OLAP分析型应用场景中,数仓中vacuum为何对列存表无效
摘要:对列存表执行vacuum为什么是无效的呢?其实这与列存表的存储结构以及数据写入方式有关。
本文分享自华为云社区《GaussDB(DWS)中vacuum为何对列存表无效?【这次高斯不是数学家】》,作者: i云上小白。
在OLAP分析型应用场景中,列式存储有十分明显的优势,相比行式存储,其高压缩比、高I/O效率及批量数据运算的特性极大提升了统计分析查询的效率。虽然存储模式不同,对列存表进行频繁的插入(insert)和更新(update)操作仍然会导致空间膨胀问题,实际上在很多时候,往往不建议对列存表进行数据更新和非批量方式的数据插入。
基于GaussDB(DWS)的mvcc机制,行存表在删除、更新数据时会保留原来的旧数据,这些数据我们称之为死元组(dead tuple)。频繁地对行存表执行删除和更新操作会导致数据页中产生大量的死元组,不但使存储空间膨胀,而且降低了对表的查询效率。针对这一现象,GaussDB(DWS)采用vacuum机制来清除不需要的死元组及索引,释放空间。但对于列存表来说,vacuum是无效的,必须使用vacuum full才能有效回收空间。
当然对行存表执行vacuum回收空间是有限的,在某些情况下vacuum后的表大小甚至不会有丝毫变化。这是因为如果删除的记录位于表的末端,其所占用的空间将会被物理释放并归还操作系统,而如果不是末端数据,会将表中或索引中dead tuple所占用的空间置为可用状态,从而复用这些空间。
对列存表执行vacuum为什么是无效的呢?其实这与列存表的存储结构以及数据写入方式有关。
从下图中可知,列存表的最小存储单元是CU(Compress Unit),每个CU的大小为8KB的整数倍(需要注意的是,CU并不是由页组成的,它是一个独立的存储单元),最多存储1列60000行数据。同一列的多个CU连续存放在一个数据文件中,当数据文件的大小超过1G,会自动切换到新的文件中。
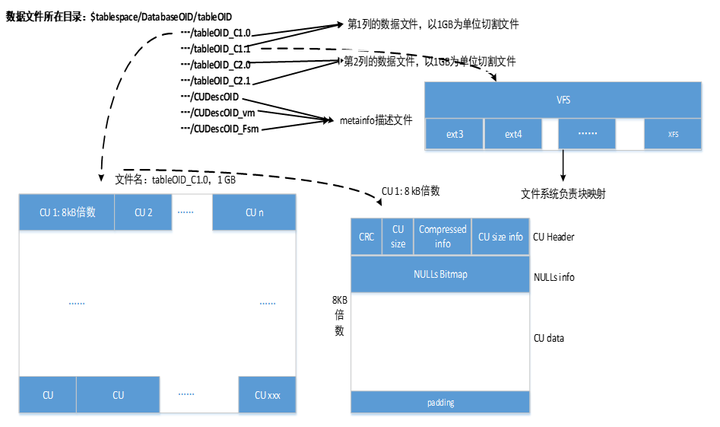
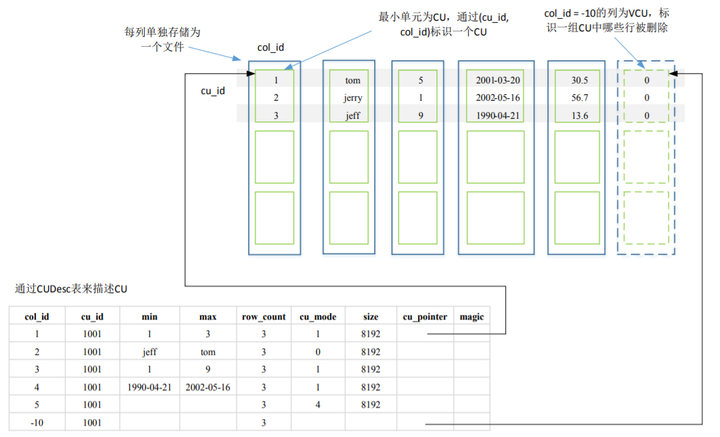
除此之外,每个列存表还有一个记录CU的辅助和管理信息的行存表CUDesc表,该表中的每一行记录对应一个CU,包括最大值/最小值、数据条数,以及CU在文件中的偏移量及大小。其中,col_id=-10的行为VCU, cu_pointer记录这一组CU(cu_id相同)中哪些行被删除。另外,CU的可见性也是通过CUDesc的可见性来决定的。
当在列存表上导入数据时,首先数据会按列导入CU cache,如果设置了PCK(Partial Cluster Key),导入数据会按照指定列进行局部排序(默认420万条数据进行排序),最后再生成CU(生成CU时,会根据数据类型进行压缩),并写入文件。列存表推荐使用批量方式导入数据,如insert into select/copy、GDS、SQL on Hadoop/OBS等,这样可以充分利用CU空间,以及使用PCK索引。单行数据插入会产生较多的小CU文件,不但会造成空间浪费,还会导致访问效率降低。因此对于列存表的数据导入,强烈推荐使用批量方式。

