用ELK分析每天4亿多条腾讯云MySQL审计日志(2)--EQL
上一篇介绍了用ELK分析4亿多条审计日志过程,现在介绍如何用Python3分析ES的程序
需要分析的核心库审计数据:
1,950多张表,几十个账号,
2,5种操作类型(select,update,insert,delete,replace),14个实例(1主13从库)
分析说明:
select汇总: 必须包含from关键字:排除INSERT INTO 表 SELECT '609818','1' 这样情况
insert汇总: 必须有into关键字: 排除select中有insert关键字
update汇总: 不包含for 关键字: 排查 for update 的select查询
delete汇总: 不包含into 关键字: 排除insert等内容里包含delete的数据情况
replace汇总: 必须有into 关键字: 排除select查询中有replace函数
分析方法:
为保证把以上数据都能分析出来, 将950多张表,存放到数据表中,循环950多次表,每个表循环5次类型:
sql="select id,name,ea_time from tab order by id desc --查询全部表
dml={'select','update','insert','delete','replace'} --每个表循环5次类型
后来研发发现,分析程序表ol_list统计,但"库名.表",如line.ol_list,不会统计出来。后来修改EQL解决,具体代码如下:
下列是“”select“查询EQL的代码:


if op.find('select')>=0: # select,包含from
body ={"query":{
"bool":{ "must":[{
"match":{"Sql":'{op}'.format(op=op) }},{
"match":{"Sql": 'from'}}],
"should": [{
"term": {"Sql": '{name}'.format(name=tabname)}}, {
"term": {"Sql": 'online.{name}'.format(name=tabname)}}],
"minimum_should_match": 1,
"filter":{
"range":{
"Timestamp.keyword":{
"lte": "{date}".format(date=end_time),
"gte": "{begindate}".format(begindate=begin_time),
}
} }}},
"size":0, "aggs":{ "aggr_mame":{
"terms":{
"field":"User.keyword",
"size":2000
},
"aggs":{
"aggr_der":{
"terms":{
"field":"PolicyName.keyword"
},
"aggs":{
"top_tag_hits":{
"top_hits":{
"size":1
}
} }}}}}
}
说明:
1,使用:"minimum_should_match": 1, ,这个是兼容: "表名","库名.表名“
5种类型的全部EQL:
if op.find('select')>=0: # select,包含from
body ={"query":{
"bool":{ "must":[{
"match":{"Sql":'{op}'.format(op=op) }},{
"match":{"Sql": 'from'}}],
"should": [{
"term": {"Sql": '{name}'.format(name=tabname)}}, {
"term": {"Sql": 'online.{name}'.format(name=tabname)}}],
"minimum_should_match": 1,
"filter":{
"range":{
"Timestamp.keyword":{
"lte": "{date}".format(date=end_time),
"gte": "{begindate}".format(begindate=begin_time),
}
} }}},
"size":0, "aggs":{ "aggr_mame":{
"terms":{
"field":"User.keyword",
"size":2000
},
"aggs":{
"aggr_der":{
"terms":{
"field":"PolicyName.keyword"
},
"aggs":{
"top_tag_hits":{
"top_hits":{
"size":1
}
} }}}}}
}
elif op.find('update')>=0: # update 不能有for关键字
body = {"query": {
"bool": {"must": [{
"match": {"Sql": '{op}'.format(op=op)}},{
"match": {"PolicyName.keyword": 'd8t'}}],
"must_not": [{"match": {"Sql": "for"}}],
"should": [{
"term": {"Sql": '{name}'.format(name=tabname)}}, {
