python多进程multiprocessing模块的变量传递问题:父进程中的numpy.array对象隐式序列化到子进程后的inplace操作的问题
参考:
https://docs.python.org/zh-cn/3/library/multiprocessing.html
cloudpickle —— Python分布式序列化的专用模块
=================================
python的多线程不能并发执行,因此python的multiprocessing模块是并发执行唯一途径,但是使用multiprocessing创建子进程的时候如何传参往往是导致bug发生一个主要因素,本文主要就是讨论一下这个传参的问题。
注意本文以生成子进程的multiprocessing.Process方式为代表,显式的传参形式为:
multiprocessing.Process(target=None, args=(), kwargs={})
其实很多人认为显式传参的只有args和kwargs两个变量,实际上target目标函数也是一种显式传参。
(注意:本文只以x86平台下Linux做试验)
为什么说target目标函数也是一种显式传参,因为由于python的语言特性target虽然是函数但是其中往往会涉及到对父进程变量的访问,而这个target函数和args还有kwargs由于是在进程间进行传递的,因此其并不是以复制copy的形式实现的,而是以pickle的形式来实现的。args和kwargs往往传递的都是简单的变量,很少是传函数和类对象的形式,但target函数往往会涉及到一些复杂情况,也就是会涉及到不在函数体内的变量,此时就需要注意的是pickle序列化是一种reference形式的序列化,而不是value形式的,也正是因此往往会造成生成的子进程出现bug,这个问题可以参考:
cloudpickle —— Python分布式序列化的专用模块
关于target函数的序列化传递问题我们后面再细说,下面我们先说下隐式的参数传递(隐式的变量传递),因为正是由于显式变量传递和隐式变量传递的问题还更难说明target函数传递设置正确的重要性。
通过python的官方文档可知道,multiprocessing启动子进程时有三种context方式可以选择,在linux系统中我们自然都是默认使用fork方式,而你如果是mac或Windows的话往往就需要使用spawn方式,这三种方式有什么区别其实并不需要了解,只需要知道在什么系统平台优先使用哪个context即可,如果你是Linux用户那么直接默认的就可以,不需要再考虑这个context问题了。之所以说这个multiprocessing的context问题是因为python在创建子进程的同时会将父进程中的变量序列化后copy给子进程,一般的变量就可以当做是直接copy了,像一些句柄(如文件的句柄f=open("/tmp/1.txt", "r")中的f就是文件句柄)也会把这个句柄进行序列化后copy,但是一些父进程内的复杂变量往往也会通过pickle序列化的形式拷贝给子进程, 而这个时候就需要注意了(父进程中的变量往往都是内存占比较小的,因此pickle后传给子进程也不太会影响性能的)。

既然子进程创建的时候会pickle的方式copy父进程变量,那么我们也可以通过一些实验来亲测一下:
代码:
import multiprocessing as mp
import numpy as np
import time arr = np.arange(8000000000) def foo():
# print(arr)
# arr += 1111
# arr[0] = 1111
# arr += 1111
# print(arr[:10])
time.sleep(60) if __name__ == '__main__':
ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
p = ctx.Process(target=foo)
p.start()
# p.join()
print(arr[:10])
time.sleep(60)
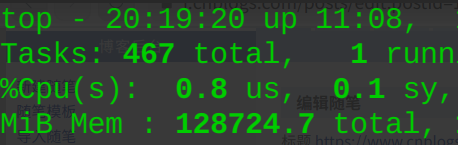

可以看到在创建子进程的时候即使像numpy.array这样大的变量也会被pickle序列化后复制给子进程。(可以看到父进程和子进程都有较大的内存占用,并且几乎一致)
这样自然也就验证了子进程创建后对父进程资源的继承的这个事情了,为此我们又做了下改动性试验:
代码:
import multiprocessing as mp
import numpy as np
import time arr = np.arange(8000000000) def foo():
print(arr)
arr[0] = 1111
# arr += 1111
print(arr[:10])
time.sleep(60) if __name__ == '__main__':
ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
p = ctx.Process(target=foo)
p.start()
# p.join()
print(arr[:10])
time.sleep(60)


----------------------------------------------
但是如果代码是下面的就会出现问题:
