一文带你了解两种Transformer文字识别方法
摘要:受Transformer模型的启发,目前一些学者将该结构应用到文本行识别中,以替代RNN,取得了良好的效果,如在HGA-STR和 SRN。
当前的文本行识别器为拥有更强的序列语义能力,模型多采用CNN + RNN的结构,如目前使用十分广泛的两个识别器CRNN和Aster,这些模型取得了非常好的效果。然而由于RNN只能采用串行计算,在目前大量采用并行计算设备的前提下,RNN面临着明显的速度瓶颈。若弃用RNN只使用CNN,性能往往不尽如人意。在NLP领域,Ashish Vaswan[1]等人提出的Transformer模型在语言理解相关任务上十分成功,并优于CNN和RNN效果,展现出Transformer强大的序列建模能力。Transformer模型基于Attention实现,该操作可并行实现,因此该模型具有良好的并行性。
受Transformer模型的启发,目前一些学者将该结构应用到文本行识别中,以替代RNN,取得了良好的效果,如在HGA-STR[2]和 SRN[3]。下面对两种方法进行介绍,总体上,HGA-STR更接近原有的Transformer的结构,使用了和Transformer类似的解码结构,而SRN则是使用了Transformer unit进行特征提取,并采用该文作者提出的并行解码器,整个模型拥有更好的可并行性。为较好理解下面两篇文章,请参阅相关资料以了解Transformer的原理。
HGA-STR 简介
对于不规则文本,文本分布在二维空间上,将其转换成一维有一定难度,同时基于RNN的编码解码器无法做到并行,本文直接将2D的特征输入到attention-based 1D序列解码器,解码器采用Transformer中的解码器同样的结构。同时,在编码器部分,提取一个全局语义向量,与解码器的输入embedding向量合并,为解码器提供全局语义信息。该模型结构如图1所示。
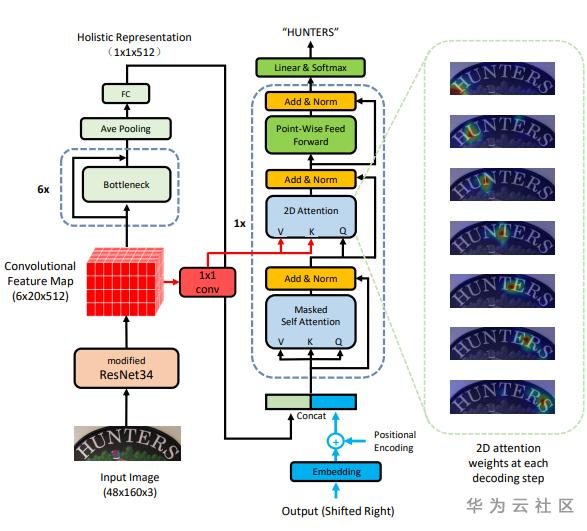
图 1. 模型的基本结构
编码器介绍:该模型使用CNN进行特征提取,并保持输出的特征为二维。并使用池化操作得到一维向量,作为全局信息表示。
解码器介绍:编码器主要组件有:masked self-attention用来建模预测结果的依赖性;2D-attention用来连接编码器和解码器;以及一个前馈层。具体实现和Transformer文中的结构相同。同时为了更好的性能作者使用两个方向进行解码,结构如图2所示。
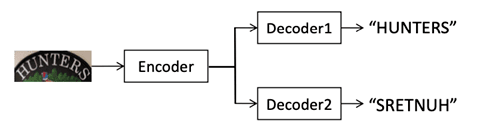
图 2.该方法使用双向解码器
该方法在多个英文基准数据集取得了较好的结果,具体结果可参见论文。在速度上作者和两种基于attention的方法进行对比有一定的优势,如表1所示。
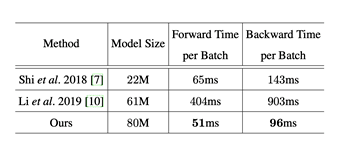
表 1. 速度对比
在作者进行的对比试验中,一个比较有意思的现象是,在编码器里面添加Self-attention模块并不能提升模型性能,在解码器中添加才会对结果有提升,如表2所示。这表明原本的Transformer结构直接应用到文字识别任务上是不可行的,需要做相应的调整。
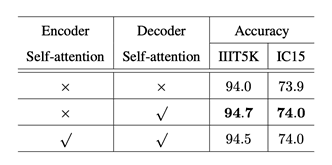
表 2. Self-attention性能对比
SRN简介
与上一方法不同的是,SRN采用完全不同的解码方式,并引入全局语义推理模块。就获取语义信息的方式而言,主流的Attention-based方法基于RNN来实现,是一种采用单向串行方式进行建模的方法,如图 3.(a)所示。这种方式有明显的不足:
1)仅仅感知了历史时刻的语义信息,而无法获取未来时刻的语义信息;
2)如果较早时刻解码出的错误字符,会为余下时刻的解码传递错误的语义信息,导致误差积累效应;
3)串行的解码模式是相对低效的,特别是在模型预测的环节。