下面我们看看列存表上的删除和更新操作是如何进行的。
在列存表上进行delete时,首先会根据删除条件找到需要删除的行ctid(cu_id,offset),然后对需要删除的行ctid去重(每420万行排序去重),最后在行对应的VCU的delete map上打上删除标记。至于update操作,实际上是一个delete+insert(append)操作。首先根据更新条件找到更新的行,打上删除标记(ctid需去重),然后将原来整行更新相应数据后,插入到新CU中。
对行存表来说,数据页中的每个元组都占用了一块独立的空间,每个元组有一个行指针,记录了这个元组的状态。当执行update或者delete操作后,死元组的行指针lp_flags的状态会被标记为3: LP_DEAD,即死亡状态,等待vacuum清理。倘若执行了vacuum,指针状态会被标记为0: LP_UNUSED,即未使用状态,表示该元组占用的空间可以被复用。
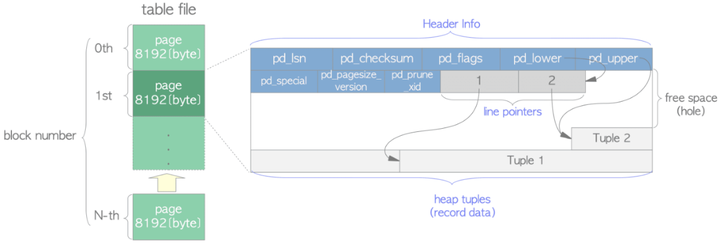
虽然列存表可以像行存表那样对被删除或者更新前的数据进行标记,但由于CU中的数据是按列连续存放的,CU生成数据后固定不可更改。如果使用指针对每一个数据位的状态进行标记,其代价较大(行指针长度几乎等于数据长度,同时I/O开销巨大),而且数据写入CU采用的是追写(append)方式,即便死元组被标记为可复用状态,也无法再使用这些空间。
另外,列存表的读取是以CU为单位,真正影响列存表性能的是CU文件数量,而vacuum即便可以回收死元组占用的空间,却不能合并小CU文件。因此,对列存表来说,vacuum是无效的。此时,可以使用vacuum full整理CU碎片,合并小CU文件,提升性能。
OLAP分析型应用场景中,数仓中vacuum为何对列存表无效的更多相关文章
- 在HUE中将文本格式的数据导入hive数仓中
今天有一个需求需要将一份文档形式的hft与fdd的城市关系关系的数据导入到hive数仓中,之前没有在hue中进行这项操作(上家都是通过xshell登录堡垒机直接连服务器进行操作的),特此记录一下. - ...
- Hive 数仓中常见的日期转换操作
(1)Hive 数仓中一些常用的dt与日期的转换操作 下面总结了自己工作中经常用到的一些日期转换,这类日期转换经常用于报表的时间粒度和统计周期的控制中 日期变换: (1)dt转日期 to_date(f ...
- 一文读懂数仓中的pg_stat
摘要:GaussDB(DWS)在SQL执行过程中,会记录表增删改查相关的运行时统计信息,并在事务提交或回滚后记录到共享的内存中.这些信息可以通过 "pg_stat_all_tables视图& ...
- HAWQ取代传统数仓实践(十六)——事实表技术之迟到的事实
一.迟到的事实简介 数据仓库通常建立于一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中.当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维 ...