import multiprocessing as mp
import numpy as np
import time arr = np.arange(8000000000) def foo():
print(arr)
arr[0] = 1111
arr += 1111
print(arr[:10])
time.sleep(60) if __name__ == '__main__':
ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
p = ctx.Process(target=foo)
p.start()
# p.join()
print(arr[:10])
time.sleep(60)
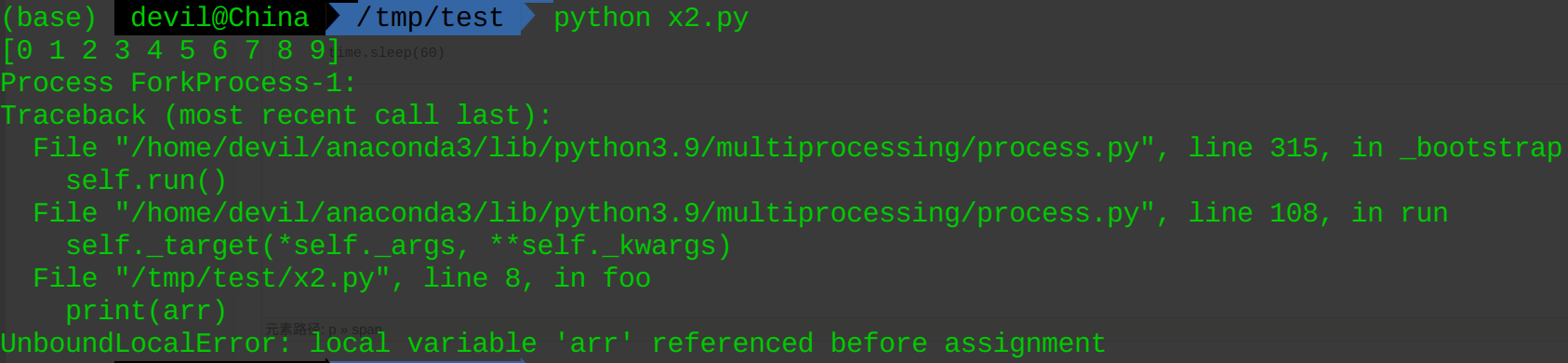
可以看到在子进程中虽然可以隐式的继承父进程的资源,但是像numpy.array这样的对象,通过隐式继承到子进程后是不能进行inplace操作的,否则就会报错,而这个问题是python编译的问题,或者说是语言本身设定的。
也就是说,父进程中的numpy.array对象隐式序列化到子进程后的inplace操作会引起 UnboundLocalError: local variable '****' referenced before assignment 报错。
总结的来说,在python的multiprocessing启动子进程时是不建议使用这种子进程继承父进程资源的方式来将参数传递给子进程的,也就是说传给子进程参数最好的方式还是通过target、args、kwargs这三个变量来传递的,而且由于子进程继承父进程资源这个事情是无法避免的,因此需要尽可能的把启动子进程的时机放在父进程中还没有过多生成资源的时候,比如下面的代码:
import multiprocessing as mp
import numpy as np
import time def foo():
time.sleep(60) if __name__ == '__main__':
ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
p = ctx.Process(target=foo)
p.start()
# p.join() arr = np.arange(8000000000)
print(arr[:10])
time.sleep(60)
上面的代码中子进程启动后并不会继承父进程中的arr变量,也就是说arr变量不会被pickle序列化后copy到子进程中,但是如果代码为下面的则会使子进程继承父进程中的arr资源:
import multiprocessing as mp
import numpy as np
import time def foo():
time.sleep(60) if __name__ == '__main__': arr = np.arange(8000000000) ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
p = ctx.Process(target=foo)
p.start()
# p.join() print(arr[:10])
time.sleep(60)
上面的这个代码就会导致系统内有两个np.arange(8000000000)变量,很大的占用系统的内存资源,由此可见multiprocessing启动子进程的时机是十分有讲究的,在使用multiprocessing启动子进程时需要对父进程中的资源进行pickle序列化后copy继承,如果对该机制没有很好的理解就会造成一系列的潜在bug。
==========================================
回归到最前面提到的关于target函数的序列化传递问题。因为前面的分析可以知道在使用multiprocessing的时候要注意子进程对资源的默认继承,否则轻则导致内存资源浪费,重则导致运行bug。既然我们最好不适用子进程默认继承的方式,那么对于父进程中的一些涉及关系比较复杂的资源(pickle不支持的序列化,见:cloudpickle —— Python分布式序列化的专用模块)在无法使用args和kwargs的时候就可以通过启动子进程时对target进行设置的方式传给子进程(其实我们也可以手动的将复杂对象使用cloudpickle序列化后以字节码的形式通过args和kwargs的方式传递给子进程,只不过使用cloudpickle来包装target会更加的方便)。
下面给出利用target传递参数的代码:
import multiprocessing as mp
import pickle
import numpy as np
import time CONSTANT = 42
def my_function(data: int) -> int:
# return data + CONSTANT
print(data + CONSTANT) if __name__ == '__main__': CONSTANT = 0
ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
p = ctx.Process(target=my_function, args=(43,))
p.start()
# p.join() time.sleep(60)
运行效果:

可以看到子进程启动时将target函数序列化copy到子进程,而此时my_function函数被pickle序列化时对CONSTANT对象进行了reference方式的pickle,同时也将CONSTANT=0进行了pickle后copy,因此在子进程运行时得到的结果为43而不是85。为此我们可以在父进程重新设置CONSTANT=0之前将my_function函数序列化,此时我们可以选择pickle序列化和cloudpickle序列化,给出不同的代码及效果:
使用pickle序列化target函数:
import multiprocessing as mp
import pickle
import numpy as np
import time CONSTANT = 42
def my_function(data: int) -> int:
# return data + CONSTANT
print(data + CONSTANT) class WrapFun():
def __init__(self, pickled_fun):
self.pickled_fun = pickle.dumps(pickled_fun)
def __call__(self, *args, **kwargs):
self.fun = pickle.loads(self.pickled_fun)
return self.fun(*args, **kwargs) if __name__ == '__main__':
f = WrapFun(my_function) CONSTANT = 0
ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
# p = ctx.Process(target=my_function, args=(43,))
p = ctx.Process(target=f, args=(43,))
p.start()
# p.join() time.sleep(60)
效果:

使用cloudpickle序列化target函数:
import multiprocessing as mp
import cloudpickle
import numpy as np
import time CONSTANT = 42
def my_function(data: int) -> int:
# return data + CONSTANT
print(data + CONSTANT) class WrapFun():
def __init__(self, pickled_fun):
self.pickled_fun = cloudpickle.dumps(pickled_fun)
def __call__(self, *args, **kwargs):
self.fun = cloudpickle.loads(self.pickled_fun)
return self.fun(*args, **kwargs) if __name__ == '__main__':
f = WrapFun(my_function) CONSTANT = 0
ctx = mp.get_context('fork')
# ctx = mp.get_context('spawn')
# p = ctx.Process(target=my_function, args=(43,))
p = ctx.Process(target=f, args=(43,))
p.start()
# p.join() time.sleep(60)

可以看到,使用cloudpickle进行序列化target可以通过value序列化将target函数涉及的参数一并打包序列化,这也是为什么很多计算框架在为multiprocessing传递target函数时使用cloudpickle的方式。
关于cloudpickle的使用见:
cloudpickle —— Python分布式序列化的专用模块
=======================================================
python多进程multiprocessing模块的变量传递问题:父进程中的numpy.array对象隐式序列化到子进程后的inplace操作的问题的更多相关文章
- python多进程multiprocessing模块中Queue的妙用
最近的部门RPA项目中,小爬为了提升爬虫性能,使用了Python中的多进程(multiprocessing)技术,里面需要用到进程锁Lock,用到进程池Pool,同时利用map方法一次构造多个proc ...
- Python(多进程multiprocessing模块)
day31 http://www.cnblogs.com/yuanchenqi/articles/5745958.html 由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分 ...
- python 多进程multiprocessing 模块
multiprocessing 常用方法: cpu_count():统计cpu核数 multiprocessing.cpu_count() active_children() 获取所有子进程 mult ...
- python多进程multiprocessing Pool相关问题
python多进程想必大部分人都用到过,可以充分利用多核CPU让代码效率更高效. 我们看看multiprocessing.pool.Pool.map的官方用法 map(func, iterable[, ...
