LiteDB源码解析系列(2)数据库页详解
在这一篇里,我将用图文的方式展示LiteDB中页的结构及作用,内容都是原创,在描述的过程中有不准确的地方烦请指出。
1.LiteDB页的技术工作原理
LiteDB虽然是单个文件类型的数据库,但是数据库有很多信息,例如索引,集合,文件等。为了管理这些信息,LiteDB实现了数据库页的概念。页是一个拥有4096 字节的 存储相同信息的地址块。页也是操作磁盘文件(读写)的最小单元。LiteDB有6中页类型,类图如下:
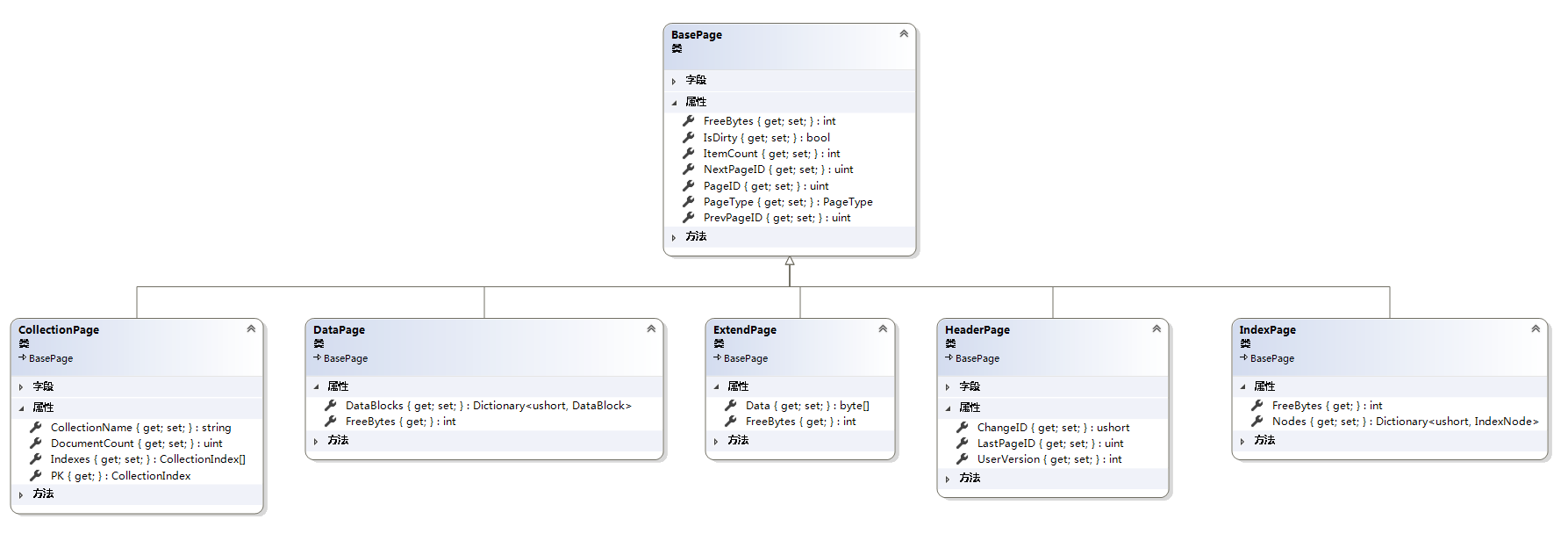
1.1 BasePage
BasePage是数据库页类型的父类,使用一个常量字段PAGE_SIZE定义了页的大小为4096个字节。
主要的属性说明如下:
PageID:一个uint类型的ID,在LiteDB数据库中,不管是哪种页类型,这个PageID都是不一样的。
PrevPageID:指向上一页的ID。如果指向一个uint的最大值(4294967295)即表示没有上一页。
NextPageID:指向下一页的ID。如果指向一个uint的最大值(4294967295)即表示没有页一页。从这里看页的结构有点像双向链表,但在实际存储中,页与页之间貌似并不是以链表形式存储(可能我这里也没太搞明白这两个ID的具体作用)。
PageType:一个页类型的枚举,根据这个枚举,可以将BasePage强制转换成相对应的页类型。
ItemCount:一个用于计算页中的特定数据大小的ItemCount,在DataPage和IndexPage中可以看到它的作用。
IsDirty:从名称我们可以大概猜出它的作用,在LiteDB中专门用来标记该页的数据是否完成Commit操作。
FreeBytes:这个属性需要各个子类重写,用于计算该页还有多少可用的字节。
1.2 CollectionPage
一个CollectionPage就代表一张表,比如数据库中有Customer和Order两张表,那么在数据库中就存在两个CollectionPage分别存储这两张表的信息。CollectionPage之间用 Prev/Next 连接。
CollectionPage中有一个CollectionName代表了该表的名称,比如Customer和Order两张表就有两个名称分别为“Customer“和“Order”。DocumentCount属性标志着该表有多少条记录,比如向Customer表插入100条数据,那么DocumentCount就为100。
CollectionPage里面最主要的一个属性Indexes,这是一个自定义结构体CollectionIndex的数组,它代表了该表中的所有索引名称。比如Customer表中有三个字段分别“ID”、“Name”、“Age”,(特别强调,这三个字段都要作为索引)那么Indexes数组就分别包含了这三个字段。同时可以看到这个页中有个叫PK的属性,根据名称我们大致就知道它肯定是主键,比如上面Customer表中的“ID”。
