爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~
分析b站小视频
1、进入到抓取链接地址
http://vc.bilibili.com/p/eden/rank#/?tab=%E5%85%A8%E9%83%A8
2、分析抓取链接内容
通过F12或者抓包工具进行查看我们需要爬取的视频在哪里存放,页面以ajax动态加载的
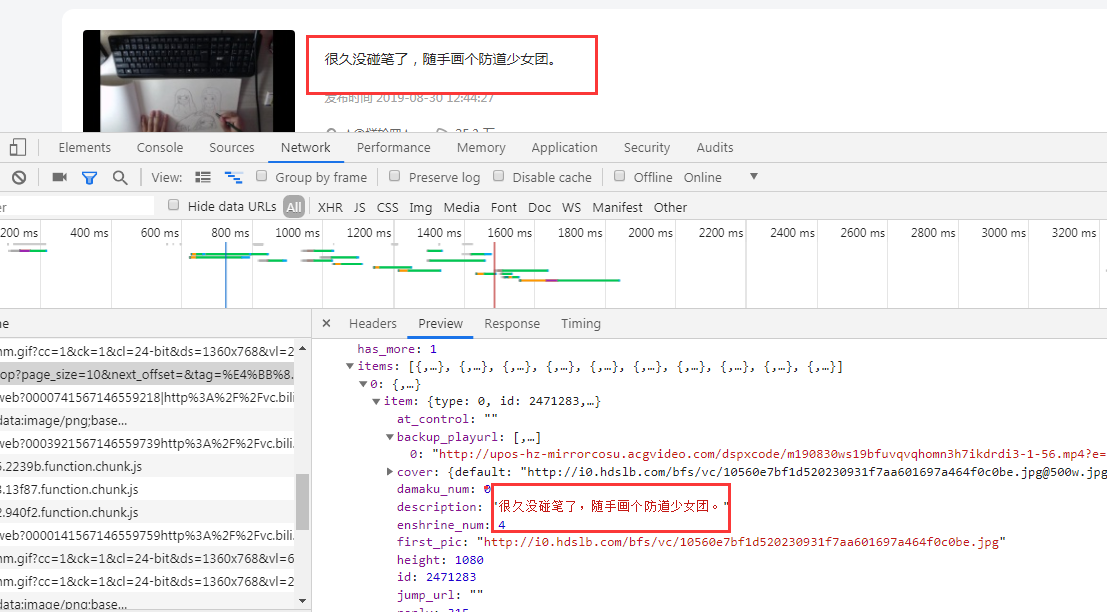
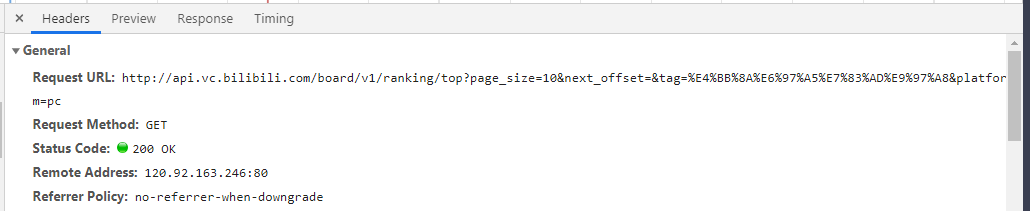
3、分析请求内容和请求参数
通过查看请求内容得到这些数据
1、请求的接口地址
2、请求方式为get
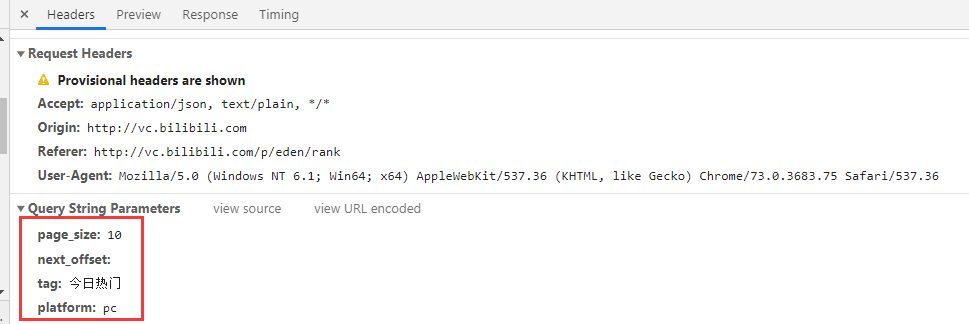
3、请求参数为
- page_size 显示的个数
- next_offset 动态跳转页面
- tag 搜索标题
- platfrom (应该是pc端)
分析了页面内容,那么动手来写代码,爬取视频下来
爬取b站小视频
开始写代码之前呢,我们也要一步一步的来,分清楚每一步都是干什么用的,这样的话才能让我们写的代码更加清除。
1、构建请求信息,请求需要爬取的地址
# 构建请求信息,获取数据信息
def get_json(url,ajax):
# 构建请求信息
params = {
'page_size':10,
'next_offset': ajax,
'tag':'今日热门',
'platform':'pc'
}
# 防止请求失败
try:
html = requests.get(url,params=params,headers=headers).json()
return html
except BaseException:
print('页面加载失败')
2、进行访问链接,下载视频
# 获取视频信息
def get_video(viedeo_url,path):
# 取出来视频的名称和地址
r2 = requests.get(viedeo_url,headers=headers)
with open(path,'wb')as f:
f.write(r2.content)
3、保存下载的视频
infos=html['data']['items']
for info in infos:
title = info['item']['description']#小视频的标题
video_url = info['item']['video_playurl']#视频地址
print(title,video_url)
#为了防止视频没有video_url
try:
get_video(video_url,path=r"E:\app\视频\%s.mp4"%title)
print("成功下载一个")
except BaseException:
print("下载失败")
pass
完整代码
import requests
import random
import time
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"
}
def get_json(url,ajax):
# 构建请求信息
params = {
'page_size':10,
'next_offset': ajax,
'tag':'今日热门',
'platform':'pc'
}
# 防止请求失败
try:
html = requests.get(url,params=params,headers=headers).json()
return html
except BaseException:
print('页面加载失败')
def get_video(viedeo_url,path):
# 取出来视频的名称和地址
r2 = requests.get(viedeo_url,headers=headers)
with open(path,'wb')as f:
f.write(r2.content)
if __name__ == '__main__':
for i in range(3):
url='http://api.vc.bilibili.com/board/v1/ranking/top?'