- HAWQ取代传统数仓实践(十五)——事实表技术之无事实的事实表
一.无事实事实表简介 在多维数据仓库建模中,有一种事实表叫做"无事实的事实表".普通事实表中,通常会保存若干维度外键和多个数字型度量,度量是事实表的关键所在.然而在无事实的事实表中 ...
- HAWQ取代传统数仓实践(十四)——事实表技术之累积快照
一.累积快照简介 累积快照事实表用于定义业务过程开始.结束以及期间的可区分的里程碑事件.通常在此类事实表中针对过程中的关键步骤都包含日期外键,并包含每个步骤的度量,这些度量的产生一般都会滞后于数据行的 ...
- AWK文本分析工具-常用场景(持续更新中)
AWK help document:http://www.gnu.org/software/gawk/manual/gawk.html 问题 awk命令 备注 对请求IP统计分组排序? 显示列 ...
- HAWQ取代传统数仓实践(十二)——维度表技术之分段维度
一.分段维度简介 在客户维度中,最具有分析价值的属性就是各种分类,这些属性的变化范围比较大.对某个个体客户来说,可能的分类属性包括:性别.年龄.民族.职业.收入和状态,例如,新客户.活跃客户.不活跃客 ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
随机推荐
- React框架的基本运行原理与组件定义方式
React框架的基本运行原理 React的本质是内部维护了一套虚拟DOM树,这个虚拟DOM树就是一棵js对象树,它和真实DOM树是一致的,一一对应的. 当某一个组件的state发生修改时,就会生成一个 ...
- YbtOJ 「动态规划」第5章 状压DP
犹豫了许久还是决定试试始终学不会的状压 dp.(上一次学这东西可能还是两年前的网课,显然当时在摸鱼一句都没听/kk 果然还是太菜. 例题1.种植方案 设 \(f_{i,j}\) 表示第 \(i\) 行 ...
- P4022 [CTSC2012]熟悉的文章 题解
题目链接 简要题意 给定 \(m\) 个模板串和 \(n\) 个匹配串,如果一个字符串是一个模板串的子串且长度不小于 \(L\) 则称其为"熟悉的",对于每个匹配串,求一个最大的 ...
- IPv4:根据CIDR显示地址范围
最近遇到一个很有意思的点,于是就记录下来. CIDR一般是由IP地址和子网掩码组成,即 IP地址/子网掩码 格式. 子网掩码表示前面地址中的前多少位,为网络位,后面部分代表主机部分.例如:192.16 ...
- redis 怎么样查看key的大小,多大的key才算大key?
查看key大小的命令 # 格式memory usage [key-name]# 例如:我要查 yino_hash_key 这个key的大小,就在命令行中输入 memory usage yino_has ...
- win10安装WSL2
什么是WSL2 首先我们理解一下什么是WSL Windows Subsystem for Linux(简称WSL)是一个在Windows 10\11上能够运行原生Linux二进制可执行文件(ELF格式 ...
- GitHub 官方开源的字体集「GitHub 热点速览」
前几天 GitHub 官方一口气开源了 5 款字体,各有特色,彼此兼容,重要的是代码友好.这不,一开源就获得了 4.5k+ 的 star. 本周除了这个热点之外,当属 OpenAI 又有新动态了,你可 ...
- Mariadb 10.4 root 用户无法使用无密码登录的原因
Mariadb现在是网站建设中使用的主流数据库之一,当前它很多个版本:10.1.10.2.10.3.10.4. 其中10.1和10.2在程序中使用root用户登录连接数据库都没有什么问题. 如果是10 ...
- 领域驱动设计之银行转账:Wow框架实战
银行账户转账案例 银行账户转账案例是一个经典的领域驱动设计(DDD)应用场景.接下来我们通过一个简单的银行账户转账案例,来了解如何使用 Wow 进行领域驱动设计以及服务开发. 银行转账流程 准备转账( ...
- 低代码平台解密:探秘MQTT协议的应用之道
前言 低代码平台作为当今快速发展的技术之一,为开发人员提供了更高效.更简便的工具和方法,以快速构建和部署应用程序.而MQTT协议作为物联网领域的重要通信协议,在低代码平台上的应用也日益受到关注,今天小 ...