CPU 使用量等。
- Histogram:通常用于记录请求延迟、响应时间等。
在 Java 中也提供有类似的 API 可以完成自定义指标:
messageInCounter = meter
.counterBuilder(MESSAGE_IN_COUNTER)
.setUnit("{message}")
.setDescription("The total number of messages received for this topic.")
.buildObserver();
对于 Gauge 类型的数据用法如下,使用 buildWithCallback 回调函数上报数据,OpenTelemetry 会在框架层面每 30s 回调一次。
public static void registerObservers() {
Meter meter = MetricsRegistration.getMeter();
meter.gaugeBuilder("pulsar_producer_num_msg_send")
.setDescription("The number of messages published in the last interval")
.ofLongs()
.buildWithCallback(
r -> recordProducerMetrics(r, ProducerStats::getNumMsgsSent));
private static void recordProducerMetrics(ObservableLongMeasurement observableLongMeasurement, Function<ProducerStats, Long> getter) {
for (Producer producer : CollectionHelper.PRODUCER_COLLECTION.list()) {
ProducerStats stats = producer.getStats();
String topic = producer.getTopic();
if (topic.endsWith(RetryMessageUtil.RETRY_GROUP_TOPIC_SUFFIX)) {
continue;
} observableLongMeasurement.record(getter.apply(stats),
Attributes.of(PRODUCER_NAME, producer.getProducerName(), TOPIC, topic));
}}
更多具体用法可以参考官方文档链接:
https://opentelemetry.io/docs/languages/java/instrumentation/#metrics
如果我们不想将数据通过 collector 而是直接上报到 Prometheus 中,使用 OpenTelemetry 框架也是可以实现的。
我们只需要配置下环境变量:
export OTEL_METRICS_EXPORTER=prometheus
这样我们就可以访问 http://127.0.0.1:9464/metrics 获取到当前应用暴露出来的指标,此时就可以在 Prometheus 里配置好采集 job 来获取数据。
scrape_configs:
- job_name: "k8s-combat"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["k8s-combat:9464"]
这就是典型的 Pull 模型,而 OpenTelemetry 推荐使用的是 Push 模型,数据由 OpenTelemetry 进行采集然后推送到 Prometheus。
这两种模式各有好处:
| Pull模型 | Push 模型 | |
|---|---|---|
| 优点 | 可以在一个集中的配置里管理所有的抓取端点,也可以为每一个应用单独配置抓取频次等数据。 | 在 OpenTelemetry 的 collector中可以集中对指标做预处理之后再将过滤后的数据写入 Prometheus,更加的灵活。 |
| 缺点 | 1. 预处理指标比较麻烦,所有的数据是到了 Prometheus 后再经过relabel处理后再写入存储。 2. 需要配置服务发现 |
1. 额外需要维护一个类似于 collector 这样的指标网关的组件 |
比如我们是用和 Prometheus 兼容的 VictoriaMetrics 采集了 istio 的相关指标,但里面的指标太多了,我们需要删除掉一部分。
就需要在采集任务里编写规则:
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMPodScrape
metadata:
name: isito-pod-scrape
spec:
podMetricsEndpoints:
- scheme: http
scrape_interval: "30s"
scrapeTimeout: "30s"
path: /stats/prometheus
metricRelabelConfigs:
- regex: ^envoy_.*|^url\_\_\_\_.*|istio_request_bytes_sum|istio_request_bytes_count|istio_response_bytes_sum|istio_request_bytes_sum|istio_request_duration_milliseconds_sum|istio_response_bytes_count|istio_request_duration_milliseconds_count|^ostrich_apigateway.*|istio_request_messages_total|istio_response_messages_total
action: drop_metrics
namespaceSelector:
any: true
换成在 collector 中处理后,这些逻辑都可以全部移动到 collector 中集中处理。
总结
metrics 的使用相对于 trace 更简单一些,不需要理解复杂的 context、span 等概念,只需要搞清楚有哪几种 metrics 类型,分别应用在哪些不同的场景即可。
参考链接:
- https://prometheus.io/docs/prometheus/latest/feature_flags/#otlp-receiver
- https://opentelemetry.io/docs/languages/java/instrumentation/#metrics
- https://opentelemetry.io/docs/languages/go/instrumentation/#metrics
OpenTelemetry 实战:从零实现应用指标监控的更多相关文章
- 图解JanusGraph系列 - JanusGraph指标监控报警(Monitoring JanusGraph)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录 源码分析相关可查看github(码文不易,求个sta ...
- 【03】SpringBoot2核心技术-核心功能—数据访问_单元测试_指标监控
3.数据访问(SQL) 3.1 数据库连接池的自动配置-HikariDataSource 1.导入JDBC场景 <dependency> <groupId>org.spring ...
- 业务监控-指标监控(v1)
最近做了指标监控系统的后台,包括需求调研.代码coding.调试调优测试等,穿插其他杂事等前后花了一个月左右. 指标监控指的是用户通过接口上传某些指标信息,并且通过配置阈值公式和告警规则等信息监测自己 ...
