LiteDB源码解析系列(3)索引原理详解
在这一章,我们将了解LiteDB里面几个基本数据结构包括索引结构和数据块结构,我也会试着说明前辈数据之巅在博客中遇到的问题,最后对比mysql进一步深入了解LiteDB的索引原理。
1.LiteDB的五种基本数据结构
在LiteDB的Structures中定义了五个基本数据结构,分别为PageAddress、CollectionIndex、DataBlock、IndexNode和IndexKey。他们各自说明如下:
1.1 PageAddress
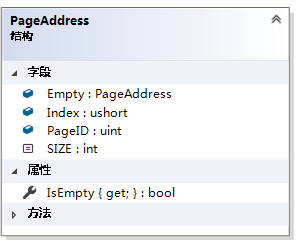
页地址,代表一个数据在页的位置。其中的PageID就是页的ID,Index是数据页或者索引页中字典的key值。根据页的ID和字典key值,就可以找到相应的IndexNode或者DataBlock。将PageID=uint.MaxValue和Index= ushort.MaxValue的页地址作为空页。
1.2 CollectionIndex
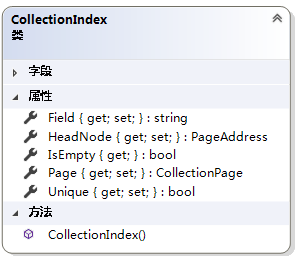
表索引,类似于mysql将表的字段设置为一个索引。属性Field表示存入的字段名称,属性Unique用于标识是否是非重复字段。
1.3 DataBlock
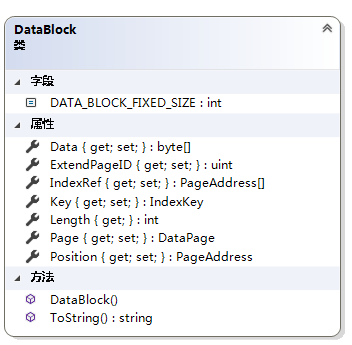
数据块,这个类中Position就是存放在DataPage中的字典索引,比如一个Customer{ID=1,Name=“Jim1”,age=100},将这条记录处理成byte数组也就是属性Data,将该数据块存进DataPage中的字典中,在放入字典的同时,将生成一个key值。DataPage的PageID和字典的key值就作为这个数据块的Position。
IndexRef是一个页地址数组,存储的是索引页的位置。ExtendPageID是指扩展页的ID。Key是这条记录的主键。
1.4 IndexKey

索引键值,这个结构体实现了IComparable接口,主要完成的作用就是将常见的数据类型比如int、byte、string、DateTime转换为统一一个数据类型,然后进行比较。
1.5 IndexNode
索引节点,用来存储一条记录的索引。索引节点之间用跳表来组成数据结构。
注意:属性Position是存放在IndexPage中的字典索引,而DataBlock是存放在DataPage页中字典索。属性Prev和Next分别是指向上一个和下一个节点的IndexPage页地址数组。

