影响ES相关度算分的因素
影响ES相关度算分的因素的更多相关文章
- ElasticStack学习(九):深入ElasticSearch搜索之词项、全文本、结构化搜索及相关性算分
一.基于词项与全文的搜索 1.词项 Term(词项)是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term. Term的使用说明: 1)Term Level Query:Ter ...
- Elasticsearch从入门到放弃:浅谈算分
今天来聊一个 Elasticsearch 的另一个关键概念--相关性算分.在查询 API 的结果中,我们经常会看到 _score 这个字段,它就是用来表示相关性算分的字段,而相关性就是描述一个文档和查 ...
- Lucene TF-IDF 相关性算分公式(转)
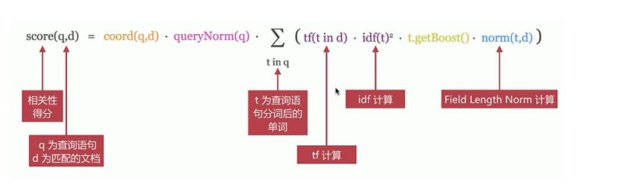
Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF-IDF是一种统计方法,或者被称为向量空间模型,名字听起来很 ...
- 影响pogo pin连接器使用寿命的因素
精细化.安装简易化及使用寿命长是现在数码电子产品的趋势发展,pogo pin连接器体积小而且弹簧伸缩式设计,可以更好的缩小数码电子产品的尺寸并且连接安装更加的简单方便,因此pogo pin连接器得到了 ...
- Solr相似度算法一:Lucene TF-IDF 相关性算分公式
Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF-IDF是一种统计方法,或者被称为向量空间模型,名字听起来很 ...
- Lucene TF-IDF 相关性算分公式
转自: http://lutaf.com/210.htm Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF- ...
- RTMP服务器的延迟,多级边缘不影响延迟,gop为最大因素
转自:http://blog.chinaunix.net/uid-26000296-id-4932826.html 编码器用FMLE,用手机秒表作为延迟计算. 结论: 1. 影响延迟的三个重要因素:网 ...
- UnixBench算分介绍
关于如何用UnixBench,介绍文章很多,这里就不展开了.这里重点描述下它是如何算分的. 运行参数 碰到很多客户,装好后,直接./Run,就把结果跑出来了,然后还只取最后一个分值,比谁高谁低.下面列 ...
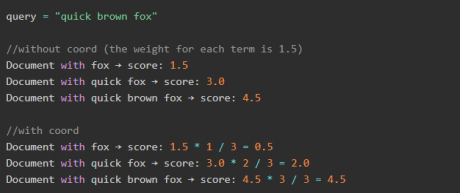
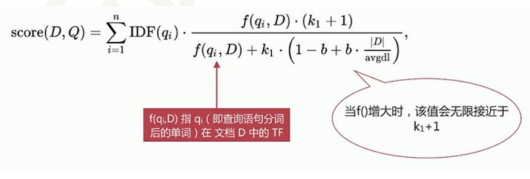
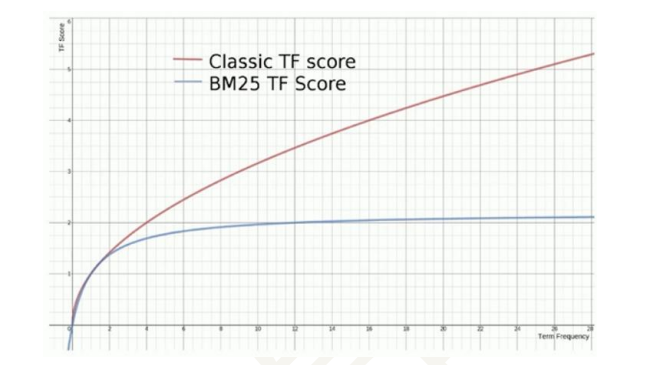
- Elasticsearch BM25相关度算法超详细解释
Photo by Pixabay from Pexels 前言:日常在使用Elasticsearch的搜索业务中多少会出现几次 "为什么这个Doc分数要比那个要稍微低一点?".&q ...
随机推荐
- 6、pytest -- 临时目录和文件
目录 1. 相关的fixture 1.1. tmp_path 1.2. tmp_path_factory 1.3. tmpdir 1.4. tmpdir_factory 1.5. 区别 2. 默认的基 ...
- Spring Boot项目中如何定制servlet-filters
本文首发于个人网站:Spring Boot项目中如何定制servlet-filters 在实际的web应用程序中,经常需要在请求(request)外面增加包装用于:记录调用日志.排除有XSS威胁的字符 ...
- python设置环境变量(临时和永久)
设置临时环境变量 import os # 设置环境变量 os.environ['WORKON_HOME']="value" # 获取环境变量方法1 os.environ.get(' ...
- 【解决】Got permission denied while trying to connect to the Docker daemon socket at......dial unix /var/run/docker.sock: permission denied
>>> 问题:搭建Portainer时,选择本地连接报错? >>>分析: 根据报错信息可知是权限问题. 可能原因一:使用了非root用户启用或连接docker &g ...
- Maven/Docker快速搭建RocketMQ
官方文档 [https://rocketmq.apache.org/docs/quick-start/] ①:Bin_二进制安装版 1. 环境准备 系统环境:Centos7 x64 JDK:jdk-8 ...
- python——掌握sorted函数的用法
看本篇文章的前提是掌握 00函数的基本概念.01函数参数传递方式 可参考本人博客文章 sorted函数 是一个内建函数,接收一个可迭代对象,按照指定类型.指定顺序进行排序,特点是返回一个新的列表,不改 ...
- PHP获取图片每个像素点
PHP获取图片每个像素点<pre> $i = imagecreatefromjpeg("test.jpg"); //图片路径 for ($x = 0; $x < ...
- Hazel,自动整理文件,让你的 Mac 井井有条
原文地址 https://sspai.com/post/35225 让我们从实际需求出发,看看问题出在哪里,并在此基础上认识和学习使用 Hazel. 电脑随着使用时间的增长,其中的文件也在疯狂的增长, ...
- 6.2.2 辅助类GenericOptionsParser,Tool和ToolRunner深入解析
辅助类GenericOptionsParser,Tool和ToolRunner (1)为什么要用ToolRunner 将MapReduce Job配置参数写到java代码里,一旦变更意味着修改java ...
- Spring注解@Configuration是如何被处理的?
从SpringApplication开始 一般情况下启动SpringBoot都是新建一个类包含main方法,然后使用SpringApplication.run来启动程序: @SpringBootApp ...