论文《Attention is all you need》阅读笔记
Attention is all you need
Transformer模型
Model Architecture
Transformer结构上和传统的翻译模型相同,拥有encoder-decoder structure
encoder:将一系列输入的符号表示\((x_1...,x_n)\)映射到连续表示\(z=(z_1....,z_n)\)
decoder:将\(z\)解码出系列输出序列\((y_i,....,y_n)\)
模型结构图:
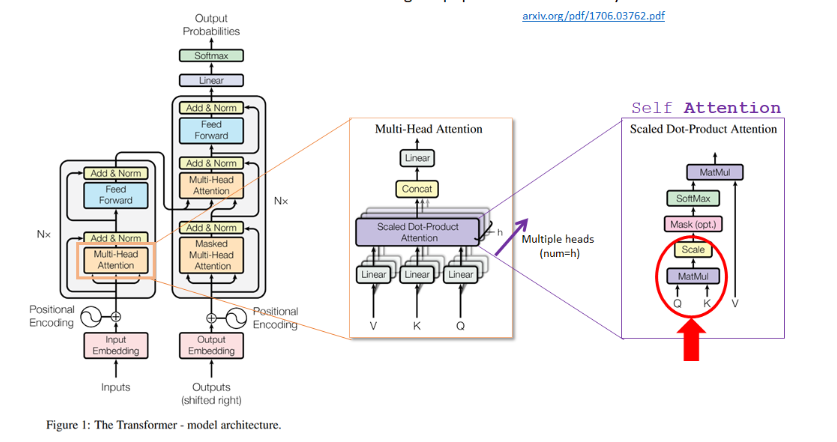
上述结构图中:左侧为encoder结构,右侧为decoder结构
1、encoder结构:整体上encoder由两部分构成:1、Multi-head Attention;2、Feed Forwarded构成。在每一部分里面都是通过残差进行连接。(论文中对此的描述为:\(LayerNorm(x+Sublayer(x))\)其中\(x+Sublayer(x)\)就是一个残差连接的操作,而\(LayerNorm\)就是一个Norm所进行的一个操作。)
2、decoder结构整体与encoder相似,只是多了一个Masker Multi-Head Attention结构,这部分结构起到的作用为:因为如果是做序列预测(时间序列、翻译等)一般来说都是不去借助未来的数据,也就是说保证我们在预测\(i\)时候只考虑了\(i\)之前的信息。
This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
Attention模型
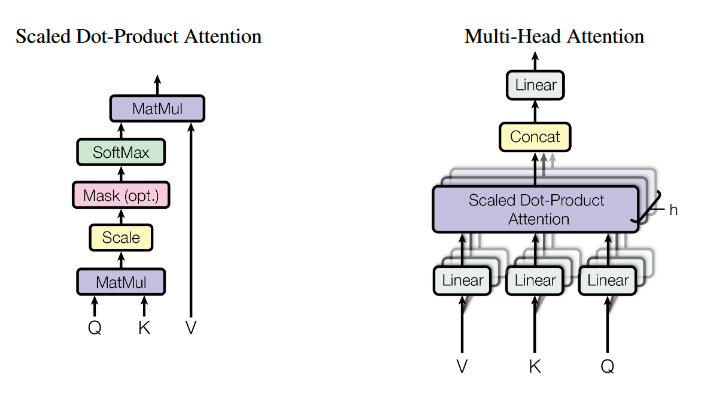
在Transformer函数中设计的注意模型:
1、Scaled Dot-Product Attention
\]
对于上层结构通过翻译的角度进行理解:

下述步骤都是针对关键字
Thinking
第一步:imput到values为
第二步:计算Score:通过计算Q和K的点积;通过分数来确定在对某个位置的单词进行编码时,对输入句子其他部分的关注程度。
第三步:从Divide到sofmax就是上述Attention公式里面\(softmax\)部分,后续然后乘V就是一层Attention
第四步:对加权值向量求和,这会在该位置(第一个单词)产生自注意力层的输出
QKV理解视频
https://www.youtube.com/watch?v=OyFJWRnt_AY
补充内容
1、encoder-decoder
2、norm
Training state-of-the-art, deep neural networks is computationally expensive. One way to reduce the training time is to normalize the activities of the neurons.