2. 举例说明
下面用一个示例来说明索引页、数据页和数据块之间的关系,我创建一个"customer"的表,字段为{“Id”,"Age","Name",},然后插入10记录:{Id=1,Age=1,Name="Jim_1"},{Id=2,Age=2,Name="Jim_2"}.....{Id=10,Age=10,Name="Jim_10"}。大家可以看一下当前的数据展示如下:

从上面可以清楚看到IndexPage里面的IndexNode是有序排列。我们学过排序算法肯定都知道,要想实现排序,必须有比较对象。所以Key就要实现一个IComparable接口,这样所有的IndexNode就可以通过他们的Key值进行排序。对IndexNode的增删改查是用跳表这种数据结构,后面有机会我会专门结合LiteDB讲一下跳表这种数据结构。同时要注意的是IndexNode的链接有Next和Prev,我这里为了简略,只绘制出Next的链接。
我们能看到目前只有一页DataPage,这页DataPage的ItemCount是10,正好对应了10条数据。我再用PPT的模式将IndexNode,DataBlock的关系描述如下:
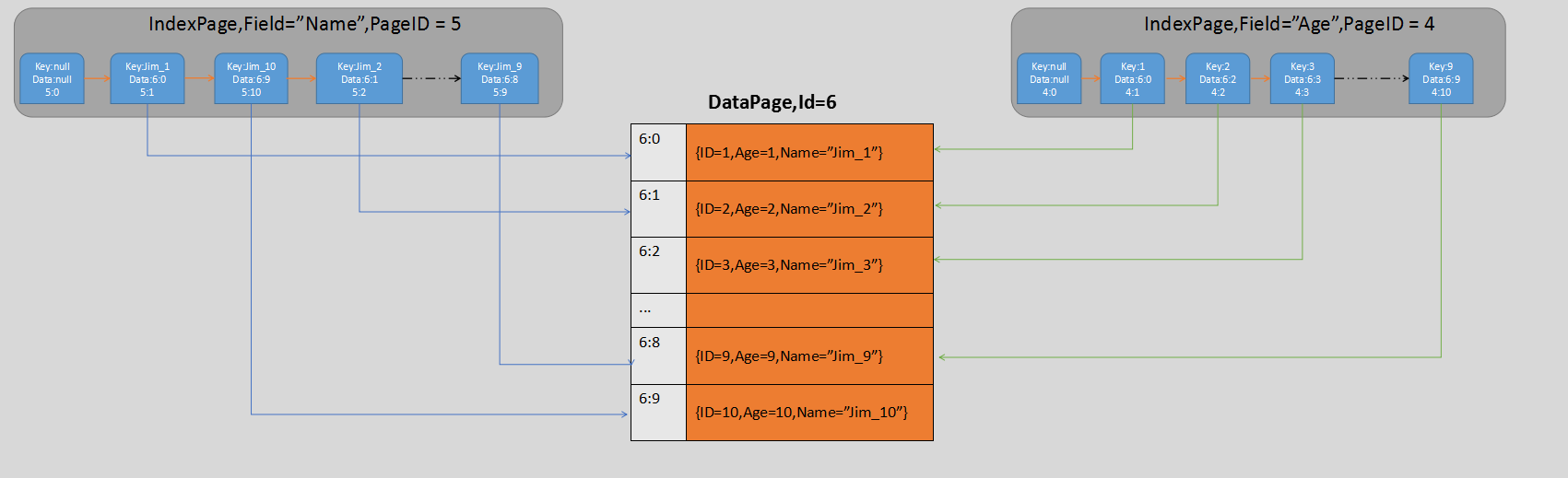
上面这张图就将IndexNode和DataBlock之间关系描述出来了,两个不同的IndexPage中的索引节点指向的是同一个DataPage中的DataBlock。同时请各位注意的是,由于插入的Age是数值,Name是字符串,所以他们各自在索引页里面的排列顺序肯定是不一样的。
3.针对博主数据之巅的疑问
博主数据之巅在分页问题上做了一些尝试,尝试过程中遇到了查询出来的数据ID并不是按顺序排列的问题,我这里截图如下:
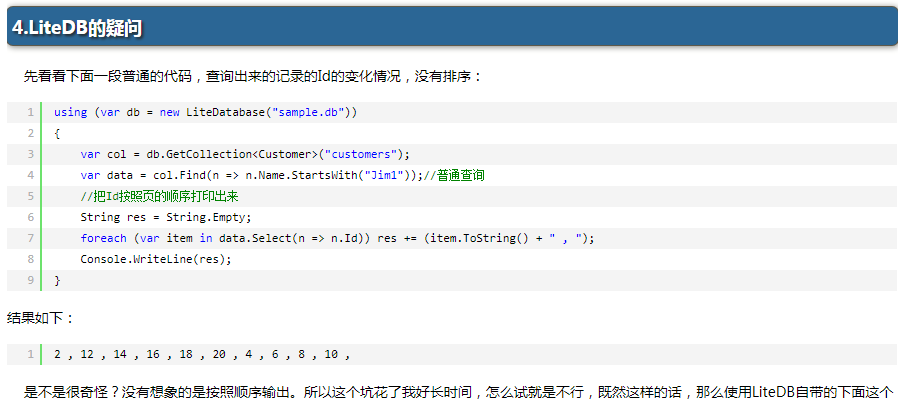
为什么查询出来的ID没有按序排列,这是因为执行n.Name.StartWith("Jim1")的linq语句时,LiteDB就从Field为Name的IndexPage中进行查询,这个IndexPage中的Key装的是字符串变量,那么进行比较的也是字符串。做个简单实验我们就能知道“Jim_1”<"Jim_11"<"Jim_2",这样索引对应的数据查询出来的id就是1,11,2这种顺序了。
4.对比Mysql
