入门大数据---Hbase搭建
环境介绍
| tuge1 | tuge2 | tuge3 | tuge4 |
|---|---|---|---|
| NameNode | NameNode | DataNode | DataNode |
| ZooKeeper | ZooKeeper | ZooKeeper | ZooKeeper |
| JournalNode | JournalNode | JournalNode | |
| ZKFC | ZKFC | ||
| HMaster | HMaster/HRegionServer | HRegionServer | HRegionServer |
HBase 1.3.6
Hadoop 2.6.5
ZooKeeper 3.5.5
Java JDK 7
从官网可知兼容性:
Java的兼容性:
| HBase版本 | JDK 7 | JDK 8 | JDK 9(非LTS) | JDK 10(非LTS) | JDK 11 |
|---|---|---|---|---|---|
| 2.1+ | × | √ | HBASE-20264 | HBASE-20264 | HBASE-21110 |
| 1.3+ | √ | × | HBASE-20264 | HBASE-20264 | HBASE-21110 |
Hadoop的兼容性:
| HBase-1.3.x | HBase-1.4.x | HBase-1.5.x | HBase-2.1.x | HBase-2.2.x | |
|---|---|---|---|---|---|
| Hadoop-2.4.x | √ | × | × | × | × |
| Hadoop-2.5.x | √ | × | × | × | × |
| Hadoop-2.6.0 | × | × | × | × | × |
| Hadoop-2.6.1 + | √ | × | × | × | × |
| Hadoop-2.7.0 | × | × | × | × | × |
| Hadoop-2.7.1以上 | √ | √ | × | √ | × |
| Hadoop-2.8。[0-2] | × | × | × | × | × |
| Hadoop-2.8。[3-4] | ! | ! | × | √ | × |
| Hadoop-2.8.5 + | ! | ! | √ | √ | √ |
| Hadoop-2.9。[0-1] | × | × | × | × | × |
| Hadoop-2.9.2 + | ! | ! | √ | ! | √ |
| Hadoop-3.0。[0-2] | × | × | × | × | × |
| Hadoop-3.0.3 + | × | × | × | √ | × |
| Hadoop-3.1.0 | × | × | × | × | × |
| Hadoop-3.1.1 + | × | × | × | √ | √ |
注意事项:(这里不配置的化,会导致HMaster总是宕机)
tuge1和tuge2作为HMaster服务器,需要设置tuge1对tuge2,tuge3,tuge4免密钥
设置tuge2对tuge1,tuge3,tuge4免密钥
设置举例:
ssh-keygen -t rsa
ssh-copy-id tuge1
HBase搭建
前提:已经搭建完HDFS和ZooKeeper环境。
我这里在之前搭建的基础上继续操作。
1. 下载HBase安装包
- 在/opt/下面新建hbase文件夹
cd /opt
mkdir hbase
cd hbase
- 下载
wget http://mirror.bit.edu.cn/apache/hbase/hbase-1.3.6/hbase-1.3.6-bin.tar.gz
- 解压
tar -xvf hbase-1.3.6-bin.tar.gz
2. 配置环境变量
vim /etc/profile
添加如下内容:
export JAVA_HOME=/opt/java/jdk1.8.0_221
export HADOOP_HDFS_HOME=/opt/hadoop/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HDFS_HOME/etc/hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-2.6.5
export ZK_HOME=/opt/zookeeper/apache-zookeeper-3.5.5-bin
export HIVE_HOME=/opt/hive/apache-hive-1.2.2-bin
export HBASE_HOME=/opt/hbase/hbase-1.3.6 PATH=$JAVA_HOME/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$ZK_HOME/bin:$HIVE_HOME/bin:**$HBASE_HOME/bin**
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH CLASSPATH
3. 配置文件设置
进入到conf里面,开启分布式集群,配置集群地址,配置HMaster备用服务器地址,配置HRegionService地址配置HBase在HDFS中的路径,配置Active Master。设置使用外部环境ZooKeeper,而不是自身ZooKeeper。
- 编辑hbase-site.xml (开启分布式集群,配置集群地址,配置HMaster备用服务器地址。)
<property> <!--配置根路径为HDFS路径-->
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value><!--mycluster和hdfs-site.xml配置对应,要将文件复制到conf下面。-->
</property>
<property><!--HBase根据此路径找到要使用的ZooKeeper-->
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/zookeeper/apache-zookeeper-3.5.5-bin/temp</value>
</property>
<property><!--配置hbase分布式集群-->
<name>hbase.zookeeper.quorum</name>
<value>tuge2,tuge3,tuge4</value>
<description>the pos of zk</description>
</property>
<property><!--允许分布式-->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property><!--配置hbase master主节点-->
<name>hbase.master</name>
<value>tuge1:60000</value>
</property>
- 编辑backup-masters(配置hbase master备机)
vim backup-masters
在里面加入备机名称,以换行符作为区分。我这里只添加了一台 tuge2
- 编辑hbase-env.sh(配置Java路径,禁止HBase使用自带的ZooKeeper)
vim hbase-env.sh
- 在里面设置
export HBASE_MANAGES_ZK=false<!--禁用使用默认的ZooKeeper-->
export JAVA_HOME=/opt/java/jdk1.8.0_221
- 编辑regionservers(配置HRegionServer)
vim regionservers
- 在里面添加regionserver机器,以换行符作为区分,我这里添加了三台
tuge2
tuge3
tuge4
4. 将hdfs-site.xml 文件复制到conf下面
cp /opt/hadoop/hadoop-2.6.5/etc/hadoop/hdfs-site.xml /opt/hbase/hbase-1.3.6/conf/
5. 启动HBase
进入到bin目录下
cd bin
运行
start-hbase.sh
- 如下图所示:
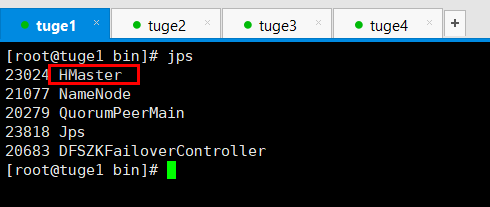
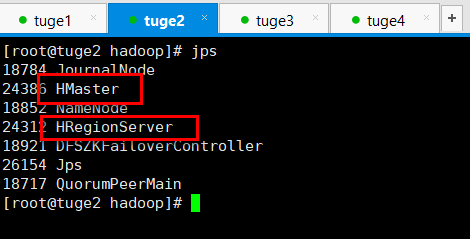
6. 停止HBase
stop-hbase.sh
入门大数据---Hbase搭建的更多相关文章
- 入门大数据---HDFS-HA搭建
一.简述 上一篇了解了Zookeeper和HDFS的一些概念,今天就带大家从头到尾搭建一下,其中遇到的一些坑也顺便记录下. 1.1 搭建的拓扑图如下: 1.2 部署环境:Centos3.1,java1 ...