- 《Android Studio开发实战 从零基础到App上线》资源下载和内容勘误
转载于:https://blog.csdn.net/aqi00/article/details/73065392 资源下载 下面是<Android Studio开发实战 从零基础到App上线&g ...
- 『深度应用』NLP机器翻译深度学习实战课程·零(基础概念)
0.前言 深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内 ...
- Docker下实战zabbix三部曲之二:监控其他机器
在上一章<Docker下实战zabbix三部曲之一:极速体验>中,我们快速安装了zabbix server,并登录管理页面查看了zabbix server所在机器的监控信息,但是在实际场景 ...
- Docker下实战zabbix三部曲之三:自定义监控项
通过上一章<Docker下实战zabbix三部曲之二:监控其他机器>的实战,我们了解了对机器的监控是通过在机器上安装zabbix agent来完成的,zabbix agent连接上zabb ...
- 基于 prometheus 的微服务指标监控
基于prometheus的微服务指标监控 服务上线后我们往往需要对服务进行监控,以便能及早发现问题并做针对性的优化,监控又可分为多种形式,比如日志监控,调用链监控,指标监控等等.而通过指标监控能清晰的 ...
- SpringBoot第十二集:度量指标监控与异步调用(2020最新最易懂)
SpringBoot第十二集:度量指标监控与异步调用(2020最新最易懂) Spring Boot Actuator是spring boot项目一个监控模块,提供了很多原生的端点,包含了对应用系统的自 ...
- 关于hadoop的运行的一些指标监控(非cdh平台的)
在hadoop-env.sh中添加: # 在配置namenode和datanode时都会有用到JMX_OPTS的代码,是为了减少重复提取出的公共代码 export JMX_OPTS="-Dc ...
随机推荐
- mtr和traceroute的区别,以及为什么traceroute不显示路径mtr却可以显示路径
最近工作主要都是网络策略的开通和网络测试,在测试的过程当中发现当网络不通时,用traceroute来看路由路径的时候总是无法显示出来,于是就换了个工具-mtr,发现mtr可以正常显示出路由路径,帮助我 ...
- ONNX Runtime入门示例:在C#中使用ResNet50v2进行图像识别
ONNX Runtime简介 ONNX Runtime 是一个跨平台的推理和训练机器学习加速器.ONNX 运行时推理可以实现更快的客户体验和更低的成本,支持来自深度学习框架(如 PyTorch 和 T ...
- 【规范】Git分支管理,看看我司是咋整的
前言 缘由 Git分支管理好,走到哪里都是宝 事情起因: 最近翻看博客中小伙伴评论时,发现文章[规范]看看人家Git提交描述,那叫一个规矩一条回复: 本狗亲测在我司中使用规范的好处,遂把我司的Git分 ...
- python3 socket 获取域名信息
可以当ping用,应用场景可以在一些没有安装ping工具的镜像容器中,诊断dns或域名的可用性. #-*- coding:utf-8 -*- import socket import tracebac ...
- 拟合算法与matlab工具包实现
与插值问题不同,在拟合问题中不需要曲线一定经过给定的点.拟合问题的目标是寻求一个函数(曲线),使得该曲线在某种准则下与所有的数据点最为接近,即曲线拟合的最好(最小化损失函数) 目录 一.插值和拟合的区 ...
- Apifox 6月更新|定时任务、内网自部署服务器运行接口定时导入、数据库 SSH 隧道连接
Apifox 新版本上线啦!!! 看看本次版本更新主要涵盖的重点内容,有没有你所关注的功能特性: 自动化测试支持设置「定时任务」 支持内网自部署服务器运行「定时导入」 数据库均支持通过 SSH 隧道 ...
- MySQL执行过程及执行顺序
一.MySQL执行过程 简单概括: 1.我们在客户端发起一个SQL的查询: 2.连接器判断用户登录以及用户权限: 3.缓存命中,走缓存,直接返回查询结果: 3.缓存没命中,到达分析器,对SQL语句进行 ...
- Vue 框架怎么实现对象和数组的监听?
如果被问到 Vue 怎么实现数据双向绑定,大家肯定都会回答 通过 Object.defineProperty() 对数据进行劫持,但是 Object.defineProperty() 只能对属性进行数 ...
- SpringBoot全局异常,返回JSON数据
全局异常处理 为什么要配全局异常? 不配全局服务端报错场景,1/0.空指针等 配置好处 统一的错误页面或错误码 对用户更友好 配置全局异常 第一步类添加注解 @ControllerAdvicce,如果 ...
- ORACLE 如何判断某字段是否小于0
Oracle 自带的函数 SIGN 表达式的正 (+1).零 (0) 或负 (-1) 号 SQL> SELECT SIGN(-47.3), SIGN(0), SIGN(47.3) FROM du ...