1.3 HeaderPage
HeaderPage存储了当前使用的LiteDB数据库的一些信息,包括头文件,数据库版本,可用的空余页ID,用户版本等。其中有个名为ChangeID的属性,这个是用于处理事务时,验证客户端中的ChangeID是否一致。
1.4 DataPage
DataPage就是数据页,它的结构最简单,除了父类之外只包含一个名为DataBlocks的字典,这个字典Key是一个ushort数字,Value是一个DataBlock类。后面我们通过分析DataBlock这个结构体就大致能知道DataPage的作用。同时在数据页中还可以看到它重写FreeBytes属性就是可用字节减去字典长度,ItemCount就等于字典长度。
1.5 ExtendPage
ExtendPage是数据扩展页,如果插入的数据过大时,就讲超过Page的数据块放入ExtendPage中的Data中,同样它重写FreeBytes属性就是可用字节减去Data的长度。
1.6 IndexPage
IndexPage就是索引页,它的结构和DataPage类似,只包含了一个名为Nodes的字典,这个字典中key是一个ushort数字,Value是一个IndexNode类,索引使用跳表的形式进行存储。
2. 数据可视化——掀开Page的面纱
可能看完上面说明,你可能对数据页仍然是一头雾水,我在看源码的时候也是如此。后来经过我各种努力,想出了 一个办法,就是将页的信息实时展示出来,也就是常说的数据可视化。后面我会专门介绍如何把数据页的信息展示出来,这里大家先跟着往下看。
首先我们先创建一个数据库:
LiteEngine db = new LiteEngine(Path);
下面我用winfrom做的界面,Header下面的列表就表示所有的HeaderPage信息,其他也类似。由于ExtendPage功能比较简单,所以没把ExtendPage的信息展示出来。在执行完这条命令后,界面中就可以看到有两个页被创建了:

我们可以看到HeaderPage和CollectionPage各创建一页,HeaderPage因为是要存放数据库的信息,所以在数据库一被创建就有且只有一页,后面再添加新的表,HeadPage也只有这一页。CollectionPage为什么会有一条呢,看它的表名称,你就知道了,master表,是不是很熟悉?没错,和Sqlserver数据库的系统数据库类似,只不过我确实看不出来LiteDB里面的这张master表作用。

然后我们在添加一张名为customer的表,字段分别是ID,Age,Name,Address。即执行下面一段话:
var col = db.GetCollection<Customer>("customer");
col.EnsureIndex("Age");//确定Age字段为索引
col.EnsureIndex("Name");//确定Name字段为索引
