[转帖]prometheus和node_exporter中的磁盘监控
https://www.ipcpu.com/2021/04/prometheus-node_exporter/
prometheus和node_exporter中的磁盘监控.md
对于磁盘问题,我们主要关注以下几个指标:
磁盘空间使用率、磁盘inode使用率(df -h和df -i命令)
磁盘读写次数IOPS (iostat中的r/s、w/s)
磁盘读写带宽 (iostat中的rkB/s、wkB/s)
磁盘IO利用率%util (iostat中的%util)
磁盘队列数 (iostat中的avgqu-sz)
磁盘读写的延迟时间 (iostat中的r_await、w_await)

这些指标都可以在node_exporter中找到对于的线索。
1. 磁盘空间使用率和磁盘inode使用率
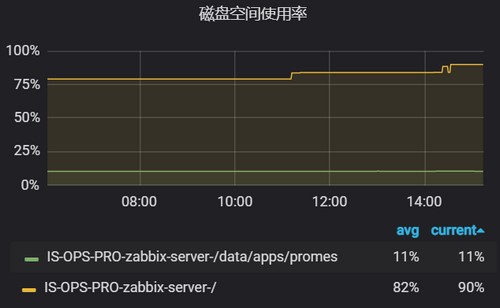
磁盘空间使用率
100 - ((node_filesystem_avail_bytes{instance=~"$hostname",fstype=~"ext4|xfs"} * 100) / node_filesystem_size_bytes{instance=~"$hostname",fstype=~"ext4|xfs"})
磁盘inode使用率
100 -node_filesystem_files_free{instance=~"$hostname",fstype=~"ext4|xfs"}/node_filesystem_files{instance=~"$hostname",fstype=~"ext4|xfs"} * 1002. 磁盘IOPS
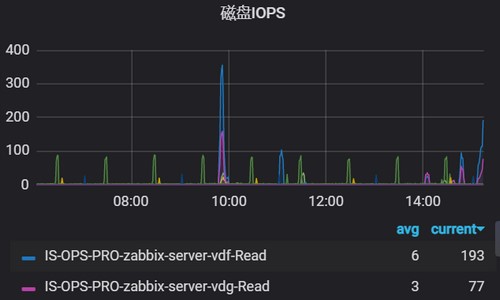
读IOPS
rate(node_disk_reads_completed_total{instance=~"$hostname",device=~"[a-z]*[a-z]"}[5m])
写IOPS
rate(node_disk_writes_completed_total{instance=~"$hostname",device=~"[a-z]*[a-z]"}[5m])3. 磁盘IO利用率%util
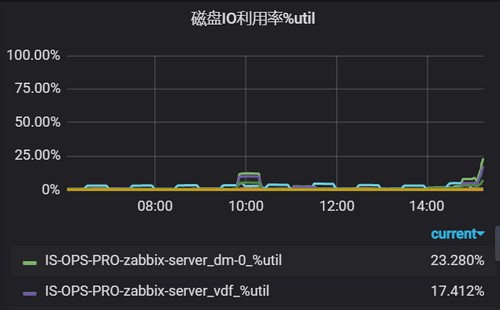
磁盘IO利用率(iostat中的%util,取值范围[0-1])
rate(node_disk_io_time_seconds_total{instance=~"$hostname"}[5m]) util%到达100%并不一定会存在磁盘瓶颈,因为磁盘设备可以并发(fio中的多队列),判断磁盘瓶颈要根据util%、IO队列数、读写延迟的历史趋势来判断。没有办法,因为磁盘厂商也没给出相关参考。
4. 磁盘设备平均IO队列数
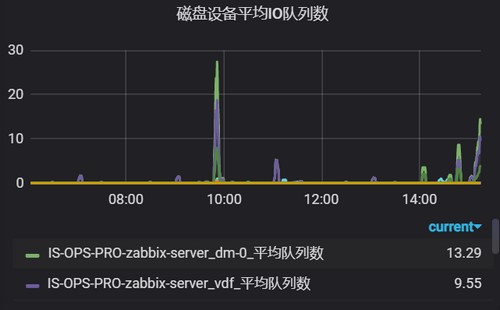
rate(node_disk_io_time_weighted_seconds_total{instance=~"$hostname"}[5m])5. 磁盘设备读写延迟
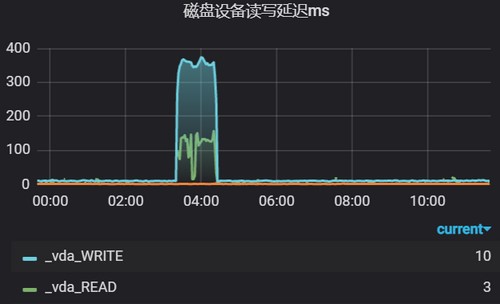
读延迟(ms)
rate(node_disk_read_time_seconds_total{instance=~"$hostname"}[5m]) / rate(node_disk_reads_completed_total{instance=~"$hostname"}[5m]) * 1000
写延迟(ms)
