Bi-encoder vs Cross encoder?
本文永久地址:https://wanger-sjtu.github.io/encoder-cross-bi/
Bi-encoder和Cross-encoder是在自然语言理解任务模型的两种不同方法,在信息检索和相似性搜索二者的使用更为广泛。在LLM大火的今天,RAG的pipe line中这两个模块作为提升检索精度的模块更是备受瞩目。
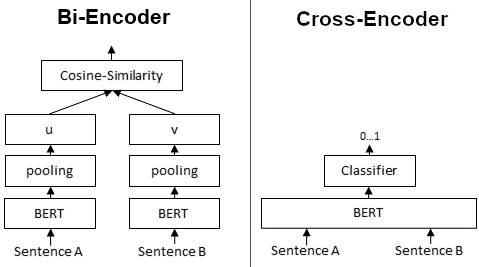
Bi-encoder:
- 架构:在Bi-encoder模型中,有两个独立的编码器——一个用于编码输入的查询,另一个用于编码候选文档。这些编码器独立工作,为查询和每个文档生成嵌入表示。
- 训练:在训练期间,模型被训练以最大化查询与相关文档之间的相似性,同时最小化查询与不相关文档之间的相似性。训练通常使用对比损失函数进行。
- 评分:在推理时,模型独立计算查询与每个文档之间的相似性得分。相似性得分最高的文档被认为是最相关的。
使用案例:Bi-encoder通常用于文档检索或排名是主要目标的任务,如搜索引擎或推荐系统。
双编码器为给定句子生成句子嵌入。我们独立地将句子A和句子B传递给BERT,分别得到句子嵌入u和v。然后可以使用余弦相似度来比较这些句子嵌入。
Cross-encoder
架构:在Cross-encoder模型中,查询和文档一起在单个编码器中处理。这意味着模型将查询和文档作为输入,并产生联合表示。
训练:与Bi-encoder类似,Cross-encoder被训练以最大化相关查询-文档对之间的相似性。但是,由于它们同时处理查询和文档,因此它们捕获了两者之间的交互。
评分:Cross-encoder为每个查询-文档对生成单一的相似性得分,考虑了查询和文档嵌入之间的交互。得分最高的文档被认为是最相关的。
使用案例:当捕获查询和文档之间的交互对于您的任务至关重要时,Cross-encoder非常有用,例如在理解查询和文档之间的上下文或关系很重要的任务中。
比较
Bi-encoder:当您拥有大规模数据集和计算资源时,使用Bi-encoder。由于相似性得分可以独立计算,它们在推理期间通常更快。它们适用于捕获查询和文档之间复杂交互不太关键的任务。
Cross-encoder:当捕获查询和文档之间的交互对于您的任务至关重要时,请选择Cross-encoder。它们在计算上更为密集,但可以在理解查询和文档之间的上下文或关系至关重要的场景中提供更好的性能。
Bi-encoder vs Cross encoder?的更多相关文章
- C# 字符编码解码 Encoder 和Decoder
在网络传输和文件操作中,如果数据量很大,需要将其划分为较小的快,此时可能出现一个数据块的末尾是一个不匹配的高代理项,而与其匹配的低代理项在下一个数据块. 这时候使用Encoding的GetBytes方 ...
- 使用VAE、CNN encoder+孤立森林检测ssl加密异常流的初探——真是一个忧伤的故事!!!
ssl payload取1024字节,然后使用VAE检测异常的ssl流. 代码如下: from sklearn.model_selection import train_test_split from ...
- Auto Encoder用于异常检测
对基于深度神经网络的Auto Encoder用于异常检测的一些思考 from:https://my.oschina.net/u/1778239/blog/1861724 一.前言 现实中,大部分数据都 ...
- 如何将位置值写入simotion encoder?
目标: 将变量值(任意实数)写入Encoder,作为encoder的实际位置值.例如,将MP177手轮的值写入编码器,达到SMC30配置手轮的功能. Platform: simotion D435-2 ...
- 论文解读(AGE)《Adaptive Graph Encoder for Attributed Graph Embedding》
论文信息 论文标题:Adaptive Graph Encoder for Attributed Graph Embedding论文作者:Gayan K. Kulatilleke, Marius Por ...