"term": {"Sql": 'online.{name}'.format(name=tabname)}}],
"minimum_should_match": 1,
"filter": {
"range": {
"Timestamp.keyword": {
"lte": "{date}".format(date=end_time),
"gte": "{begindate}".format(begindate=begin_time),
}
}}}},
"size": 0, "aggs": {"aggr_mame": {
"terms": {
"field": "User.keyword",
"size": 2000
},
"aggs": {
"aggr_der": {
"terms": {
"field": "PolicyName.keyword"
},
"aggs": {
"top_tag_hits": {
"top_hits": {
"size": 1
}
}}}}}}
}
elif op.find('replace') >= 0: # replace 必须有into关键字
body = {"query": {
"bool": {"must": [{
"match": {"Sql": '{op}'.format(op=op)}}, {
"match": {"PolicyName.keyword": 'd8t'}},{
"match": {"Sql": 'into'}}],
"should": [{
"term": {"Sql": '{name}'.format(name=tabname)}}, {
"term": {"Sql": 'online.{name}'.format(name=tabname)}}],
"minimum_should_match": 1,
"filter": {
"range": {
"Timestamp.keyword": {
"lte": "{date}".format(date=end_time),
"gte": "{begindate}".format(begindate=begin_time),
}
}}}},
"size": 0, "aggs": {"aggr_mame": {
"terms": {
"field": "User.keyword",
"size": 2000
},
"aggs": {
"aggr_der": {
"terms": {
"field": "PolicyName.keyword"
},
"aggs": {
"top_tag_hits": {
"top_hits": {
"size": 1
}
}}}}}}
}
elif op.find('insert') >= 0: # insert 必须有into关键字
body = {"query": {
"bool": {"must": [{
"match": {"Sql": '{op}'.format(op=op)}}, {
"match": {"PolicyName.keyword": 'd8t'}},{
"match": {"Sql": 'into'}}],
"should": [{
"term": {"Sql": '{name}'.format(name=tabname)}}, {
"term": {"Sql": 'online.{name}'.format(name=tabname)}}],
"minimum_should_match":1,
"filter": {
"range": {
"Timestamp.keyword": {
"lte": "{date}".format(date=end_time),
"gte": "{begindate}".format(begindate=begin_time),
}
}}}},
"size": 0, "aggs": {"aggr_mame": {
"terms": {
"field": "User.keyword",
"size": 2000
},
"aggs": {
"aggr_der": {
"terms": {
"field": "PolicyName.keyword"
},
"aggs": {
"top_tag_hits": {
"top_hits": {
"size": 1
}
}}}}}}
}
else: # delete 不能有into关键字
body = {"query": {
"bool": {"must": [{
"match": {"Sql": '{op}'.format(op=op)}},{
"match": {"PolicyName.keyword": 'd8t'}}],
"must_not": [{"match": {"Sql": "into"}}],
"should": [{
"term": {"Sql": '{name}'.format(name=tabname)}}, {
"term": {"Sql": 'online.{name}'.format(name=tabname)}}],
"minimum_should_match": 1,
"filter": {
"range": {
"Timestamp.keyword": {
"lte": "{date}".format(date=end_time),
"gte": "{begindate}".format(begindate=begin_time),