- 入门大数据---Hbase是什么?
一.Hbase是什么? Hbase属于NoSql的一种. NoSql数据库分为如下几类: Key-Value类型数据库 这类数据库主要会使用到一个哈希表,这个表有一个特定的键和一个指针指向特定的数据. ...
- 入门大数据---Hbase的SQL中间层_Phoenix
一.Phoenix简介 Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据.在 Phoenix 之前,如果你要访问 HBase,只能 ...
- 入门大数据---HBase Shell命令操作
学习方法 可以参考官方文档的简单示例来 点击查看 可以直接在控制台使用help命令查看 例如直接使用help命令: 从上图可以看到,表结构的操作,表数据的操作都展示了.接下来我们可以针对具体的命令使用 ...
- 入门大数据---Hbase 过滤器详解
一.HBase过滤器简介 Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predic ...
- 入门大数据---Hbase协处理器详解
一.简述 Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立"二级索引",难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hbase 中,统计数 ...
- 入门大数据---Hbase容灾与备份
一.前言 本文主要介绍 Hbase 常用的三种简单的容灾备份方案,即CopyTable.Export/Import.Snapshot.分别介绍如下: 二.CopyTable 2.1 简介 CopyTa ...
- 入门大数据---Storm搭建与应用
1.Storm在Linux环境配置 主机名 tuge1 tuge2 tuge3 部署环境 Zookeeper/Nimbus Zookeeper/Supervisor Zookeeper/Supervi ...
- 入门大数据---Elasticsearch搭建与应用
项目版本 构建需要: JDK1.7 Elasticsearch2.2.1 junit4.10 log4j1.2.17 spring-context3.2.0.RELEASE spring-core3. ...
随机推荐
- 2018-ECCV-PNAS-Progressive Neural Architecture Search-论文阅读
PNAS 2018-ECCV-Progressive Neural Architecture Search Johns Hopkins University(霍普金斯大学) && Go ...
- 【docker系列2】docker 的前世今生
Docker 入门,共 3 篇,将带大家进入 Docker 的世界.首先了解 Docker 的发展历程, 然后快速掌握 Docker 的基本使用: Docker 版本及内核兼容性选择是这部分的重点内容 ...
- SpringAOP使用及源码分析(SpringBoot下)
一.SpringAOP应用 先搭建一个SpringBoot项目 <?xml version="1.0" encoding="UTF-8"?> < ...
- Rocket - debug - DebugCustomXbar
https://mp.weixin.qq.com/s/7h9Bdb0x4_clyigMU_0B7Q 讨论DebugCustomXbar中的几个问题. 1. sources/sourceParams n ...
- Python 为什么没有 main 函数?为什么我不推荐写 main 函数?
毫无疑问 Python 中没有所谓的 main 入口函数,但是网上经常看到一些文章提"Python 的 main 函数"."建议写 main 函数"-- 有些人 ...
- ActiveMQ 笔记(七)ActiveMQ的多节点集群
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.Activemq 的集群思想 1.使用Activemq集群的原因 面试题: 引入消息中间件后如何保证 ...
- 企业级Python开发大佬利用网络爬虫技术实现自动发送天气预告邮件
前天小编带大家利用Python网络爬虫采集了天气网的实时信息,今天小编带大家更进一步,将采集到的天气信息直接发送到邮箱,带大家一起嗨~~拓展来说,这个功能放在企业级角度来看,只要我们拥有客户的邮箱,之 ...
- Java实现 LeetCode 148 排序链表
148. 排序链表 在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序. 示例 1: 输入: 4->2->1->3 输出: 1->2->3-> ...
- [C#.NET 拾遗补漏]03:你可能不知道的几种对象初始化方式
阅读本文大概需要 1.2 分钟. 随着 C# 的升级,C# 在语法上对对象的初始化做了不少简化,来看看有没有你不知道的. 数组的初始化 在上一篇罗列数组的小知识的时候,其中也提到了数组的初始化,这时直 ...
- Flask 的请求与响应
flask的请求与响应 from flask import Flask,request,make_response,render_template,redirect app = Flask(__nam ...