绘图与可视化--pandas中的绘图函数
matplotlib API函数都位于matplotlib.pyplot模块中。
本节代码中引入的约定为:import matplotlib.pyplot as plt
numpy库也会用到,约定:import numpy as np
pandas库也会用到,约定:import pandas as pd
2 pandas中的绘图
matplotlib是一种比较低级的工具,要组装一张图表,你得用它得各种基础组件才行:数据展示(即图表类型:线型图、柱状图、盒型图、散布图、等值线图等)、图例、标题、刻度标签以及其它注释型信息。
在pandas中,有行标签、列标签及分组信息,要绘制一张图,需要很多matplotlib代码。pandas有很多能够利用DataFrame对象数据组织特点来创建标准图表的高级绘图方法。
2.1 线型图
Series和DataFrame都有一个用于生成各类图表的plot方法,默认情况下,生成的是线型图。
1 >>> s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
2 >>> s.plot()
3 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F35B8A898>
4 >>> plt.show()

该Series对象的索引会传给matplotlib,并用以绘制X轴,可通过use_index=False禁用该功能。X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim。
官方说明:pandas.Series.plot — pandas 1.3.4 documentation (pydata.org)
plot参数完整列表如下所示:
| 参数 | 说明 |
|---|---|
| label | 用于图例的标签 |
| ax | 要在其上进行绘制的matplotlib subplot对象,如果没有设置,则使用当前matplotlib subplot |
| style | 将要传给matplotlib的风格字符串(如’ko--’) |
| alpha | 图表的填充不透明度(0到1之间) |
| kind | 可以是’line’、’bar’、’barh’、’kde’ |
| logy | 在Y轴上使用对数标尺 |
| use_index | 将对象的的索引用作刻度标签 |
| rot | 旋转刻度标签(0到360) |
| xticks | 用作X轴刻度的值 |
| yticks | 用作Y轴刻度的值 |
| xlim | X轴的界限(例如[0, 10]) |
| ylim | Y轴的界限 |
| grid | 显示轴网格线(默认打开) |
pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。
DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例。
官方说明:pandas.DataFrame.plot — pandas 1.3.4 documentation (pydata.org)
1 >>> df = pd.DataFrame(np.random.randn(10, 4).cumsum(0), columns=['A', 'B', 'C', 'D'], index=np.arange(0, 100, 10))
2 >>> df.plot()
3 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F35B8AFD0>
4 >>> plt.show()
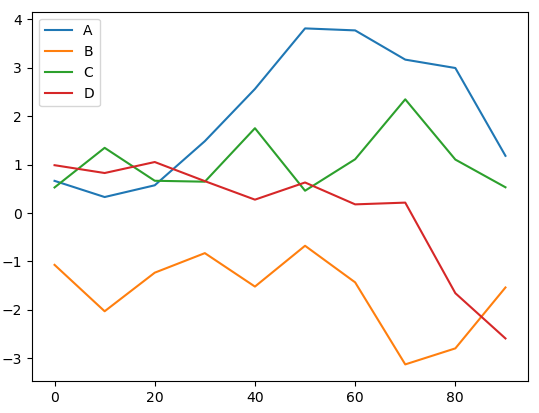
DataFrame还有一些用于对列进行灵活处理的选项。下表是专用于DataFrame的plot参数。
| 参数 | 说明 |
|---|---|
| subplots | 将各个DataFrame列绘制到单独的subplot中 |
| sharex | 如果subplots=True,则共用同一个X轴,包括刻度和界限 |
| sharey | 如果subplots=True,则共用同一个Y轴 |
| figsize | 表示图像大小的元组 |
| title | 表示图像标题的字符串 |
| legend | 添加一个subplot实例(默认为True) |
| sort_columns | 以字母顺序绘制各列,默认使用当前列顺序 |
2.2 柱状图
