Bi-encoder vs Cross encoder?
本文永久地址:https://wanger-sjtu.github.io/encoder-cross-bi/
Bi-encoder和Cross-encoder是在自然语言理解任务模型的两种不同方法,在信息检索和相似性搜索二者的使用更为广泛。在LLM大火的今天,RAG的pipe line中这两个模块作为提升检索精度的模块更是备受瞩目。
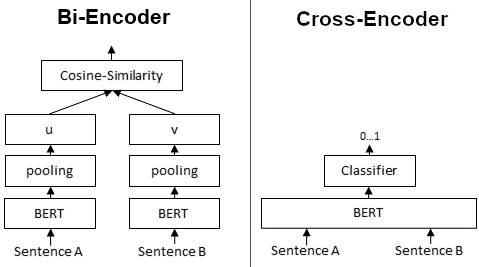
Bi-encoder:
- 架构:在Bi-encoder模型中,有两个独立的编码器——一个用于编码输入的查询,另一个用于编码候选文档。这些编码器独立工作,为查询和每个文档生成嵌入表示。
- 训练:在训练期间,模型被训练以最大化查询与相关文档之间的相似性,同时最小化查询与不相关文档之间的相似性。训练通常使用对比损失函数进行。
- 评分:在推理时,模型独立计算查询与每个文档之间的相似性得分。相似性得分最高的文档被认为是最相关的。
使用案例:Bi-encoder通常用于文档检索或排名是主要目标的任务,如搜索引擎或推荐系统。
双编码器为给定句子生成句子嵌入。我们独立地将句子A和句子B传递给BERT,分别得到句子嵌入u和v。然后可以使用余弦相似度来比较这些句子嵌入。
Cross-encoder
架构:在Cross-encoder模型中,查询和文档一起在单个编码器中处理。这意味着模型将查询和文档作为输入,并产生联合表示。
训练:与Bi-encoder类似,Cross-encoder被训练以最大化相关查询-文档对之间的相似性。但是,由于它们同时处理查询和文档,因此它们捕获了两者之间的交互。
评分:Cross-encoder为每个查询-文档对生成单一的相似性得分,考虑了查询和文档嵌入之间的交互。得分最高的文档被认为是最相关的。
使用案例:当捕获查询和文档之间的交互对于您的任务至关重要时,Cross-encoder非常有用,例如在理解查询和文档之间的上下文或关系很重要的任务中。
比较
Bi-encoder:当您拥有大规模数据集和计算资源时,使用Bi-encoder。由于相似性得分可以独立计算,它们在推理期间通常更快。它们适用于捕获查询和文档之间复杂交互不太关键的任务。
Cross-encoder:当捕获查询和文档之间的交互对于您的任务至关重要时,请选择Cross-encoder。它们在计算上更为密集,但可以在理解查询和文档之间的上下文或关系至关重要的场景中提供更好的性能。
Bi-encoder vs Cross encoder?的更多相关文章
- C# 字符编码解码 Encoder 和Decoder
在网络传输和文件操作中,如果数据量很大,需要将其划分为较小的快,此时可能出现一个数据块的末尾是一个不匹配的高代理项,而与其匹配的低代理项在下一个数据块. 这时候使用Encoding的GetBytes方 ...
- 使用VAE、CNN encoder+孤立森林检测ssl加密异常流的初探——真是一个忧伤的故事!!!
ssl payload取1024字节,然后使用VAE检测异常的ssl流. 代码如下: from sklearn.model_selection import train_test_split from ...
- Auto Encoder用于异常检测
对基于深度神经网络的Auto Encoder用于异常检测的一些思考 from:https://my.oschina.net/u/1778239/blog/1861724 一.前言 现实中,大部分数据都 ...
- 如何将位置值写入simotion encoder?
目标: 将变量值(任意实数)写入Encoder,作为encoder的实际位置值.例如,将MP177手轮的值写入编码器,达到SMC30配置手轮的功能. Platform: simotion D435-2 ...