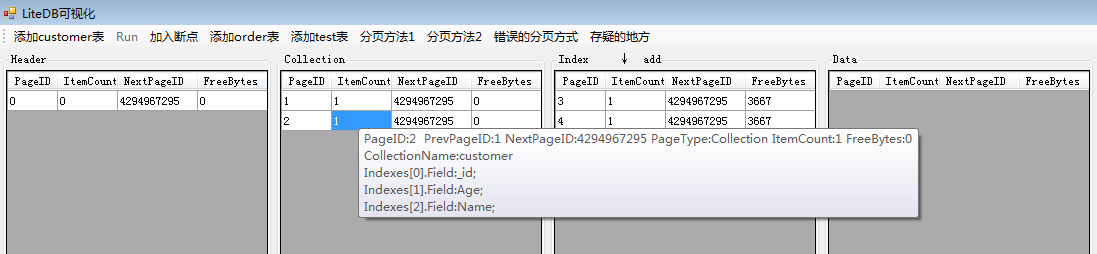
执行完之后,我们可以看见有CollectionPage中有一个新表被创建,它的表名为customer,这个page中有三个表索引,分别就是默认的ID主键,然后是Age和Name,注意字段Address并没有添加进去。
IndexPage增加了三页,每页对应一个索引,同时页里面只有一个索引节点(IndexNode)。DataPage数据页目前还是空的。我们再插入3条记录,执行语句如下:
for (int i = ; i < ; i++)
{
var customer = new Customer
{
Id = i,
Name=i%==?"Jim1_"+i.ToString():"Jim2_"+i.ToString(),
Age = i*,
Address = "Dump"
}
col.Insert(customer);
}
然后我们就能够看到每个索引页多了三个索引节点,同时数据页也创建了一页。最后我们再添加两张表,一张Order表字段为ID,Ordersum。另一张Product表为Id,ProductName和ProductPrice。两张表的字段全都设成索引,数据页结构如下:

从上面的可以清楚看到,每添加一张表,就会创建一个CollectionPage页,向表里添加数据的同时,如果有索引添加,那么IndexPage页里相应内容也会添加。把上面图中数据再详细绘制出来就是下面这个结构:
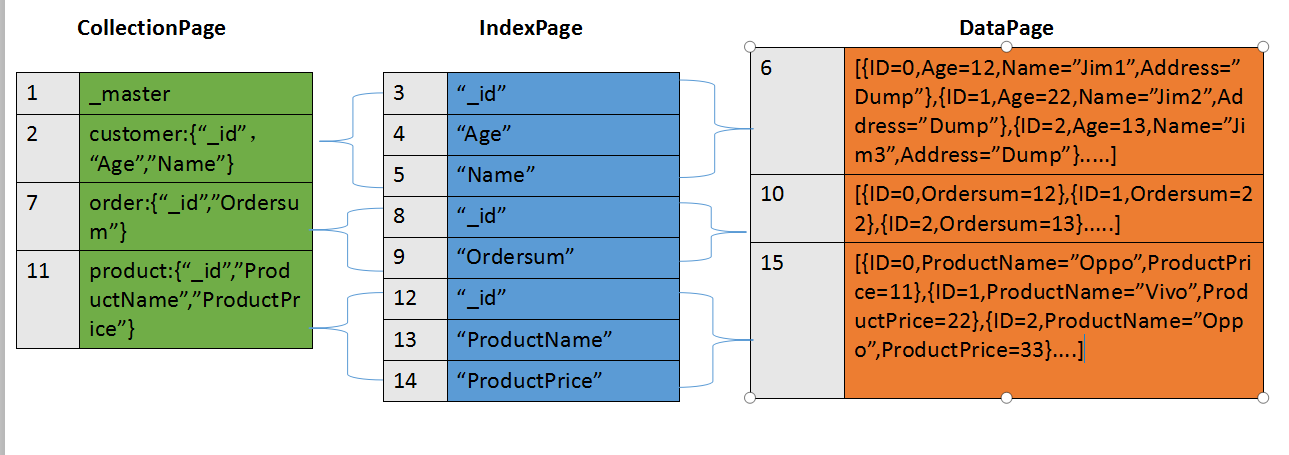
从这张图,大家应该很容易就看懂这几种页类型的作用。注意当前0.0.8版本的ID要指定为BsonID,在内部会改为"_id",这也是这个版本在某些地方出bug的原因。同时DataPage里面存的数据并不是图上面的json格式而是Byte数组。
3.后面的话
这章博客写完,我才知道想把一件事情说明白真是不容易,况且是比较复杂的源码。相信我会坚持更新,也希望能与看我博客的各位大神多多交流。
LiteDB源码解析系列(2)数据库页详解的更多相关文章
- gulp源码解析(一)—— Stream详解
作为前端,我们常常会和 Stream 有着频繁的接触.比如使用 gulp 对项目进行构建的时候,我们会使用 gulp.src 接口将匹配到的文件转为 stream(流)的形式,再通过 .pipe() ...
- LiteDB源码解析系列(1)LiteDB介绍
最近利用端午假期,我把LiteDB的源码仔细的阅读了一遍,酣畅淋漓,确实收获了不少.后面将编写一系列关于LteDB的文章分享给大家,希望这么好的源码不要被埋没. 1.LiteDB是什么 这是一个小型的 ...
- LiteDB源码解析系列(4)跳表基本原理
LitDB里面索引的数据结构是用跳表来实现的,我知道的开源项目中使用跳表的还包括Redis,大家可以上网搜索关于Redis的跳表功能的实现.在这一章,我将结合LiteDB中的示例来讲解跳表. 1.跳表 ...