图 3. 两种不同的传递语义信息的方法
如图4所示,SRN由四部分组成:基础网络Backbone、并行的视觉特诊提取模块(PVAM)、全局语义推理模块(GSRM) 和视觉语义融合的解码器(VSFD)。给定一张输入的文本图像,基于ResNet50 + Transformer unit的Backbone从中提取出视觉2D feature map V;之后PVAM会针对每个目标字符获取其相应的视觉特征G;GSRM会基于视觉特征G获取全局语义信息,并转化为每个目标字符的语义特征S;最后VSFD融合对齐的视觉特征和语义特征,预测出相应字符。在训练阶段和推断阶段,每个序列中各个字符之间是并行。
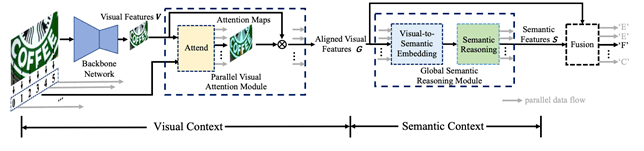
图 4. 方法的总体结构图
PVAM模块介绍:在Backbone输出了2D的视觉特征图之后,PVAM会针对文本行中的每个字符,计算出相应attention map, 通过将其与feature map 按像素加权求和,可得到每个目标字符对应的的视觉特征。另外,PVAM也用字符的阅读顺序取代上一时刻隐变量来引导计算当前时刻的attention map,实现了并行提取视觉特征的目的。
GSRM模块介绍:GSRM会基于全局语义信息进行推理。具体过程为,首先将视觉过程转换成语义特征,使用交叉熵损失进行监督,并对其概率分布取argmax得到初始的分类结果,同时通过分类结果获取每个字符的embedding向量,通过多层Transformer unit后,得到经语义推理模块修正的预测结果,同样使用交叉熵损失进行监督。
VSFD 模块介绍:对PVAM输出的对齐的视觉特征和GSRM输出的全局语义特征进行融合,最后基于融合后的特征进行预测输出。
该方法在多个英文基准数据集上取得了SOTA的结果。对于中文长文本的识别,SRN相对于其他识别方法也有明显优势,如表3所示。
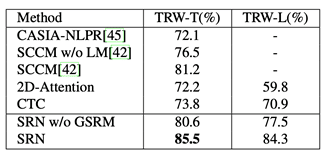
表 3.中文数据集结果(TRW-L为长文本)
速度上,得益于整个模型的并行设计,SRN拥有较小的推理时延,如表4所示。
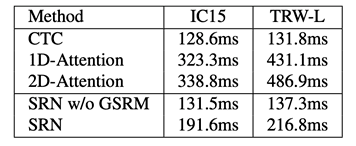
表 4.推理速度介绍
Reference
[1] https://arxiv.org/pdf/1706.03762.pdf
[2] https://arxiv.org/abs/1904.01375
[3] https://arxiv.org/pdf/2003.12294.pdf
本文分享自华为云社区《技术综述六:文字识别中基于Transformer识别方法汇总简介》,原文作者:谷雨润一麦 。
一文带你了解两种Transformer文字识别方法的更多相关文章
- Tomcat下载安装并部署到IDEA(附带idea两种热部署设置方法)
目录 Tomcat下载教程 Tomcat安装教程 Tomcat热部署到IDEA idea两种热部署设置方法 使用Idea的时候,修改了代码,需要反复的重启Tomcat,查看效果,是不是贼烦?还记得刚上 ...
- 接口测试中GET和POST两种基本HTTP请求方法的区别
面试时,可以回答(一般答前4条就行): GET参数通过url传递,POST放在request body中 GET请求在url中传递的参数是有长度限制的,而POST没有 GET比POST更不安全,因为参 ...
- C#两种创建快捷方式的方法
C#两种创建快捷方式的方法http://www.cnblogs.com/linmilove/archive/2009/06/10/1500989.html
- HTTP/HTTPS GET&POST两种方式的实现方法
关于GET及POST方式的区别请参照前面文章:http://www.cnblogs.com/hunterCecil/p/5698604.html http://www.cnblogs.com/hunt ...