- python多进程-----multiprocessing包
multiprocessing并非是python的一个模块,而是python中多进程管理的一个包,在学习的时候可以与threading这个模块作类比,正如我们在上一篇转载的文章中所提,python的多 ...
- 多进程 multiprocessing 模块进程并发Process;Pool ;Queue队列 、threading模块;
multiprocessing 模块中的 Process类提供了跨平台的多进程功能,在windows和linux系统都可以使用. 1.首先要实例化一个类,传入要执行的函数. 实例名 = Process ...
- Python之multiprocessing模块的使用
作用:Python多进程处理模块,解决threading模块不能使用多个CPU内核,避免Python GIL(全局解释器)带来的计算瓶颈. 1.开启多进程的简单示例,处理函数无带参数 #!/usr/b ...
- 多进程Multiprocessing模块
多进程 Multiprocessing 模块 先看看下面的几个方法: star() 方法启动进程, join() 方法实现进程间的同步,等待所有进程退出. close() 用来阻止多余的进程涌入进程池 ...
- Python 多进程multiprocessing
一.python多线程其实在底层来说只是单线程,因此python多线程也称为假线程,之所以用多线程的意义是因为线程不停的切换这样比串行还是要快很多.python多线程中只要涉及到io或者sleep就会 ...
- Python 多进程 multiprocessing.Pool类详解
Python 多进程 multiprocessing.Pool类详解 https://blog.csdn.net/SeeTheWorld518/article/details/49639651
随机推荐
- 2024-06-15:用go语言,Alice 和 Bob 在一个环形草地上玩一个回合制游戏。 草地上分布着一些鲜花,其中 Alice 到 Bob 之间顺时针方向有 x 朵鲜花,逆时针方向有 y 朵鲜花
2024-06-15:用go语言,Alice 和 Bob 在一个环形草地上玩一个回合制游戏. 草地上分布着一些鲜花,其中 Alice 到 Bob 之间顺时针方向有 x 朵鲜花,逆时针方向有 y 朵鲜花 ...
- 我写CSS的常用套路(附demo的效果实现与源码)
大赞: https://mp.weixin.qq.com/s/dYCWYeM629DwiSqmaaAs1w
- Nginx SSL证书更新及密码套件更新
一.域名更换证书 ssl证书一般包括证书文件crt.cer.pem.pfx和私钥文件key. CER.CRT.PEM 和 PFX 是不同的证书文件格式,它们之间存在一些区别: CER (DER 编码) ...
- 使用Spleete进行人声与背景声分离
安装:https://pypi.org/project/spleeter/ 下载权重: 2sterms.tar.gz https://github.com/deezer/spleeter/releas ...
- (sql语句试题练习及 参考答案解题思路+个人解题思路)
SQL字段说明及数据 ======================================================================= 一.部门表字段描述:dp_no 部 ...
- Notepad++ 搭建简单Java编译运行环境
简介 有时候使用Eclips进行Java相关方法的测试和验证太繁琐,经过查询实践,使用了Notepad++和JDK搭建了一个简单的编译运行环境. 搭建过程 在电脑上安装Java环境(网上教程很多,此过 ...
- null 和 undefined 的区别?
null 表示一个对象被定义了,值为"空值":undefined 表示不存在这个值.(1)变量被声明了,但没有赋值时,就等于undefined. (2) 调用函数时,应该提供的参数 ...
- yb课堂 新版VueCli 4.3创建vue项目,Vue基础语法入门 《二十九》
Vue模版语法开发起步 基于HTML的模版语法,允许声明式地将DOM绑定至底层Vue实例的数据 用简洁的模版语法来声明式的将数据渲染进DOM的系统 结合响应系统,在应用状态改变时,Vue能够智能地计算 ...
- 什么情况下会使用array.reduce函数
当业务需要从一个数组里求出某项的和的时候. 1.for遍历 var a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] var resulte = 0; for (let inde ...
- Java 知识总结大汇总!看完哪个都变大佬!
免费编程资源大全项目:https://github.com/liyupi/free-programming-resources 大家好,我是鱼皮,今天分享 十几个 让人直呼 "哇塞" ...