- 论文解读(AGE)《Adaptive Graph Encoder for Attributed Graph Embedding》
论文信息 论文标题:Adaptive Graph Encoder for Attributed Graph Embedding论文作者:Gayan K. Kulatilleke, Marius Por ...
- WHAT IS PPM Encoder ?
About PPM Encoder The PPM encoder allows to encode up to 8 PWM (pulse width modulated) signals into ...
- 打水印 Imagename_biao是水印文件 ImgName是原图
/** * 打水印 Imagename_biao是水印文件 ImgName是原图 * @param Imagename_biao * @param ImgName */ public static v ...
- 【Python与机器学习】:利用Keras进行多类分类
多类分类问题本质上可以分解为多个二分类问题,而解决二分类问题的方法有很多.这里我们利用Keras机器学习框架中的ANN(artificial neural network)来解决多分类问题.这里我们采 ...
- ImageEdit 加载图片
从本地加载图片 <dxe:ImageEdit Name="iePortrait" Height="120" Width="100" S ...
- Machine Learning : Pre-processing features
from:http://analyticsbot.ml/2016/10/machine-learning-pre-processing-features/ Machine Learning : Pre ...
随机推荐
- mysql 必知必会整理—数据汇总与分组[七]
前言 简单整理一下数据汇总与分组 正文 我们经常需要汇总数据而不用把它们实际检索出来,为此MySQL提供了专门的函数.使用这些函数,MySQL查询可用于检索数据,以便分析和报表生成. 这种类型的检索例 ...
- 论文记载:A Survey on Traffic Signal Control Methods
ABSTRACT 交通信号控制是一个重要且具有挑战性的现实问题,其目标是通过协调车辆在道路交叉口的移动来最小化车辆的行驶时间.目前使用的交通信号控制系统仍然严重依赖过于简单的信息和基于规则的方法,尽管 ...
- ES6---new Promise()使用方法
2015年6月份, ES2015正式发布(也就是ES6,ES6是它的乳名),其中Promise被列为正式规范.作为ES6中最重要的特性之一,我们有必要掌握并理解透彻.本文将由浅到深,讲解Promise ...
- 力扣459(java)-重复的子字符串(简单)
题目: 给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成. 示例 1: 输入: s = "abab"输出: true解释: 可由子串 "ab&quo ...
- 力扣9(java)-回文数(简单)
题目: 给你一个整数 x ,如果 x 是一个回文整数,返回 true :否则,返回 false . 回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数. 例如,121 是回文,而 123 不 ...
- 实时化或成必然趋势?新一代 Serverless 实时计算引擎
作者:高旸(吾与),阿里巴巴高级产品专家 本文由阿里巴巴高级产品专家高旸(吾与)分享,主要介绍新一代Serverless实时计算引擎的产品特性及核心功能. 一.实时计算 Flink 版 – 产品定位与 ...
- 开源微服务运行时 Dapr 发布 1.0 版本
简介: Dapr 是 2019 年 10 月开源的分布式运行时.早在 Dapr 开源初期,阿里云就开始参与 Dapr 社区建设和代码开发,目前已有两位 Dapr 成员,是 Dapr 项目中除微软之外代 ...
- OpenYurt 深度解读|开启边缘设备的云原生管理能力
简介: 北京时间 9 月 27 号,OpenYurt 发布 v0.5.0 版本.新发布版本中首次提出 kubernetes-native非侵入.可扩展的边缘设备管理标准,使 Kubernetes 业 ...
- dotnet 读 WPF 源代码笔记 简单聊聊文本布局换行逻辑
在 WPF 里面,带了基础的文本库功能,如 TextBlock 等.文本库排版的重点是在文本的分行逻辑,也就是换行逻辑,如何计算当前的文本字符串到达哪个字符就需要换到下一行的逻辑就是文本布局的重点模块 ...
- CMake 教程(待完善)
Cmake 教程 写在前面 如果工程只有几个文件,直接编写Makefile更直接明了 如果使用C.C++.之外的语言,请不要使用cmake 如果使用的语言有非常完备的构建体系,不需要使用cmake C ...