如果大家对mysql的索引稍微有些了解的话,应该知道mysql的索引数据结构使用的是B+树,mysql有两种主要的存储引擎叫做InnoDB和MyISM(下面内容转自博客https://www.cnblogs.com/shijingxiang/articles/4743324.html)。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISAM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
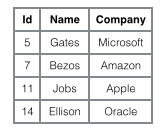
一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。
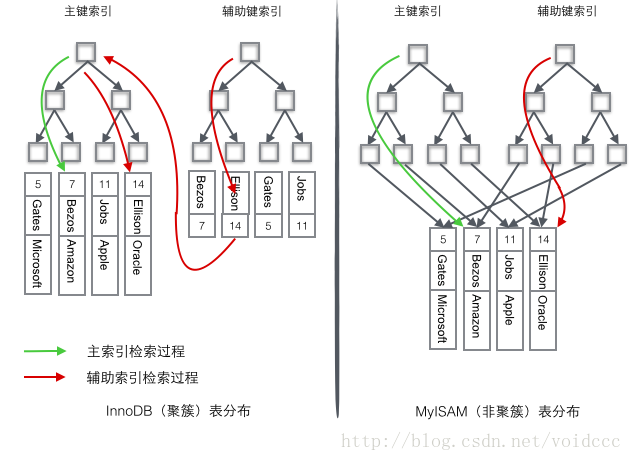
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
最后我们可以看到LiteDB的索引方式和MyISAM类似,不管是主键索引还是辅助索引指向的是数据的地址,只不过LiteDB索引内部是用跳表,而mysql用的是B+树。
LiteDB源码解析系列(3)索引原理详解的更多相关文章
- gulp源码解析(一)—— Stream详解
作为前端,我们常常会和 Stream 有着频繁的接触.比如使用 gulp 对项目进行构建的时候,我们会使用 gulp.src 接口将匹配到的文件转为 stream(流)的形式,再通过 .pipe() ...
- LiteDB源码解析系列(1)LiteDB介绍
最近利用端午假期,我把LiteDB的源码仔细的阅读了一遍,酣畅淋漓,确实收获了不少.后面将编写一系列关于LteDB的文章分享给大家,希望这么好的源码不要被埋没. 1.LiteDB是什么 这是一个小型的 ...
- LiteDB源码解析系列(4)跳表基本原理
LitDB里面索引的数据结构是用跳表来实现的,我知道的开源项目中使用跳表的还包括Redis,大家可以上网搜索关于Redis的跳表功能的实现.在这一章,我将结合LiteDB中的示例来讲解跳表. 1.跳表 ...
- LiteDB源码解析系列(2)数据库页详解
在这一篇里,我将用图文的方式展示LiteDB中页的结构及作用,内容都是原创,在描述的过程中有不准确的地方烦请指出. 1.LiteDB页的技术工作原理 LiteDB虽然是单个文件类型的数据库,但是数据库 ...