}
}}}},
"size": 0, "aggs": {"aggr_mame": {
"terms": {
"field": "User.keyword",
"size": 2000
},
"aggs": {
"aggr_der": {
"terms": {
"field": "PolicyName.keyword"
},
"aggs": {
"top_tag_hits": {
"top_hits": {
"size": 1
}
}}}}}}
}
写入统计数据Py:
doc = res["aggregations"]["aggr_mame"]['buckets']
cn = conn()
cur = cn.cursor()
if len(doc):
for item in doc:
user=item['key'] # 账号
total=str(item['doc_count']) # 该账号在全部实例下的调用次数
if len(item["aggr_der"]["buckets"]):
for bucket in item["aggr_der"]["buckets"]:
server=bucket['key'] # 服务器实例
s_total =str(bucket['doc_count']) # 该服务器实例下的调用次数
sql=bucket["top_tag_hits"]["hits"]["hits"][0]["_source"]["Sql"] # 样例Sql
sql=emoji.demojize(transferContent(sql)) #转义并去掉表情符号
tsql="replace into ea_tj(tab,username,op,num,server,sqltext,dt) "\
" values ('{0}','{1}','{2}','{3}','{4}','{5}','{6}')".format(tabname,user,op,s_total,server,sql,dt)
cur.execute(tsql)
cn.commit()
存放分析结果表:
CREATE TABLE `ea_tj` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`tab` varchar(200) NOT NULL COMMENT '表名',
`username` varchar(200) NOT NULL COMMENT '账号',
`op` varchar(50) DEFAULT NULL COMMENT '操作类型',
`num` bigint(11) NOT NULL COMMENT '次数',
`server` varchar(200) NOT NULL COMMENT '实例策略名',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`sqltext` text COMMENT '样例SQL',
`dt` date DEFAULT NULL COMMENT '线上SQL执行日期',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `un` (`tab`,`username`,`op`,`server`,`dt`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4
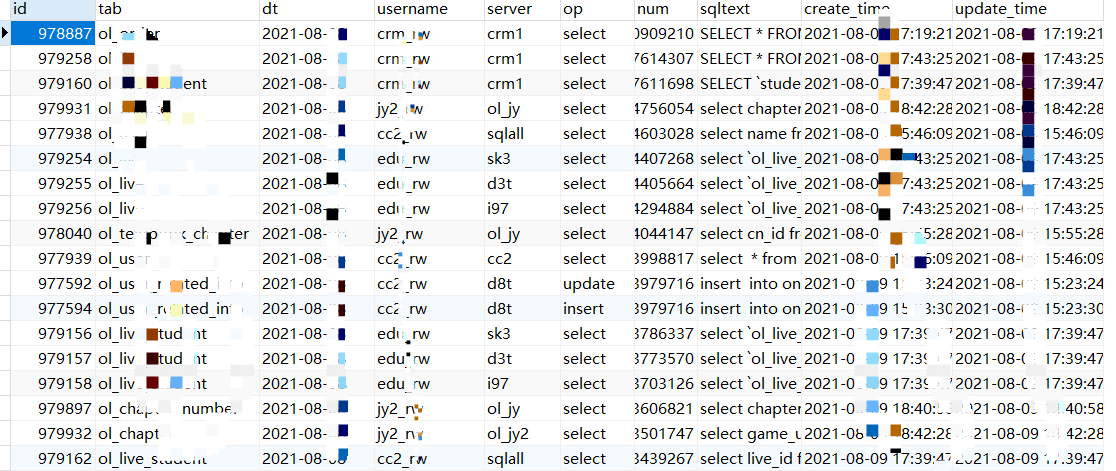
具体汇总数据:
1,每天13个实例,表,账号,操作之间关系汇总(用来Online表拆分)
2,每天13个数据库实例账号的连接IP汇总(用来迁移VPC)
3,统计调用总次数 (用来分析调用次数异常)
汇总1的结果数据:
用ELK分析每天4亿多条腾讯云MySQL审计日志(2)--EQL的更多相关文章
- jquery的$.extend和$.fn.extend作用及区别/用span实现进度条/腾讯云IIS端口号修改
jQuery为开发插件提拱了两个方法,分别是: jQuery.fn.extend(); jQuery.extend(); 虽然 javascript 没有明确的类的概念,但是用类来理解它,会更方便. ...
- [日志分析]Graylog2采集mysql慢日志
之前聊了一下graylog如何采集nginx日志,为此我介绍了两种采集方法(主动和被动),让大家对graylog日志采集有了一个大致的了解. 从日志收集这个角度,graylog提供了多样性和灵活性,大 ...
- 使用Docker快速部署ELK分析Nginx日志实践(二)
Kibana汉化使用中文界面实践 一.背景 笔者在上一篇文章使用Docker快速部署ELK分析Nginx日志实践当中有提到如何快速搭建ELK分析Nginx日志,但是这只是第一步,后面还有很多仪表盘需要 ...
- 4:ELK分析tomcat日志
五.ELK分析tomcat日志 1.配置FIlebeat搜集tomcat日志 2.配置Logstash从filebeat输入tomcat日志 3.查看索引 4.创建索引
- 使用Docker快速部署ELK分析Nginx日志实践
原文:使用Docker快速部署ELK分析Nginx日志实践 一.背景 笔者所在项目组的项目由多个子项目所组成,每一个子项目都存在一定的日志,有时候想排查一些问题,需要到各个地方去查看,极为不方便,此前 ...