正则化:\(x=\frac{x-x_{min}}{x_{max}- x_{min}}\)将数据都转化到\([0,1]\);以及标准化:\(x=\frac{x- \mu}{\sigma}\)将数据都转化为0均值同方差。在深度学习中常见4类标准化操作:
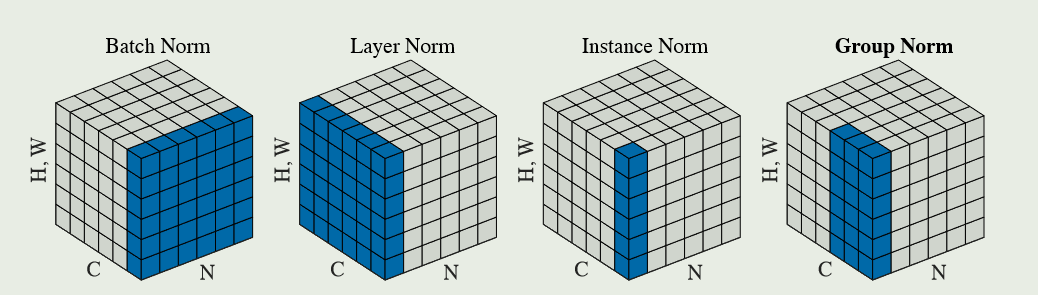
1、Bath-Norm;2、Layer-Norm;3、Instance-Norm;4、Group-Norm。这4类标准化化唯一区别就在对样本\(\mu,\sigma\)的计算区别。
定义如下计算公式:
\[\mu_i= \frac{1}{m}\sum_{k\in S_i}x_k
\]\[\sigma_i= \sqrt{\frac{1}{m}\sum_{k\in S_i}(x_k- \mu_i)^2+\epsilon}
\]4类标准化区别就在于对于参数\(S_i\)的定义!!!
如:对一组图片定义如下变量:\((N,C,H,W)\)分别代表:batch、channel、height、width
Bath-norm:\(S_i=\{k_C=i_C\}\)
Layer-norm:\(S_i=\{k_C=i_N\}\)
Instance-norm:\(S_i=\{k_C=i_C,K_N=i_N\}\)
Group-norm:\(S_i=\{k_N=i_N, \lfloor \frac{k_C}{C/G} \rfloor=\lfloor \frac{i_C}{C/G} \rfloor\}\)
\(G\)代表组的数量,\(C/G\)每个组的通道数量
对于Layer-norm、batch-norm、Instance-norm、Group-norm理解直观的用下面一组图片了解:
2.1 Batch-norm详细原理
参考:https://proceedings.mlr.press/v37/ioffe15.html
在原始论文中主要是将Batch-norm运用在图算法(CNN等)中,作者得到结论:通过添加Batch-norm可以加快模型的训练速度,模型效果较以前算法效果更加好
原理:对每一个特征独立的进行归一化
we will normalize each scalar feature independently, by making it have zero mean and unit variance.
对于每一层\(d\)维输入\(x=(x^{(1)},...,x^{(d)})\)通过:
\]
问题一:如果只是简单的对每一层输入进行简单的正则化将会改变该层所表示的内容(原文中提到:对于通过sigmoid函数处理的输入进行正则化将会导致原本应该的非线性转化为线性)
Note that simply normalizing each input of a layer may change what the layer can represent. For instance, normalizing the inputs of a sigmoid would constrain them to the linear regime of the nonlinearity.
通过构建\(y^{(k)}=\gamma^{(k)}\widehat{x}^{(k)}+\beta^{(k)}\)其中\(\gamma^{(k)}=\sqrt{Var[x^{(k)}]}、\beta^{(k)}=E[x^{(k)}]\)
问题二:在训练过程中运用的是全部的数据集,因此想要做到随机优化是不可能的,因为通过小批量随机梯度训练,在每一次小梯度过程中都会产生均值以及方差。(Batch Normalizing Transform)
2.2 Layer-norm详细原理
参考:http://arxiv.org/abs/1607.06450
针对Batch-norm的部分缺点以及其在序列数据上的表现较差,提出通过使用Layer-norm在序列数据(时间序列、文本数据)上进行使用
原理:通过从一个训练样例中计算用于归一化的所有神经元输入之和的均值和方差(也就是说直接对某个神经元的所有的输入进行标准化)
we transpose batch normalization into layer normalization by computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case
\sigma^l=\sqrt{\frac{1}{H}\sum_{i=1}^{H}(a_i^l- \mu^l)^2}
\]
其中\(H\)代表隐藏层的数量、\(a^l\)代表一层神经元的输入、\(\mu和\sigma\)则分别代表该层神经元的均值以及方差。
2.3 Group-norm
参考
1、http://arxiv.org/abs/1706.03762
论文《Attention is all you need》阅读笔记的更多相关文章
- 《MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment》论文阅读笔记
出处:2018 AAAI SourceCode:https://github.com/salu133445/musegan abstract: (写得不错 值得借鉴)重点阐述了生成音乐和生成图片,视频 ...