- iOS - UITableView中有两种重用Cell的方法
UITableView中有两种重用Cell的方法: - (id)dequeueReusableCellWithIdentifier:(NSString *)identifier; - (id)dequ ...
- 两种ps切图方法(图层/切片)
两种Ps切图方法 一. 基础操作: a) Ctrl++ 放大图片,ctrl - -缩小图片 b) 按住空格键space+,点击鼠标左键,拖动图片. c) 修改单位,点击编辑 ...
- Eclipse中SVN的安装步骤(两种)和使用方法
Eclipse中SVN的安装步骤(两种)和使用方法 一.给Eclipse安装SVN,最常见的有两种方式:手动方式和使用安装向导方式.具体步骤如下: 方式一:手动安装 1.下载最新的Eclipse,我的 ...
- TextView两种显示link的方法
TextView两种显示link的方法 一.简介 也是TextView显示文本控件两种方法 也是显示丰富的文本 二.方法 TextView两种显示link的方法 1)通过TextView里面的类ht ...
- Python_两种导入模块的方法异同
Python中有两种导入模块的方法 1:import module 2:from module import * 使用from module import *方法可以导入独立的项,也可以用from m ...
- SSH简介及两种远程登录的方法
出处 https://blog.csdn.net/li528405176/article/details/82810342 目录 SSH的安全机制 SSH的安装 启动服务器的SSH服务 SSH两种级别 ...
随机推荐
- Go语言代码断行规则详解
本文深入探讨了Go语言中代码断行的各个方面,从基础概念到实际应用实践. 关注[TechLeadCloud],分享互联网架构.云服务技术的全维度知识.作者拥有10+年互联网服务架构.AI产品研发经验.团 ...
- MAC版本vmware无法识别虚拟机网卡适配器
一.问题 莫名其妙的突然mac上的vmware无法识别网络适配器了 二.解决过程 1.重装vmware-无效 2.降级安装vmware-无效 3.安装pd虚拟机,并使用sudo命令启动-偶尔有效 4. ...
- Java面向对象(高级)
1.类变量 类变量是被类的所有实例共享的. 类变量具体放的位置在哪?在内存中的那个区域,这和jdk的版本是有关的 静态变量在类加载的时候就生成了,即使没有创建类实例也能访问,当然通过实例来实现 类变量 ...
- 将.View.dll文件反编译出来的*Views*.cs文件转换成.cshtml
先使用反编译工具将.View.dll文件反编译放入文件夹,然后将文件夹整体复制进\src\viewcs2cshtml\viewcs2cshtml\bin\Debug\net6.0\viewcs 复制完 ...
- 为什么idea建议使用“+”拼接字符串
前言 各位小伙伴在字符串拼接时应该都见过下面这种提示: 内容翻译:报告StringBuffer.StringBuilder或StringJoiner的任何用法,这些用法可以用单个java.lang.S ...
- 聊聊如何在Java应用中发送短信
很多业务场景里,我们都需要发送短信,比如登陆验证码.告警.营销通知.节日祝福等等. 这篇文章,我们聊聊 Java 应用中如何优雅的发送短信. 1 客户端/服务端两种模式 Java 应用中发送短信通常需 ...
- WebSocket魔法师:打造实时应用的无限可能
1.背景 在开发一些前端页面的时候,总是能接收到这样的需求:如何保持页面并实现自动更新数据呢?以往的常规做法,是前端使用定时轮询后端接口,获取响应后重新渲染前端页面,这种做法虽然能达到类似的效果,但是 ...
- easy ui 按钮图标样式合集
data-options="iconCls:'icon-search'" 可替换以下值 icon-add icon-print icon-mini-add icon-cvs ico ...
- LabVIEW用布尔控件实现上升沿和下降沿触发
我们利用了第三方布尔控件来记录摇杆的高低电平状态,并和摇杆布尔控件组成布尔数组,转换成十进制数进行判断上升沿和下降. 上升沿触发.例如一开始第三方布尔控件为T,夹紧松开布尔控件为F,然后我这时把摇杆控 ...
- c#实现一个简单的管理系统报错System.Data.SqlClient.SqlException”类型的未经处理的异常在 System.Data.dll 中发生【已解决】
很简单就是把连接数据库语句改成(local)或者"127.0.0.1" 如下 public SqlConnection connect() { string str = @&quo ...