在生成线性图的代码中加上kind=’bar’(垂直柱状图)或kind=’barh’(水平柱状图)即可生成柱状图。这时,Series和DataFrame的索引将会被当作X(bar)或Y(barh)刻度。
1 >>> fig, axes = plt.subplots(2, 1)
2 >>> data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
3 >>> data.plot(kind='bar', ax=axes[0], color='k', alpha=0.7)
4 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F37F3FE48>
5 >>> data.plot(kind='barh', ax=axes[1], color='k', alpha=0.7)
6 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F37F794A8>
7 >>> plt.show()
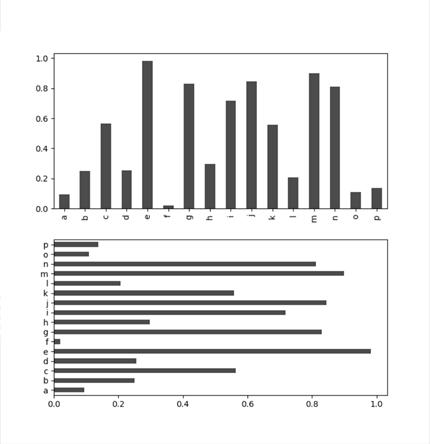
对于DataFrame,柱状图会将每一行的值分为一组。
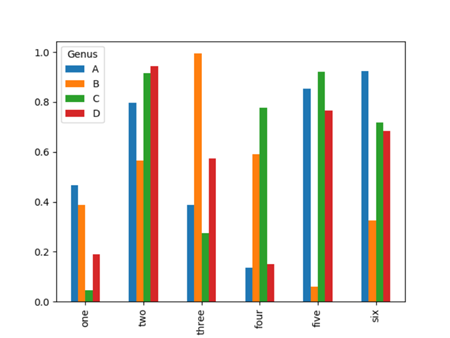
1 >>> df = pd.DataFrame(np.random.rand(6, 4), index=['one', 'two', 'three', 'four', 'five', 'six'], columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
2 >>> df
3 Genus A B C D
4 one 0.466419 0.388390 0.045920 0.188829
5 two 0.795635 0.566636 0.916473 0.944628
6 three 0.386224 0.993829 0.273204 0.573622
7 four 0.134991 0.591803 0.778073 0.150384
8 five 0.854561 0.058758 0.922147 0.764897
9 six 0.923109 0.324739 0.717597 0.682992
10 >>> df.plot(kind='bar')
11 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F37FB1F28>
12 >>> plt.show()
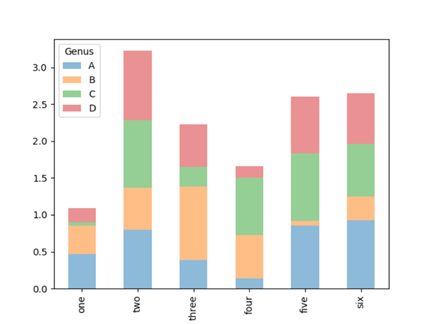
设置stacked=True即可生成堆积柱状图,每行的值会被堆积在一起。
1 >>> df.plot(kind='bar', stacked=True, alpha=0.5)
2 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F3A2F2048>
3 >>> plt.show()
2.3 直方图和密度图
直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。
1 >>> s
2 0 -0.674014
3 1 0.342018
4 2 -0.189962
5 3 0.528294
6 4 1.597546
7 5 1.530765
8 6 2.699712
9 7 1.422388
10 8 -1.295660
11 9 -1.539913
12 dtype: float64
13 >>> s.hist(bins=5)
14 <matplotlib.axes._subplots.AxesSubplot object at 0x000002295B737978>
15 >>> plt.show()
与此相关的一种图表类型是密度图,它是通过计算“可能产生观测数据的连续概率分布的估计”而产生的。一般的过程是将该部分近似为一组核(即诸如正态(高斯)分布之类的较为简单的分布)。因此,密度图也被称为KDE(kernel density estimate核密度估计)图。调用plot时加上kind=’kde’即可生成一张密度图(标准混合正态分布KDE)。
1 >>> import scipy
2 >>> s.plot(kind='kde')
3 <matplotlib.axes._subplots.AxesSubplot object at 0x0000022959D0DA90>
4 >>> plt.show()
5 >>> s
6 0 -0.674014
7 1 0.342018