rate(node_disk_write_time_seconds_total{instance=~"$hostname"}[5m]) / rate(node_disk_writes_completed_total{instance=~"$hostname"}[5m]) * 1000这个值的单位是秒, 不太好看,乘以1000可以换算成毫秒ms。这个值与设备有关,本地盘、网络盘、SSD磁盘的读写延迟级别不一。
参考资料
https://www.robustperception.io/mapping-iostat-to-the-node-exporters-node_disk_-metrics
https://brian-candler.medium.com/interpreting-prometheus-metrics-for-linux-disk-i-o-utilization-4db53dfedcfc
https://devconnected.com/monitoring-disk-i-o-on-linux-with-the-node-exporter/
转载请注明:IPCPU-网络之路 » prometheus和node_exporter中的磁盘监控
[转帖]prometheus和node_exporter中的磁盘监控的更多相关文章
- [转帖]prometheus数据采集exporter全家桶
prometheus数据采集exporter全家桶 Rainbowhhy1人评论2731人阅读2019-04-06 15:38:32 https://blog.51cto.com/13053917/2 ...
- Grafana+Prometheus通过node_exporter监控Linux服务器信息
Grafana+Prometheus通过node_exporter监控Linux服务器信息 一.Grafana+Prometheus通过node_exporter监控Linux服务器信息 1.1nod ...
- prometheus + grafana + node_exporter + alertmanager 的安装部署与邮件报警 (一)
大家一定要先看详细的理论教程,再开始搭建,这样报错后才容易找到突破口 参考文档 https://www.cnblogs.com/afterdawn/p/9020129.html https://www ...
- prometheus、node_exporter、cAdvisor常用参数
本节将介绍一下我在使用过程中用到的promethues.node_exporter.cAdvisor的常用参数,做一个总结 一.prometheus prometheus分为容器安装和二进制文件安装, ...
- Golang 基于Prometheus Node_Exporter 开发自定义脚本监控
Golang 基于Prometheus Node_Exporter 开发自定义脚本监控 公司是今年决定将一些传统应用从虚拟机上迁移到Kubernetes上的,项目多而乱,所以迁移工作进展缓慢,为了建立 ...
- prometheus、node_exporter设置开机自启动
方法一.写入rc.local 在/etc/rc.local文件中编辑需要执行的脚本或者命令,我个人习惯用这个,因人而异,有的项目可能需要热加载配置文件,用服务会更好 #普罗米修斯启动,需要后面接con ...
- Linux 在 i 节点表中的磁盘地址表中,若一个文件的长度是从磁盘地址表的第 1 块到第 11 块 解析?
面试题: 在 i 节点表中的磁盘地址表中,若一个文件的长度是从磁盘地址表的第 1 块到第 11块,则该文件共占有 B 块号.A 256 B 266 C 11 D 256×10 linux文件系统是L ...