- (转)Introductory guide to Generative Adversarial Networks (GANs) and their promise!
Introductory guide to Generative Adversarial Networks (GANs) and their promise! Introduction Neural ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 生成对抗网络(Generative Adversarial Networks, GAN)
生成对抗网络(Generative Adversarial Networks, GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的学习方法之一. GAN 主要包括了两个部分,即 ...
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
- 论文笔记之:Semi-Supervised Learning with Generative Adversarial Networks
Semi-Supervised Learning with Generative Adversarial Networks 引言:本文将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类 ...
- 《Self-Attention Generative Adversarial Networks》里的注意力计算
前天看了 criss-cross 里的注意力模型 仔细理解了 在: https://www.cnblogs.com/yjphhw/p/10750797.html 今天又看了一个注意力模型 < ...
- Paper Reading: Perceptual Generative Adversarial Networks for Small Object Detection
Perceptual Generative Adversarial Networks for Small Object Detection 2017-07-11 19:47:46 CVPR 20 ...
- SalGAN: Visual saliency prediction with generative adversarial networks
SalGAN: Visual saliency prediction with generative adversarial networks 2017-03-17 摘要:本文引入了对抗网络的对抗训练 ...
- Generative Adversarial Networks,gan论文的畅想
前天看完Generative Adversarial Networks的论文,不知道有什么用处,总想着机器生成的数据会有机器的局限性,所以百度看了一些别人 的看法和观点,可能我是机器学习小白吧,看完之 ...
随机推荐
- 【六】gym搭建自己环境升级版设计,动态障碍------强化学习
相关文章: [一]gym环境安装以及安装遇到的错误解决 [二]gym初次入门一学就会-简明教程 [三]gym简单画图 [四]gym搭建自己的环境,全网最详细版本,3分钟你就学会了! [五]gym搭建自 ...
- C/C++ 实现获取硬盘序列号
获取硬盘的序列号.型号和固件版本号,此类功能通常用于做硬盘绑定或硬件验证操作,通过使用Windows API的DeviceIoControl函数与物理硬盘驱动程序进行通信,发送ATA命令来获取硬盘的信 ...
- 使用C++实现Range序列生成器
在C++编程中,经常需要迭代一系列数字或其他可迭代对象.通常,这需要编写复杂的循环结构,但有一种精妙的方法可以使这一过程变得更加简单和可读.如果你使用过Python语言那么一定对Range语句非常的数 ...
- 用arr.filter数组去重
let res = arr.filter((item,index,arr)=>{ //返回找到的下标,等于 下标 return arr.indexOf(item) === index; }) c ...
- iOS测试包的安装方法
iOS测试包根据要安装的机器类型可以分为2种: .app模拟器测试包 .ipa真机测试包 .app模拟器测试包的安装方式 方式一:Xcode生成安装包 1.Xcode运行项目,生成app包 2.将AP ...
- .net 工具箱不可用/怎样初始化vs环境 解决方案
在开始菜单里面执行的.开始菜单->Microsoft Visual Studio 2005->Visual Studio Tools->Visual Studio 2005 命令提示 ...
- 【奶奶看了都会】ComfyUI+SVD制作AI视频教程,附效果演示
AI一天,人间一年 大家好啊,我是小卷,最近AI绘画又发展出一些新玩意了,小卷因为工作的关系有一个月没关注AI的发展了,都有点跟不上版本节奏了... 1.comfyui的使用效果 今天给大家介绍下AI ...
- 使用OBS Studio软件进行桌面录屏
操作系统 :Windows10_x64 OBS Studio是开源免费的录屏和直播软件,支持Windows.macOS及Linux操作系统. 这里记录下桌面录屏和桌面区域录屏的使用,也方便我后续查阅( ...
- RabbitMQ 使用细节 → 优先级队列与ACK超时
开心一刻 今天坐在太阳下刷着手机 老妈走过来问我:这么好的天气,怎么没出去玩 我:我要是有钱,你都看不见我的影子 老妈:你就不知道带个碗,别要边玩? 我:...... 优先级队列 说到队列,相信大家一 ...
- 一键跳转组件所在的文件与具体行数,提升排查效率,分享几个 React Developer Tools 使用小技巧
壹 ❀ 引 React Developer Tools对于很多开发同学可能就是一个检查组件props传递对不对的工具,但事实上它的功能比我们想象的强大.比如我们日常排查问题,常常会遇到想知道某个页面某 ...