8 2 -0.189962
9 3 0.528294
10 4 1.597546
11 5 1.530765
12 6 2.699712
13 7 1.422388
14 8 -1.295660
15 9 -1.539913
16 dtype: float64
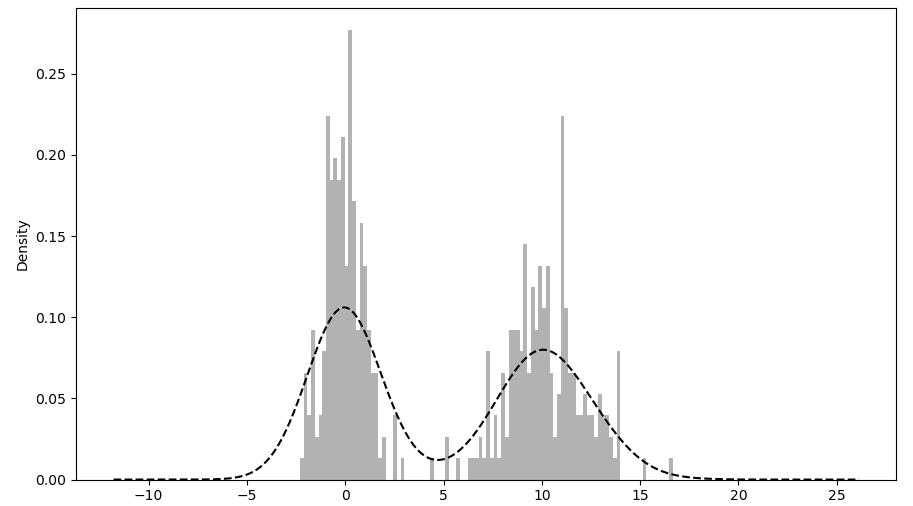
这两种图形常常画在一起,直方图以规格化形式给出(以便给出画元化密度),然后再在其上绘制核密度估计。下面给一个由两个不同的标准正态分布组成的双峰分布。
1 >>> comp1 = np.random.normal(0, 1, size=200)
2 >>> comp2 = np.random.normal(10, 2, size=200)
3 >>> values = pd.Series(np.concatenate([comp1, comp2]))
4 >>> values.hist(bins=100, alpha=0.3, color='k', density=True)
5 <matplotlib.axes._subplots.AxesSubplot object at 0x0000022959CFC6D8>
6 >>> values.plot(kind='kde', style='k--')
7 <matplotlib.axes._subplots.AxesSubplot object at 0x0000022959CFC6D8>
8 >>> plt.show()
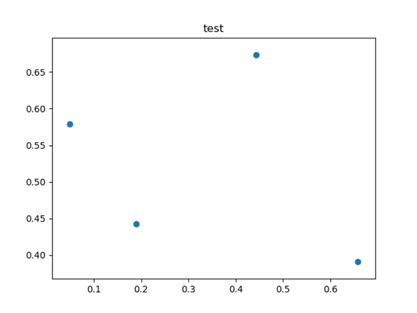
2.4 散布图
散布图(scatter plot)是观察两个一维数据序列之间关系的有效手段,matplotlib的scatter方法是绘制散布图的主要方法。
1 >>> df = pd.DataFrame(np.random.rand(4, 2), index=[1, 2, 3, 4], columns=['one', 'two'])
2 >>> df
3 one two
4 1 0.658181 0.390797
5 2 0.443482 0.673915
6 3 0.188783 0.442284
7 4 0.048783 0.578914
8 >>> plt.scatter(df['one'], df['two'])
9 <matplotlib.collections.PathCollection object at 0x000002295D2D77B8>
10 >>> plt.title('test')
11 Text(0.5, 1.0, 'test')
12 >>> plt.show()
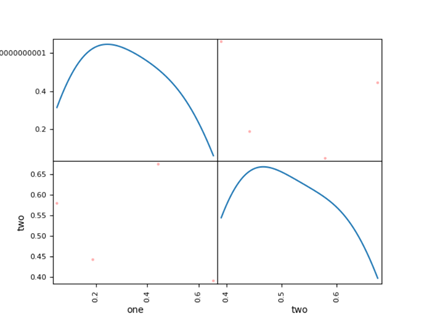
在探索式数据分析中,同时观察一组变量的散布图很有意义,这也被称为散布矩阵(scatter plot matrix)。pandas提供了从DataFrame创建散布图矩阵的scatter_matrix函数。还支持在对角线上放置各变量的直方图和密度图。
1 >>> df
2 one two
3 1 0.658181 0.390797
4 2 0.443482 0.673915
5 3 0.188783 0.442284
6 4 0.048783 0.578914
7 >>> pd.plotting.scatter_matrix(df, diagonal='kde', color='r', alpha=0.3)
8 array([[<matplotlib.axes._subplots.AxesSubplot object at 0x000002295D23D860>,
9 <matplotlib.axes._subplots.AxesSubplot object at 0x000002295D1A4940>],
10 [<matplotlib.axes._subplots.AxesSubplot object at 0x000002295D09EEF0>,
11 <matplotlib.axes._subplots.AxesSubplot object at 0x000002295D0DC4E0>]],
12 dtype=object)
13 >>> plt.show()
绘图与可视化--pandas中的绘图函数的更多相关文章
- 分位函数(四分位数)概念与pandas中的quantile函数
p分位函数(四分位数)概念与pandas中的quantile函数 函数原型 DataFrame.quantile(q=0.5, axis=0, numeric_only=True, interpola ...