num=i*10+1
html=get_json(url,num)
infos=html['data']['items']
for info in infos:
title = info['item']['description']#小视频的标题
video_url = info['item']['video_playurl']#视频地址
print(title,video_url)
#为了防止视频没有video_url
try:
get_video(video_url,path=r"E:\app\视频\%s.mp4"%title)
print("成功下载一个")
except BaseException:
print("下载失败")
pass
# 设置加载时间
time.sleep(random.random() * 3)
写的时间有点紧急,大概的写了下过程,如果不懂的地方可以下方留言,看到后第一时间会进行回复,感觉写的对您有帮助,点个关注~~~~
爬虫---爬取b站小视频的更多相关文章
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
- 抓取B站小视频
抓取B站小视频的代码如下: #请求库import requests #请求头部信息(用户代理)headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; ...
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- 爬取b站互动视频信息
首先分辨视频是不是互动视频可以看 https://api.bilibili.com/x/player.so?id=cid:1&aid=89017 这个api返回的xml中的 <inter ...
- 简单的方法爬取b站dnf视频封面步骤解释
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html 首先我们要知道,一个分区封面显示到底在哪里可以找到. 很明显,查看审查元素并不能找 ...
- python爬虫——爬取B站用户在线人数
国庆期间想要统计一下bilibili网站的在线人数变化,写了一个简单的爬虫程序.主要是对https://api.bilibili.com/x/web-interface/online返回的参数进行分析 ...
- python爬取b站排行榜视频信息
和上一篇相比,差别不是很大 import xlrd#读取excel import xlwt#写入excel import requests import linecache import wordcl ...
- python3爬虫-爬取B站排行榜信息
import requests, re, time, os category_dic = { "all": "全站榜", "origin": ...
- Python 简单的方法爬取b站dnf视频封面
import urllib.request cnt=0 def instr(keystr): st=keystr.find('(')+1 strhtml=keystr[st:len(keystr)-1 ...
随机推荐
- 个人项目开源之Django图书借阅系统源代码
Django写的模拟图书借阅系统源代码已开源到码云 源代码
- 使用Anaconda3的Docker镜像
假设本地 Ubuntu 服务器已经安装好了Docker,这里讲述一下如何开始运行Anaconda3的Docker镜像: 1. 搜索镜像 搜索我们想要的anaconda镜像: docker search ...
- Django—开发具体流程
1.创建Django项目 [root@localhost ~]# django-admin startproject 项目名 [root@localhost ~]# django-admin star ...
- 机器学习实战之logistic回归分类
利用logistic回归进行分类的主要思想:根据现有数据对分类边界建立回归公式,并以此进行分类. logistic优缺点: 优点:计算代价不高,易于理解和实现.缺点:容易欠拟合,分类精度可能不高. . ...
- C++ 拷贝构造函数 copy ctor & 拷贝赋值函数 copy op=
类中含有 指针类型 的成员变量时,就必须要定义 copy ctor 和 copy op= copy ctor 请见: class Rectangle { public: Rectangle(Rec ...
- 实用小工具:VNC的安装
安装xen时,需要使用vnc工具来进行图形化安装,安装好后启动失败,试了很多办法,最终解决. 1.使用yum安装:yum install tigervnc-server tigervnc-server ...
- leetcode一刷总结,明天二刷
1:基础的数据结构:图掌握极差,二叉树次之 2:常用的算法思想:dp,深度有先,广度优先等等. 3:优化以解决的题目,注意思想的总结 4:将约150道题都刷掉 5:优先解决设计算法思想的题目类别,其次 ...
- Unity 利用Cinemachine快速创建灵活的相机系统
在第一或第三人称ACT和FPS游戏中,相机的运动需求是多种多样的,Unity内置的Cinemachine包可以助你快速实现不同相机功能,例如范围追踪,边界设置等. 例如,考虑这样一个功能,这在很多游戏 ...
- Flink JobManager 和 TaskManager 原理
转自:https://www.cnblogs.com/nicekk/p/11561836.html 一.概述 Flink 整个系统主要由两个组件组成,分别为 JobManager 和 TaskMana ...
- Python的定时器与线程池
定时器执行循环任务: 知识储备 Timer(interval, function, args=None, kwargs=None) interval ===> 时间间隔 单位为s functio ...