- tensorflow源码解析系列文章索引
文章索引 framework解析 resource allocator tensor op node kernel graph device function shape_inference 拾遗 c ...
- Linux源码解析-内核栈与thread_info结构详解
1.什么是进程的内核栈? 在内核态(比如应用进程执行系统调用)时,进程运行需要自己的堆栈信息(不是原用户空间中的栈),而是使用内核空间中的栈,这个栈就是进程的内核栈 2.进程的内核栈在计算机中是如何描 ...
- Spring源码解析--IOC根容器Beanfactory详解
BeanFactory和FactoryBean的联系和区别 BeanFactory是整个Spring容器的根容器,里面描述了在所有的子类或子接口当中对容器的处理原则和职责,包括生命周期的一些约定. F ...
- axios 源码解析(下) 拦截器的详解
axios的除了初始化配置外,其它有用的应该就是拦截器了,拦截器分为请求拦截器和响应拦截器两种: 请求拦截器 ;在请求发送前进行一些操作,例如在每个请求体里加上token,统一做了处理如果以后要 ...
- hanlp源码解析之中文分词算法详解
词图 词图指的是句子中所有词可能构成的图.如果一个词A的下一个词可能是B的话,那么A和B之间具有一条路径E(A,B).一个词可能有多个后续,同时也可能有多个前驱,它们构成的图我称作词图. 需要稀疏2维 ...
随机推荐
- 国外优秀的UI设计资源库收集
国外优秀的UI设计资源库 网站设计或者说UI设计对于Web上的运用是非常的关键,一个站做得好不好,能不能吸引人的眼球,设计占了不低的地位,但话又说回来,Web前端人员又有多少人是设计专业毕业,具有这方 ...
- SpringBoot整合Redis注意的一些问题
1:ERR value is not an integer or out of range 1-1:背景 使用redisTemplate.opsForValue().increment(key, de ...
- hadoop之hive集合数据类型
除了string,boolean,date等基本数据类型之外,hive还支持三种高级数据类型: 1.ARRAY ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问.比如有一个A ...
- Storm 学习之路(六)—— Storm项目三种打包方式对比分析
一.简介 在将Storm Topology提交到服务器集群运行时,需要先将项目进行打包.本文主要对比分析各种打包方式,并将打包过程中需要注意的事项进行说明.主要打包方式有以下三种: 第一种:不加任何插 ...
- 正则RegExp对象的用法
RegExp实例方法: 1.Test() RegExpObject.test(string) 判断string中是否有与表达式匹配的字符串,有则返回true,否则返回false 例如 var patt ...
- Redis Ubuntu 安装
1.使用 root 用户登录 Ubuntu 2. wget http://download.redis.io/releases/redis-5.0.3.tar.gz 下载最新的稳定版本到 redis ...
- KVM web管理工具——WebVirtMgr
系统环境: [root@kvm-admin ~]# cat /etc/redhat-release CentOS Linux release (Core) 关闭防火墙.selinux [root@kv ...
- 自己挖的坑跪着也要填完---mapper配置文件和java源文件在同一包下
本来准备研究下mybatis源码执行流程的,就随意搭建了个项目,所有配置如下: 一切看似都是那么的正常,然而执行的时候:Exception in thread "main" org ...
- Python 3网络爬虫开发实战中文 书籍软件包(原创)
Python 3网络爬虫开发实战中文 书籍软件包(原创) 本书书籍软件包为本人原创,想学爬虫的朋友你们的福利来了.软件包包含了该书籍所需的所有软件. 因为软件导致这个文件比较大,所以百度网盘没有加速的 ...
- Javascript中escape(), encodeURI()和encodeURIComponent()之精析与比较
escape(), encodeURI()和encodeURIComponent()是在Javascript中用于编码字符串的三个常用的方法,而他们之间的异同却困扰了很多的Javascript初学者, ...