影响ES相关度算分的因素
影响ES相关度算分的因素的更多相关文章
- ElasticStack学习(九):深入ElasticSearch搜索之词项、全文本、结构化搜索及相关性算分
一.基于词项与全文的搜索 1.词项 Term(词项)是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term. Term的使用说明: 1)Term Level Query:Ter ...
- Elasticsearch从入门到放弃:浅谈算分
今天来聊一个 Elasticsearch 的另一个关键概念--相关性算分.在查询 API 的结果中,我们经常会看到 _score 这个字段,它就是用来表示相关性算分的字段,而相关性就是描述一个文档和查 ...
- Lucene TF-IDF 相关性算分公式(转)
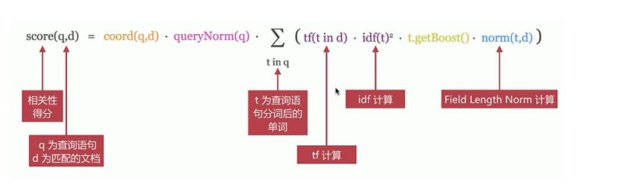
Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF-IDF是一种统计方法,或者被称为向量空间模型,名字听起来很 ...
- 影响pogo pin连接器使用寿命的因素
精细化.安装简易化及使用寿命长是现在数码电子产品的趋势发展,pogo pin连接器体积小而且弹簧伸缩式设计,可以更好的缩小数码电子产品的尺寸并且连接安装更加的简单方便,因此pogo pin连接器得到了 ...
- Solr相似度算法一:Lucene TF-IDF 相关性算分公式
Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF-IDF是一种统计方法,或者被称为向量空间模型,名字听起来很 ...
- Lucene TF-IDF 相关性算分公式
转自: http://lutaf.com/210.htm Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF- ...
- RTMP服务器的延迟,多级边缘不影响延迟,gop为最大因素
转自:http://blog.chinaunix.net/uid-26000296-id-4932826.html 编码器用FMLE,用手机秒表作为延迟计算. 结论: 1. 影响延迟的三个重要因素:网 ...
- UnixBench算分介绍
关于如何用UnixBench,介绍文章很多,这里就不展开了.这里重点描述下它是如何算分的. 运行参数 碰到很多客户,装好后,直接./Run,就把结果跑出来了,然后还只取最后一个分值,比谁高谁低.下面列 ...
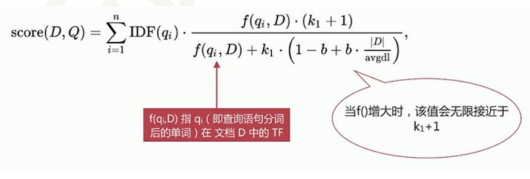
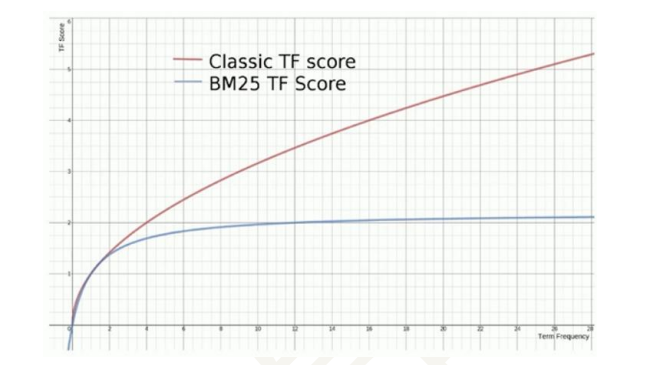
- Elasticsearch BM25相关度算法超详细解释
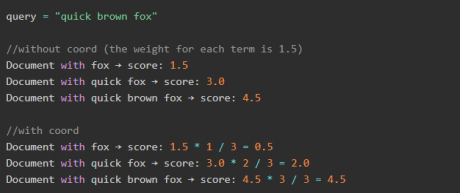
Photo by Pixabay from Pexels 前言:日常在使用Elasticsearch的搜索业务中多少会出现几次 "为什么这个Doc分数要比那个要稍微低一点?".&q ...
随机推荐
- LogBack.xml文件配置
Logback-spring.xml配置文件 1.日志级别:日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL, ...
- 从函数计算架构看 Serverless 的演进与思考
作者 | 杨皓然 阿里巴巴高级技术专家 导读:云计算之所以能够成为 DT 时代颠覆性力量,是因为其本质是打破传统架构模式.降低成本并简化体系结构,用全新的思维更好的满足了用户需求.而无服务器计算(S ...
- 医生智能提醒小程序数据库设计心得——Legends Never Die
数据库设计心得 根据我们小组数据库设计的整个流程,我们将整个数据库设计划分为两个具体的阶段,在每个阶段需要进行不同的准备,有不同的注意事项,接下来我们将结合在数据库设计过程中遇到的一些问题和困难,提出 ...
- MIT线性代数:22.对角化和A的幂
- Django学习day5——创建app
app应用与project项目的区别 一个app实现某个功能,比如博客.公共档案数据库或者简单的投票系统 一个project是配置文件和多个app的集合,这些app组合成整个站点 一个project可 ...
- CSPS模拟 60
T1 m+logn的约瑟夫 T2 考数学的Bit T3 很裸但就是不会打的LCIS 哭哭. 如果下次还考这种题我一定要想出来.
- NOIP模拟 4
T1没开longlong T2忘了有向... T3是个好题,可以说将复杂度从N^2优化到NlogN是一个质的飞跃 考虑分治(要想出log可不就要分治么!(segtree也行 但我不会) 对于一个分治区 ...
- SSM配置后可以访问静态html文件但无法访问其他后台接口的解决方案
web.xml中的一段 <servlet> <servlet-name>SpringMVC</servlet-name> <servlet-class> ...
- 8行代码批量下载GitHub上的图片
[问题来源] 来打算写一个的小游戏,但是图片都在GitHub仓库中,GitHub网页版又没有批量下载图片的功能,只有单独一张一张的下载,所以自己就写了个爬虫脚本模拟人的操作把整个页面上需要的图片爬取下 ...
- PHP Laravel-包含你自己的帮助函数
你可能想创建一个在应用的任何地方都可以访问的函数,这个教程将帮你实现