spark与Scala安装过程和步骤及sparkshell命令的使用

Spark与Scala版本兼容问题:
Spark运行在Java 8 +,Python 2.7 + / 3.4 +和R 3.1+上。对于Scala API,Spark 2.4.2使用Scala 2.12。您需要使用兼容的Scala版本(2.12.x)。
请注意,自Spark 2.2.0起,对2.6.5之前的Java 7,Python 2.6和旧Hadoop版本的支持已被删除。自2.3.0起,对Scala 2.10的支持被删除。自Spark 2.4.1起,对Scala 2.11的支持已被弃用,将在Spark 3.0中删除。
https://spark.apache.org/docs/latest/index.html
1.官网下载安装Scala:scala-2.12.8.tgz
https://www.scala-lang.org/download/
2.将Scala解压到/opt/module目录下
tar -zxvf scala-2.12.8.tgz -C /opt/module
3.将scala-2.12.8改成Scala
mv scala-2.12.8 scala
4.测试scala是否安装成功
测试:scala -version
5.启动Scala命令:scala

1.官网下载安装Spark:spark-2.4.2-bin-hadoop2.7.tgz
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz
2.解压、重命名
ar -zxvf spark-2.4.2-bin-hadoop2.7.tgz -C /opt/module
mv spark-2.4.2-bin-hadoop2.7.tgz spark
3.配置环境变量
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin #
使环境变量生效 :source /etc/profile
4.启动spark
①先启动hadoop 环境
start-all.sh
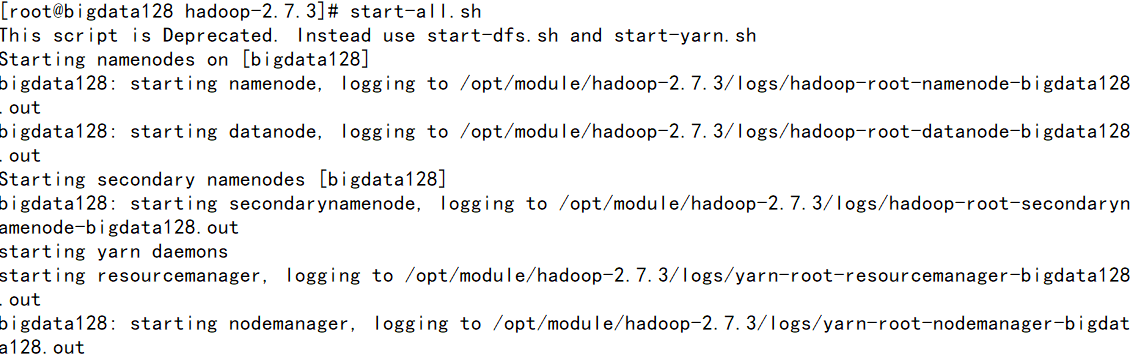
②启动spark环境
进入到SPARK_HOME/sbin下运行start-all.sh
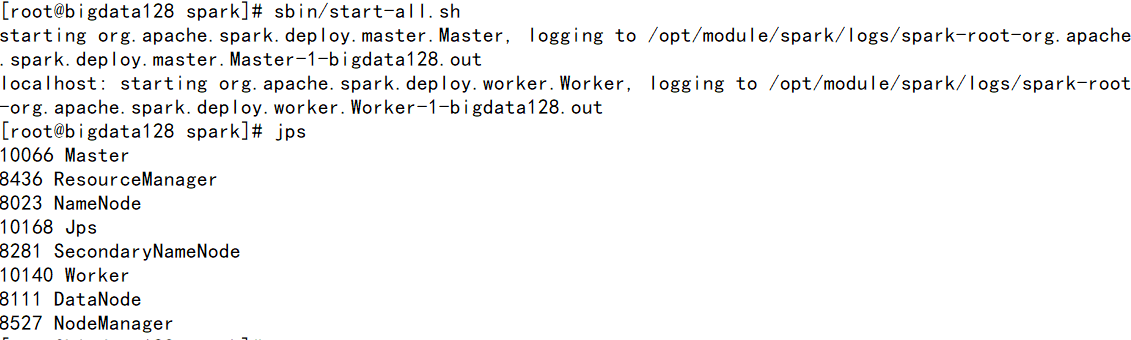
[注] 如果使用start-all.sh时候会重复启动hadoop配置,需要./在当前工作目录下执行命令
jps 观察进程 多出 worker 和 mater 两个进程。
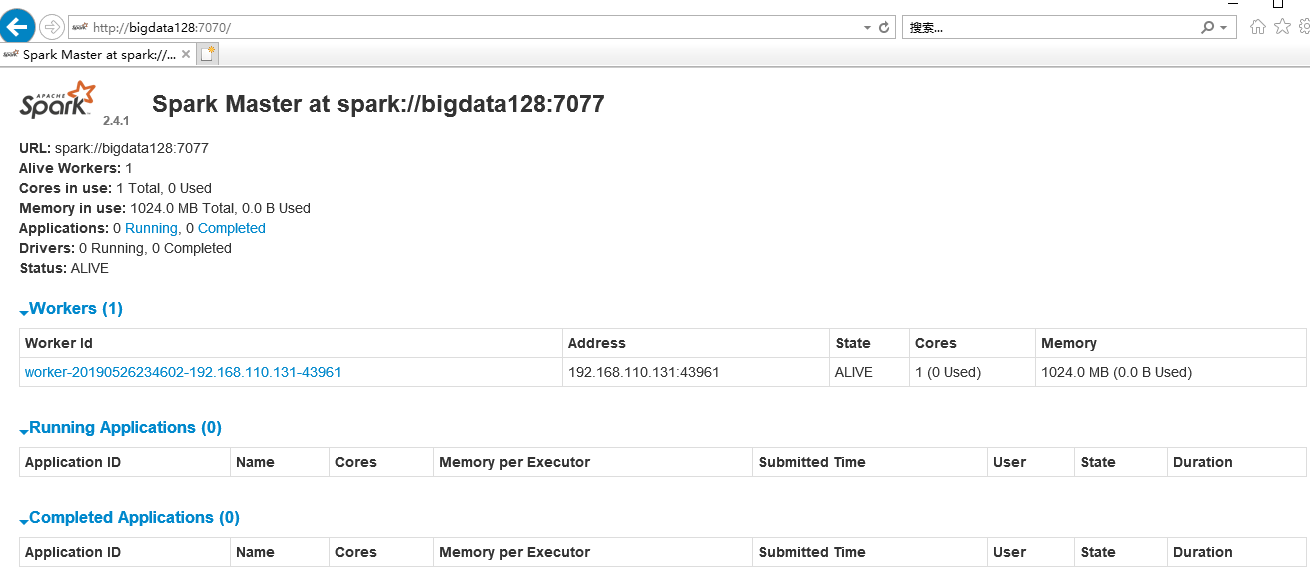
5.查看spark的web控制页面:http://bigdata128:7077/
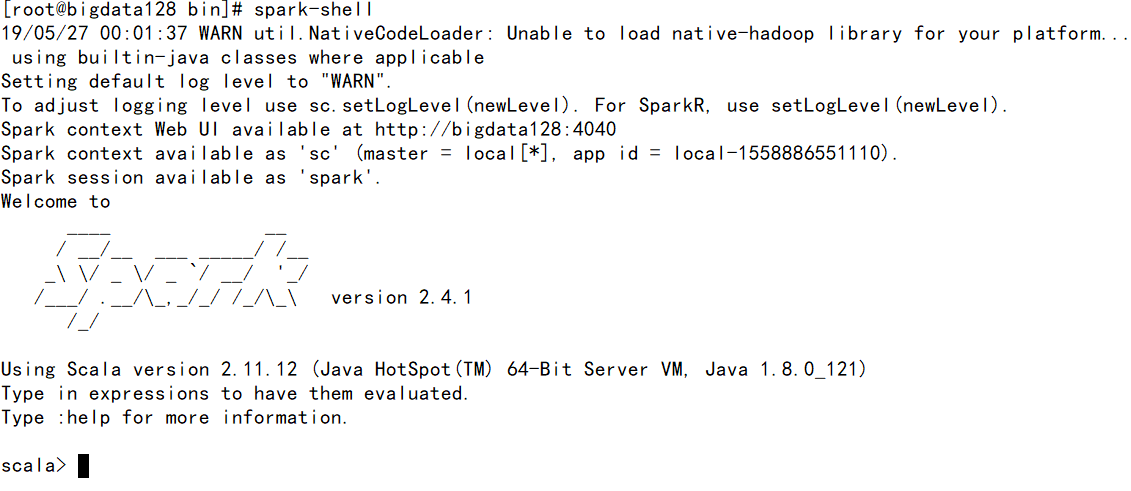
使用Spark-shell命令
此模式用于interactive programming,先进入bin文件夹后运行:spark-shell

spark与Scala安装过程和步骤及sparkshell命令的使用的更多相关文章
- Bigbluebutton安装过程
BigBlueButton安装过程(翻译) 欢迎来到BigBlueButton 1.0-beta安装指南(以下简称BigBlueButton 1.0).BigBlueButton是一个开放源代码的网络 ...