- 如何在 Linux 中整理磁盘碎片
有一个神话是 linux 的磁盘从来不需要整理碎片.在大多数情况下这是真的,大多数因为是使用的是优秀的日志文件系统(ext3.4等等)来处理文件系统.然而,在一些特殊情况下,碎片仍旧会产生.如果正巧发 ...
- Linux中的磁盘
Linux的磁盘管理 (很重要请注意高能预警) 硬盘:几个盘片,双面,磁性颗粒, 处理速率不同步:借助于一个中间层 文件系统(FileSystem) 可以实现对磁盘行的文件进行读写 文 ...
- vm中centos7磁盘扩容
在VM虚拟平台管理客户端,将虚拟机关机后,将分配的磁盘大小30G扩至300G.如图. 调整完后,重新打开虚拟机,使用fdisk -l查看,可以看到我们刚刚扩容的空间已经可以看到,但没有分区,还 ...
随机推荐
- kafka源码阅读之MacBook Pro M1搭建Kafka2.7版本源码运行环境
原创/朱季谦 最近在阅读Kafka的源码,想可以在阅读过程当中,在代码写一些注释,便决定将源码部署到本地运行. 日常开发过程中,用得比较多一个版本是Kafka2.7版本,故而在MacBook Pro笔 ...
- node版本管理工具推荐
hello,今天给大家分享几款 node 版本管理的工具. 背景 在开发前端项目的时候,特别是新到公司接手一个多年维护的老项目时,如果 node 版本不正确,有的插件可能无法正确安装,比如我之前提到的 ...
- 遍历菜单树得到所有菜单ids
1.前言 在我们实现菜单管理页面的时候,有时候我们需要默认展开所有的菜单列表,但是因为后端有时候没有返回所有菜单ids数组. 而且我们也不容易获取到所有菜单ids,比如如果我们通过角色id查询到所有菜 ...
- .NET Core Swagger Actions require a unique method/path combination for Swagger/OpenAPI 3.0. Use ConflictingActionsResolver as a workaround
遇到的问题 因为新增了一个控制器方法,从而导致在运行Swagger的时候直接报错,异常如下: SwaggerGeneratorException: Conflicting method/path co ...
- 消除视觉Transformer与卷积神经网络在小数据集上的差距
摘要:本文通过多种操作构建混合模型,增强视觉Transformer捕捉空间相关性的能力和其进行通道多样性表征的能力,弥补了Transformer在小数据集上从头训练的精度与传统的卷积神经网络之间的差距 ...
- 个性化联邦学习算法框架发布,赋能AI药物研发
摘要:近期,中科院上海药物所.上海科技大学联合华为云医疗智能体团队,在Science China Life Sciences 发表题为"Facing Small and Biased Dat ...
- 带你学会区分Scheduled Thread Pool Executor 与Timer
摘要:本文简单介绍下Scheduled Thread Pool Executor类与Timer类的区别,Scheduled Thread Pool Executor类相比于Timer类来说,究竟有哪些 ...
- presto是如何保证作业内存不会发生冲突和溢出
摘要:presto计算引擎作为一个纯内存计算引擎,是如何保证计算过程不会发生作业内存溢出的?本篇文章会进行深入的学习和分析. 本文分享自华为云社区<presto是如何保证作业内存不会发生冲突和溢 ...
- 火山引擎DataTester:如何使用A/B测试优化全域营销效果
当前,营销技术步入了全渠道.全周期的全域时代,随着广泛的数据积累,数据科学技术在营销领域发挥着越来越重要的作用,从消费者人群洞察到智能化信息广告投放,营销的提效让企业得以在转化的每个环节提升影响力 ...
- 火山引擎 DataLeap:在数据研发中,如何提升效率?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 在数仓及中台研发过程中,研发人员经常需要在不同任务中维护相同或类似代码,不仅费时费力,并且代码迭代后也面临不同业务 ...