- Linux源码解析-内核栈与thread_info结构详解
1.什么是进程的内核栈? 在内核态(比如应用进程执行系统调用)时,进程运行需要自己的堆栈信息(不是原用户空间中的栈),而是使用内核空间中的栈,这个栈就是进程的内核栈 2.进程的内核栈在计算机中是如何描 ...
- Spring源码解析--IOC根容器Beanfactory详解
BeanFactory和FactoryBean的联系和区别 BeanFactory是整个Spring容器的根容器,里面描述了在所有的子类或子接口当中对容器的处理原则和职责,包括生命周期的一些约定. F ...
- LiteDB源码解析系列(3)索引原理详解
在这一章,我们将了解LiteDB里面几个基本数据结构包括索引结构和数据块结构,我也会试着说明前辈数据之巅在博客中遇到的问题,最后对比mysql进一步深入了解LiteDB的索引原理. 1.LiteDB的 ...
- axios 源码解析(下) 拦截器的详解
axios的除了初始化配置外,其它有用的应该就是拦截器了,拦截器分为请求拦截器和响应拦截器两种: 请求拦截器 ;在请求发送前进行一些操作,例如在每个请求体里加上token,统一做了处理如果以后要 ...
- hanlp源码解析之中文分词算法详解
词图 词图指的是句子中所有词可能构成的图.如果一个词A的下一个词可能是B的话,那么A和B之间具有一条路径E(A,B).一个词可能有多个后续,同时也可能有多个前驱,它们构成的图我称作词图. 需要稀疏2维 ...
- AngularJS源码解析2:注入器的详解
上一课,没有讲createInjector方法,只是讲了它的主要作用,这一课,详细来讲一下这个方法.此方法,最终返回的注册器实例对象有以下几个方法: invoke, instantiate, get, ...
随机推荐
- QT Udp组播(穿透)
http://blog.csdn.net/victoryknight/article/details/7814243 主题 UDPQt路由器 局域网内的两台机器如果隔有路由器,那么这两台机器之间不 ...
- 怎么看待php 面向对象思想
面向对象的程序设计思路是现代程序设计由面向过程演变面向对象的必然趋势,所以面向对象的而设计思路必然有它不同的时代意义,必然有着不同面向过程的不同历史使命,而php 5以后成功添加面向对象的设计思路其实 ...
- Python基础(六) 函数
.函数 函数是对动作的封装 2.1函数的基本结构 #函数的定义 def 函数名(): #函数提 pass #函数的执行 函数名() 2.2参数初识 #形参 def hanshu(aaa): #参数相当 ...
- mysql查询类型转换问题
mysql转换类型.类型转换.查询结果类型转换 一.问题来源 数据库一张表的主键id设为了自增,那就是int型的,但是其他表的关联字段又设置成了字符串! 而且已经开发了很久才发现问题,既然出现了问题肯 ...
- 09 Javascript的伪数组 arguments
arguments代表的是实参.有个讲究的地方是:arguments只在函数中使用. (1)返回函数实参的个数:arguments.length 例子: fn(2,4); fn(2,4,6); fn( ...
- ASP.NET MVC/Core表单提交后台模型二级属性验证问题
起因 这个是网友在官网论坛的提问:https://fineui.com/bbs/forum.php?mod=viewthread&tid=22237 重新问题 本着务实求真的态度,我们先来复现 ...
- .Net将集合M内非空参数值的参数按照参数名ASCII码从小到大排序(字典序),并使用URL键值对的格式(即key1=value1&key2=value2…)拼接成字符串stringA
前言: 前段时间因为项目进度比较繁重所以一直都没有时间更新博客,内心深深的负重感,没有履行年初立下的flag.不过这个月会把上个月没有完成的任务补上来,咱们可不是喜欢拖欠任务的攻城狮.哈哈,废话不多说 ...
- mybatis以及预编译如何防止SQL注入
SQL注入是一种代码注入技术,用于攻击数据驱动的应用,恶意的SQL语句被插入到执行的实体字段中(例如,为了转储数据库内容给攻击者).[摘自] SQL injection - Wikipedia SQL ...
- tensorflow 离线使用 fashion_mnist 数据集
在tensflow中加载 fashion_mnist 数据集时,由于网络原因.可能会长时间加载不到或报错 此时我们可以通过离线的方式加载 1.首先下载数据集:fashion_mnist (下载后解压) ...
- 02-三种Bean装配机制(一)
Spring要创建哪些bean并且如何将其装配在一起,现有的,主要是三种装配机制: 自动化装配 通过java代码装配 通过XML装配 这三种装配机制可以互相搭配使用,即是可以共存的.接下来就分别介绍啦