- Spark安装过程纪录
1 Scala安装 1.1 master 机器 修改 scala 目录所属用户和用户组. sudo chown -R hadoop:hadoop scala 修改环境变量文件 .bashrc , 添加 ...
- JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!)
JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!) 1.文件准备: 服务器:CentOS Linux release 7.3.1611 (Core) Apa ...
- Spark安装过程
Precondition:jdk.Scala安装,/etc/profile文件部分内容如下: JAVA_HOME=/home/Spark/husor/jdk CLASSPATH=.:$JAVA_HOM ...
- eclipse创建maven管理Spark的scala
说明,由于spark是用scala写的.因此,不管是在看源码还是在写spark有关的代码的时候,都最好是用scala.那么作为一个程序员首先是必须要把手中的宝剑给磨砺了.那就是创建好编写scala的代 ...
- Spark学习笔记——安装和WordCount
1.去清华的镜像站点下载文件spark-2.1.0-bin-without-hadoop.tgz,不要下spark-2.1.0-bin-hadoop2.7.tgz 2.把文件解压到/usr/local ...
- spark集群安装部署
通过Ambari(HDP)或者Cloudera Management (CDH)等集群管理服务安装和部署在此不多介绍,只需要在界面直接操作和配置即可,本文主要通过原生安装,熟悉安装配置流程. 1.选取 ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
随机推荐
- Bootstrap 响应式表格
响应式表格 通过把任意的 .table 包在 .table-responsive class 内,您可以让表格水平滚动以适应小型设备(小于 768px).当在大于 768px 宽的大型设备上查看时,您 ...
- HDU-1009-肥鼠交易
这题是一道简单的可拆分的贪心题目,需要注意的是,我们定义的结构体里面都应该用double类型, 或者float类型,不然两个int相除,就失去了精度(强转也可以). #include <cstd ...
- xadmin下设置“use_bootswatch = True”无效的解决办法
环境: python 2.7 django 1.9 xadmin采用源代码的方式引入到项目中 问题: 在xadmin使用的过程中,设置“use_bootswatch = True”,企图调出主题菜单, ...
- Python自动化测试框架——数据驱动(从代码中读取)
今天小编要介绍的是数据驱动最简单和最常用的一种方法,由于只是介绍方法,代码操作后的美观程度略有缺陷,介意者可以自行改动 还是以163邮箱登录为例: 设计一个存放数据的类,这个类的参数是我们需要修改的数 ...
- RN踩坑
使用夜神 使用夜神作为模拟器,这个模拟器启动就会监听62001端口. 开发工具与模拟器的通信都是通过adb.夜神模拟器的安装目录/bin下有一个adb.exe,android sdk tools下也有 ...
- 【css】清楚浏览器端缓存
/css/common.css?version=1.0.7 在css链接后面加个参数版本号控制,刷新浏览器缓存
- tiny4412 busybox制作根文件系统rootfs nfs 挂载 ubuntu 14.04
http://blog.csdn.net/liudijiang/article/details/50555429(转) 首先得要有制作好的uboot和linux内核镜像zImage,先烧录到sd卡里, ...
- UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 167: illegal multibyte sequence
UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 167: illegal multibyte sequence文件 ...
- git克隆/更新/提交代码步骤及示意图
1. git clone ssh://flycm.intel.com/scm/at/atSrc 或者git clone ssh://flycm.intel.com/scm/at/atJar 或者g ...
- Java-替换字符串中的子字符串
自顶一个repace方法 package com.tj; public class MyClass implements Cloneable { public static void main(Str ...