- elk是指logstash,elasticsearch,kibana三件套,这三件套可以组成日志分析和监控工具
Logstash是一个完全开源的工具,他可以对你的日志进行收集.分析,并将其存储供以后使用(如,搜索),您可以使用它.说到搜索,logstash带有一个web界面,搜索和展示所有日志.kibana 也 ...
- Python脚本收集腾讯云CDN日志,并入ELK日志分析
负责搭建公司日志分析,一直想把CDN日志也放入到日志分析,前些日志终于达成所愿,现在贴出具体做法: 1.收集日志 腾讯云CDN日志一般一小时刷新一次,也就是说当前只能下载一小时之前的日志数据,但据本人 ...
- ELK 构建 MySQL 慢日志收集平台详解
ELK 介绍 ELK 最早是 Elasticsearch(以下简称ES).Logstash.Kibana 三款开源软件的简称,三款软件后来被同一公司收购,并加入了Xpark.Beats等组件,改名为E ...
- ELK构建MySQL慢日志收集平台详解
上篇文章<中小团队快速构建SQL自动审核系统>我们完成了SQL的自动审核与执行,不仅提高了效率还受到了同事的肯定,心里美滋滋.但关于慢查询的收集及处理也耗费了我们太多的时间和精力,如何在这 ...
- 腾讯云EMR大数据实时OLAP分析案例解析
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾 ...
随机推荐
- Kafka 社区KIP-382中文译文(MirrorMaker2/集群复制/高可用/灾难恢复)
译者:对于Kafka高可用的课题,我想每个公司都有自己的方案及思考,这是一个仁者见仁智者见智的命题,而社区给出了一个较大的特性,即MirrorMaker 2.0,不论是准备做高可用还是单纯的数据备份, ...
- Go-性能测试-benchmark
- [转帖]Nginx内置变量以及日志格式变量参数详解
https://www.cnblogs.com/wajika/p/6426270.html $args #请求中的参数值 $query_string #同 $args $arg_NAME #GET请求 ...
- [转帖]TLS 加速技术:Intel QuickAssist Technology(QAT)解决方案
https://zhuanlan.zhihu.com/p/631184323 3 人赞同了该文章 作者:vivo 互联网服务器团队- Ye Feng 本文介绍了 Intel QAT 技术方案,通过 ...
- [转帖]Oracle迁移到MySQL时数据类型转换问题
https://www.cnblogs.com/yeyuzhuanjia/p/17431979.html 最近在做"去O"(去除Oracle数据库)的相关工作,需要将Oracle表 ...
- [转帖]Linux之bash反弹shell原理浅析
环境 攻击机:kali ip:192.168.25.144 靶 机:centos ip:192.168.25.142 过程 kali 监听本地8888端口 靶机 ...
- [转帖]线上一个隐匿 Bug 的复盘
前言 之前负责的一个项目上线好久了,最近突然爆出一 Bug,最后评估影响范围将 Bug 升级成了故障,只因为影响的数据量有 10000 条左右,对业务方造成了一定的影响. 但因为不涉及到资金损失,Bu ...
- ebpf的简单学习
ebpf的简单学习-万事开头难 前言 bpf 值得是巴克利包过滤器 他的核心思想是在内核态增加一个可编程的虚拟机. 可以在用户态定义很多规则, 然后直接在内核态进行过滤和使用. 他的效率极高. 因为避 ...
- [转帖]如何通过shell脚本对一个文件中的所有数值相加并求和
https://developer.aliyun.com/article/886170?spm=a2c6h.24874632.expert-profile.255.7c46cfe9h5DxWK 1.背 ...
- killall 以及 pkill 等命令
https://zhidao.baidu.com/question/1500084252693125099.html // 通过 killall 命令killall nginx// 通过 pkill ...