Zeppelin0.5.6使用spark解释器
Zeppelin为0.5.6
Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用。
使用其他的spark集群在yarn模式下。
配置:
vi zeppelin-env.sh

添加:
export SPARK_HOME=/usr/crh/current/spark-client
export SPARK_SUBMIT_OPTIONS="--driver-memory 512M --executor-memory 1G"
export HADOOP_CONF_DIR=/etc/hadoop/conf
Zeppelin Interpreter配置

注意:设置完重启解释器。
Properties的master属性如下:

新建Notebook
Tips:几个月前zeppelin还是0.5.6,现在最新0.6.2,zeppelin 0.5.6写notebook时前面必须加%spark,而0.6.2若什么也不加就默认是scala语言。
zeppelin 0.5.6不加就报如下错:
Connect to 'databank:4300' failed
%spark.sql
select count(*) from tc.gjl_test0
报错:
com.fasterxml.jackson.databind.JsonMappingException: Could not find creator property with name 'id' (in class org.apache.spark.rdd.RDDOperationScope)
at [Source: {"id":"2","name":"ConvertToSafe"}; line: 1, column: 1]
at com.fasterxml.jackson.databind.JsonMappingException.from(JsonMappingException.java:148)
at com.fasterxml.jackson.databind.DeserializationContext.mappingException(DeserializationContext.java:843)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.addBeanProps(BeanDeserializerFactory.java:533)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.buildBeanDeserializer(BeanDeserializerFactory.java:220)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.createBeanDeserializer(BeanDeserializerFactory.java:143)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer2(DeserializerCache.java:409)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer(DeserializerCache.java:358)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCache2(DeserializerCache.java:265)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCacheValueDeserializer(DeserializerCache.java:245)
at com.fasterxml.jackson.databind.deser.DeserializerCache.findValueDeserializer(DeserializerCache.java:143)
at com.fasterxml.jackson.databind.DeserializationContext.findRootValueDeserializer(DeserializationContext.java:439)
at com.fasterxml.jackson.databind.ObjectMapper._findRootDeserializer(ObjectMapper.java:3666)
at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:3558)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:2578)
at org.apache.spark.rdd.RDDOperationScope$.fromJson(RDDOperationScope.scala:85)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at scala.Option.map(Option.scala:145)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:136)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.ConvertToSafe.doExecute(rowFormatConverters.scala:56)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:130)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:187)
at org.apache.spark.sql.execution.Limit.executeCollect(basicOperators.scala:165)
at org.apache.spark.sql.execution.SparkPlan.executeCollectPublic(SparkPlan.scala:174)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:56)
at org.apache.spark.sql.DataFrame.withNewExecutionId(DataFrame.scala:2086)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$execute$1(DataFrame.scala:1498)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$collect(DataFrame.scala:1505)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1375)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.withCallback(DataFrame.scala:2099)
at org.apache.spark.sql.DataFrame.head(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.take(DataFrame.scala:1456)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.zeppelin.spark.ZeppelinContext.showDF(ZeppelinContext.java:297)
at org.apache.zeppelin.spark.SparkSqlInterpreter.interpret(SparkSqlInterpreter.java:144)
at org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)
at org.apache.zeppelin.scheduler.Job.run(Job.java:169)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:134)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:
进入/opt/zeppelin-0.5.6-incubating-bin-all目录下:
# ls lib |grep jackson
jackson-annotations-2.5.0.jar
jackson-core-2.5.3.jar
jackson-databind-2.5.3.jar
将里面的版本换成如下版本:
# ls lib |grep jackson
jackson-annotations-2.4.4.jar
jackson-core-2.4.4.jar
jackson-databind-2.4.4.jar
测试成功!
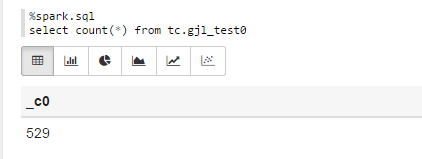
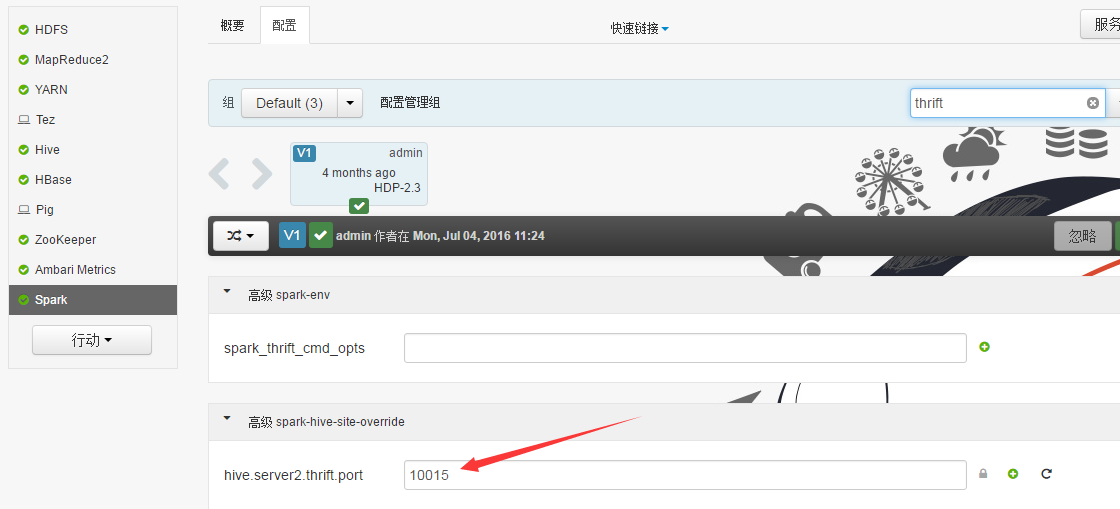
Sparksql也可直接通过hive jdbc连接,只需换端口,如下图:

Zeppelin0.5.6使用spark解释器的更多相关文章
- Zeppelin使用spark解释器
Zeppelin为0.5.6 Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用. 使用其他的spark集群在yarn模式下. 配置: vi zeppelin ...
- Zeppelin0.6.2使用hive解释器
Zeppelin0.6.2的jdbc Interpreter 配置 1.拷贝hive的配置文件hive-site.xml到zeppelin-0.6.2-bin-all/conf下. 2.进入conf下 ...
- Zeppelin0.5.6使用hive解释器
此zeppelin为官方0.5.6版,可能还在孵化阶段,可能出现一些bug吧. 配置 cp zeppelin-env.sh.template zeppelin-env.sh vi zeppelin-e ...
- Zeppelin0.7.2结合hive解释器进行报表展示
前提:服务器已经安装好了hadoop_client端即hadoop的环境hbase,hive等相关组件 1.环境和变量配置①拷贝hive的配置文件hive-site.xml到zeppelin-0.7. ...
- Zeppelin使用Spark的yarn-client模式
Zeppelin版本0.6.2 1. Export SPARK_HOME In conf/zeppelin-env.sh, export SPARK_HOME environment variable ...
- Apache Spark 2.2.0 中文文档 - Spark RDD(Resilient Distributed Datasets)论文 | ApacheCN
Spark RDD(Resilient Distributed Datasets)论文 概要 1: 介绍 2: Resilient Distributed Datasets(RDDs) 2.1 RDD ...
- Apache Spark RDD(Resilient Distributed Datasets)论文
Spark RDD(Resilient Distributed Datasets)论文 概要 1: 介绍 2: Resilient Distributed Datasets(RDDs) 2.1 RDD ...
- hadoop-2.7.3.tar.gz + spark-2.0.2-bin-hadoop2.7.tgz + zeppelin-0.6.2-incubating-bin-all.tgz(master、slave1和slave2)(博主推荐)(图文详解)
不多说,直接上干货! 我这里,采取的是ubuntu 16.04系统,当然大家也可以在CentOS6.5里,这些都是小事 CentOS 6.5的安装详解 hadoop-2.6.0.tar.gz + sp ...
- Zeppelin 0.6.2使用Spark的yarn-client模式
Zeppelin版本0.6.2 1. Export SPARK_HOME In conf/zeppelin-env.sh, export SPARK_HOME environment variable ...
随机推荐
- wpf VisualBrush 的使用,可创建重复图像
VisualBrush 类(msdn) <Grid.Background> <VisualBrush TileMode="Tile" Viewport=" ...
- 线程间操作无效: 从不是创建控件“labMessage”的线程访问它。
解决方法:1.在窗体加载时加上这一句 private void FormDate_Load(object sender, EventArgs e) { Control.CheckForIllegalC ...
- 微信小程序把玩(二十三)modal组件
原文:微信小程序把玩(二十三)modal组件 modal弹出框常用在提示一些信息比如:退出应用,清楚缓存,修改资料提交时一些提示等等. 常用属性: wxml <!--监听button点击事件-- ...
- Android零基础入门第50节:StackView卡片堆叠
原文:Android零基础入门第50节:StackView卡片堆叠 上一期学习了AdapterViewFilpper的使用,你已经掌握了吗?本期开始学习StackView的使用. 一.认识StackV ...
- 使用Boost的DLL库管理动态链接库(类似于Qt中的QLibrary)
Boost 1.61新增了一个DLL库,跟Qt中的QLibrary类似,提供了跨平台的动态库链接库加载.调用等功能.http://www.boost.org/users/history/version ...
- 使用.NET进行高效率互联网敏捷开发的思考和探索【一、概述】
不知从什么时候开始,创业变得很廉价,谈什么都是互联网,动辄融资千万.这阵风好像也刮向了程序员中,有那么一大批开发者,数据结构不好好学习.数据库原理不扎实掌握,在github上发布几个项目,用nodej ...
- R3 HOOK OpenProcess 的问题
unit HookAPI; //Download by http://www.codefans.net interface uses Windows, Classes; function Locate ...
- 事务 ( 进程 ID 60) 与另一个进程被死锁在锁资源上,并且已被选作死锁牺牲品
Select * FROM [TableName] With(NoLock) .....
- 浅析C#代理
delegate 是委托声明的基础,是.net 的委托的声明的关键字action 是基于delegate实现的代理 有多个参数(无限制个数)无返回值的代理 func 是基于delegate实现的代理 ...
- vs2010添加TSTCON( ActiveX Control Test Container )工具
vs2010中的TSTCON( ActiveX Control Test Container )工具非自动安装,而是作为一个例程提供.所以应找到该例程,并编译: 如vs2010安装在默认路径则 1, ...