【python】利用jieba中文分词进行词频统计
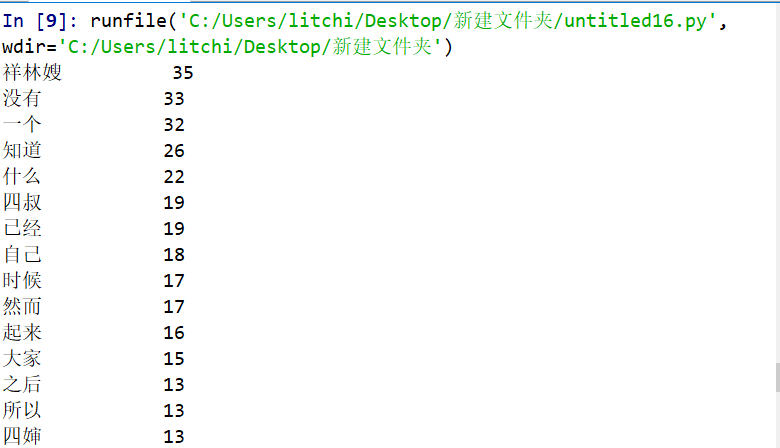
以下代码对鲁迅的《祝福》进行了词频统计:
import io
import jieba
txt = io.open("zhufu.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(15):
word, count = items[i]
print (u"{0:<10}{1:>5}".format(word, count))
结果如下:
并把它生成词云
from wordcloud import WordCloud
import PIL.Image as image
import numpy as np
import jieba # 分词
def trans_CN(text):
# 接收分词的字符串
word_list = jieba.cut(text)
# 分词后在单独个体之间加上空格
result = " ".join(word_list)
return result with open("zhufu.txt") as fp:
text = fp.read()
# print(text)
# 将读取的中文文档进行分词
text = trans_CN(text)
mask = np.array(image.open("xinxing.jpg"))
wordcloud = WordCloud(
# 添加遮罩层
mask=mask,
font_path = "msyh.ttc"
).generate(text)
image_produce = wordcloud.to_image()
image_produce.show()
效果如下:

【python】利用jieba中文分词进行词频统计的更多相关文章
- Python大数据:jieba 中文分词,词频统计
# -*- coding: UTF-8 -*- import sys import numpy as np import pandas as pd import jieba import jieba. ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- python安装Jieba中文分词组件并测试
python安装Jieba中文分词组件 1.下载http://pypi.python.org/pypi/jieba/ 2.解压到解压到python目录下: 3.“win+R”进入cmd:依次输入如下代 ...
- python库--jieba(中文分词)
import jieba 精确模式,试图将句子最精确地切开,适合文本分析:全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义:搜索引擎模式,在精确模式的基础上,对长词再次切 ...
- 【python】一篇文章里的词频统计
一.环境 1.python3.6 2.windows系统 3.安装第三方模块 pip install wordcloud #词云展示库 pip install jieba #结巴分词 pip inst ...
- jieba中文分词
jieba中文分词¶ 中文与拉丁语言不同,不是以空格分开每个有意义的词,在我们处理自然语言处理的时候,大部分情况下,词汇是对句子和文章的理解基础.因此需要一个工具去把完整的中文分解成词. ji ...
- python利用jieba进行中文分词去停用词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词. 分词模块jieba,它是python比较好用的分词模块.待分词的字符串可以是 unicod ...
- jieba中文分词(python)
问题小结 1.安装 需要用到python,根据python2.7选择适当的安装包.先下载http://pypi.python.org/pypi/jieba/ ,解压后运行python setup.py ...
- Python分词模块推荐:jieba中文分词
一.结巴中文分词采用的算法 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合对于未登录词,采 ...
随机推荐
- [BUG]excel复制到input含有不可见内容(零宽字符)
现象 excel手机号复制到input框子, length长度和可见长度不一致. "176xxxx1115" 长度是 13 而不是 11. 原因 手机号前后被 excel 插入 ...
- Java注解 看这一篇就够了
注解 1.概念 注解:说明程序的.给计算机看的 注释:用文字描述程序的.给程序员看的 注解的定义:注解(Annotation),也叫元数据.一种代码级别的说明.它是JDK1.5及以后版本引入的一个特性 ...
- oracle --游标详解(转)
转自:http://blog.csdn.net/liyong199012/article/details/8948952 游标的概念: 游标是SQL的一个内存工作区,由系统或用户以变量的形式定 ...
- 2. weddriver的定位方法
一. find_element_by_****的方式 首页在网页上鼠标右键选择检查并点击,查看需要定位的元素. https://www.baidu.com 以百度为例 导入模块的: from sel ...
- cmdb采集数据的版本
在局部配置文件中配置MODE=' agent',或者MODE=‘ssh’,或者MODE=‘’saltstack ', 实现只需要修改这个配置,就会使用对应的方案进行采集数据 第一种版本: 启动文件中 ...
- Hive分析窗口函数
数据准备 CREATE EXTERNAL TABLE lxw1234 ( cookieid string, createtime string, --day pv INT ) ROW FORMAT D ...
- mysql之日志
我是李福春,我在准备面试,今天的题目是: mysql的redolog和binlog有什么区别? 答: 如下面的表格, redolog vs binlog 然后我们扩展一下,因为日志主要是记录的修改日志 ...
- Python python对象 range
""" range(stop) -> range object range(start, stop[, step]) -> range object Retu ...
- Python第十一章-常用的核心模块04-datetime模块
python 自称 "Batteries included"(自带电池, 自备干粮?), 就是因为他提供了很多内置的模块, 使用这些模块无需安装和配置即可使用. 本章主要介绍 py ...
- SpringBoot常见注解的解释
@Component 这个注解类似SSM中的Controller和Service注解 ,将加了这个注解的类装配到Sping容器内,这样就可以在其他类用@Autowired注解实现依赖注入. @Conf ...