- WHAT IS PPM Encoder ?
About PPM Encoder The PPM encoder allows to encode up to 8 PWM (pulse width modulated) signals into ...
- 打水印 Imagename_biao是水印文件 ImgName是原图
/** * 打水印 Imagename_biao是水印文件 ImgName是原图 * @param Imagename_biao * @param ImgName */ public static v ...
- 【Python与机器学习】:利用Keras进行多类分类
多类分类问题本质上可以分解为多个二分类问题,而解决二分类问题的方法有很多.这里我们利用Keras机器学习框架中的ANN(artificial neural network)来解决多分类问题.这里我们采 ...
- ImageEdit 加载图片
从本地加载图片 <dxe:ImageEdit Name="iePortrait" Height="120" Width="100" S ...
- Machine Learning : Pre-processing features
from:http://analyticsbot.ml/2016/10/machine-learning-pre-processing-features/ Machine Learning : Pre ...
随机推荐
- ImportError: Cannot load backend 'TkAgg' which requires the 'tk' interactive framework, as 'headless' is currently running
MMdetection多卡训练常遇到的两个错误,百度无果,没解决,去github里mmdetection的issue模块搜索了一下找到正解. 这里记录一下,方便后者. 1️⃣ ImportError: ...
- Bogus 实战:使用 Bogus 和 EFCore 生成模拟数据和种子数据【完整教程】
引言 上一章我们介绍了在xUnit单元测试中用xUnit.DependencyInject来使用依赖注入,上一章我们的Sample.Repository仓储层有一个批量注入的接口没有做单元测试,今天用 ...
- shell脚本中的运算符和条件判断
shell脚本中的运算符和条件判断: 一.算术运算符 在Shell脚本中,你可以使用各种运算符来执行数学运算.比较和逻辑操作. 计算方式: $[ ] $(( )) 例: a=$[(9+5)90] 打印 ...
- 动态尺寸模型优化实践之Shape Constraint IR Part I
简介: 在本系列分享中我们将介绍BladeDISC在动态shape语义下做性能优化的一些实践和思考.本次分享的是我们最近开展的有关shape constraint IR的工作,Part I 中我们将介 ...
- 浅谈 Node.js 热更新
简介: 记得在 15 16 年那会 Node.js 刚起步的时候,我在去前东家的入职面试也被问到了要如何实现 Node.js 服务的热更新. 记得在 15 16 年那会 Node.js 刚起步的时候, ...
- 急速上线 Serverless 钉钉机器人“防疫精灵”
新型冠状病毒疫情肆虐的春节,大家都过得人心惶惶,作为被关在家的程序狗,总觉得要做点什么.于是阿里云 IoT 事业部的几个同学就开始了防疫精灵的开发之路. 从点子到防疫宝,只花了一个下午时间:从防疫宝到 ...
- 从图森未来的数据处理平台,看Serverless工作流应用场景
4月,阿里云Serverless工作流正式商业化,这是一款用于协调多个分布式任务执行的全托管 Serverless 云服务.产品致力于简化开发和运行业务流程所需要的任务协调.状态管理以及错误处理等繁琐 ...
- 重磅官宣:Nacos2.0发布,性能提升10倍
简介: Nacos2.0 作为一个跨代版本,彻底解决了 Nacos1.X 的性能问题,将性能提升了 10 倍. 作者:席翁 继 Nacos 1.0 发布以来,Nacos 迅速被成千上万家企业采用,并 ...
- 双11特刊|十年磨一剑,云原生多模数据库Lindorm 2021双11总结
前言 2021 年,转眼 Lindorm 已经在阿里发展了十年的时间,从基于 HBase 深度改造的 Lindorm 1.0 版本,到全面重构,架构大幅升级的 Lindorm 2.0 版本:从单一的 ...
- [Linux] 日志管理: rsyslogd 服务 (检测启动/自启动/日志位置)
查看 rsyslogd 服务是否已启动: ps aux | grep rsyslogd 查看 rsyslogd 是否设置了自启动: systemctl status rsyslog 或者 servic ...