- 四分位数与pandas中的quantile函数
四分位数与pandas中的quantile函数 1.分位数概念 统计学上的有分位数这个概念,一般用p来表示.原则上p是可以取0到1之间的任意值的.但是有一个四分位数是p分位数中较为有名的. 所谓四分位 ...
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- pandas中的quantile函数
https://blog.csdn.net/weixin_38617311/article/details/87893168 data.price.quantile([0.25,0.5,0.75]) ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- 《利用python进行数据分析》读书笔记--第八章 绘图和可视化
http://www.cnblogs.com/batteryhp/p/5025772.html python有许多可视化工具,本书主要讲解matplotlib.matplotlib是用于创建出版质量图 ...
- Python之绘图和可视化
Python之绘图和可视化 1. 启用matplotlib 最常用的Pylab模式的IPython(IPython --pylab) 2. matplotlib的图像都位于Figure对象中. 可以使 ...
- 利用python进行数据分析之绘图和可视化
matplotlib API入门 使用matplotlib的办法最常用的方式是pylab的ipython,pylab模式还会向ipython引入一大堆模块和函数提供一种更接近与matlab的界面,ma ...
- 《python for data analysis》第八章,绘图与可视化
<利用python进行数据分析>一书的第8章,关于matplotlib库的使用,各小节的代码. # -*- coding:utf-8 -*-import numpy as npimport ...
- IPython绘图和可视化---matplotlib 入门
最近总是需要用matplotlib绘制一些图,由于是新手,所以总是需要去翻书来找怎么用,即使刚用过的,也总是忘.所以,想写一个入门的教程,一方面帮助我自己熟悉这些函数,另一方面有比我还小白的新手可以借 ...
随机推荐
- 飞桨PaddlePaddle的安装
飞桨PaddlePaddle的安装 MacOS 下的 PIP 安装 一.环境准备 1.1 如何查看您的环境 可以使用以下命令查看本机的操作系统和位数信息: uname -m && ca ...
- CSP 考前集训 10/15
\({\color{Green} \mathrm{A\ -\ 染色}}\) 观察此题,我们可以发现正序维护不好求,会有红点被覆盖等情况. 考虑倒着求,每一次如果操作是红那么久看区间内有多少已经染色的点 ...
- 五分钟学会使用 go modules(含在家办公使用技巧)
导读:go modules 是 golang 1.11 新加的特性.如今 1.13 都已经发布了第 7 个小版本了,几乎所有大项目均已开始使用,这自然也包括 Kubernetes 生态中的众多项目.笔 ...
- RocketMQ 5.0: 存储计算分离新思路
简介: 在阿里云上,RocketMQ 的商业化产品也以弹性云服务的形式为全球数万个用户提供企业级的消息解决方案,被广泛应用于互联网.大数据.移动互联网.物联网等领域的业务场景,成为了业务开发的首选消息 ...
- Spark 大数据处理最佳实践
开源大数据社区 & 阿里云 EMR 系列直播 第十一期 主题:Spark 大数据处理最佳实践 讲师:简锋,阿里云 EMR 数据开发平台 负责人 内容框架: 大数据概览 如何摆脱技术小白 Spa ...
- [FE] yarn, npm 切换镜像源
yarn 设置命令如下,会修改 ~/.yarnrc 内容. $ yarn config set registry https://registry.yarnpkg.com npm 设置命令如下,会修改 ...
- [Caddy2] Caddyfile 概念预览
结构 块: 所有的指令必须在 { } 块中,如果只有一个站点,则块标记可以省略. 全局的配置块可以放在最上方,其次是站点的配置块. 指令: 指令是服务于站点配置的关键词. 关键词和引号: 空格在 Ca ...
- [FAQ] Solidity 实现倒计时 (count down) ?
思路:一种方式是使用 ethereum-alarm-clock,另一种是合约实现当前过去了多少时间,外部进行不间断调用获得. Any else? Refer:Solidity能倒计时吗 Link:ht ...
- Git的操作使用
Git结构: # 工作区:当前编辑的区域 # 缓存区:add之后的区域 # 本地仓库:commit之后的区域 # 远程仓库:GitHub,gitlab,码云... 一.Git的初步认识 一.Git是什 ...
- ide构建SpringMVC框架
框架原理图如下: 1. 创建如图项目 2. 在lib中所需导入jar包 3. 配置变量 (1) (2)add library (3)选择web app libraries 4. 配置web.xml文件 ...