轻量化模型:MobileNet v2
MobileNet v2 论文链接:https://arxiv.org/abs/1801.04381
MobileNet v2是对MobileNet v1的改进,也是一个轻量化模型。
关于MobileNet v1的介绍,请看这篇:对MobileNet网络结构的解读
MobileNet v1遗留下的问题
1)结构问题
MobileNet v1的结构非常简单,是一个直筒结构,这种结构的性价比其实不高,后续一系列的ResNet,DenseNet等结构已经证明通过复用图像特征,使用Concat/Eltwise+等操作进行特征融合,能极大提升网络的性价比。
Concat(张量拼接):比如26*26*128,26*26*256经过拼接(Concat)之后得到(26*26*384)
Eltwise有三个操作:product(点乘),sum(相加减)和max(取最大值),其中sum是默认操作
2)Depthwise Convolution的潜在问题
Depthwise Convolution确实是降低了计算量,而在NxN Depthwise + 1x1 Pointwise的结构在性能上也接近NxN Conv。在实际使用中发现,Depthwise的部分kernel比较容易训废掉:训练完之后发现Depthwise训出来的kernel有不少是空的。当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim,加上ReLU的激活影响下,使得神经元输出很容易变为0,所以学废了。ReLU对于0的输出梯度为0,所以一旦陷入0输出,就没法恢复了。我们还发现,这个问题在定点化低精度的时候会进一步放大。
MobileNet v2的创新点
1. Inverted residuals,通常的residuals block(残差块)是先经过1*1的Conv layer,把feature map的通道数"压"下来,再经过3*3Conv layer,最后经过一个1*1的Conv layer,将feature map通道数再"扩展"回去。即先"压缩",最后"扩张"回去。
而Inverted residuals就是先"扩张",最后"压缩",后面会有介绍。
2. Linear bottlenecks,为了避免ReLU对特征的破坏。
MobileNet v2和v1之间的区别
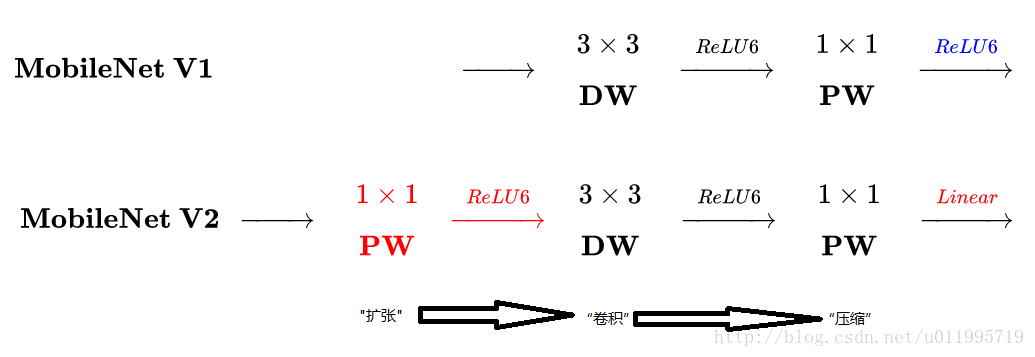
主要是两点:
1. Depthwise convolution之前多了一个1*1的"扩张"层,目的是为了提升通道数,获得更多特征
2. 最后不采用ReLU,而是linear,目的是防止ReLU破坏特征
MobileNet v2的网络结构

其中: t 表示"扩张倍数",c 表示输出通道数,n 表示重复次数,s 表示步长stride
有两点错误:
1. 第五行,也就是第7~10个bottleneck,stride = 2,分辨率应该从28降低到14,如果不是分辨率出错,那就应该是stride=1
2. 文中提到共计采用19个bottleneck,但是这里只有17个
一个bottleneck有如下三个部分组成:

stride = 1和stride = 2,在结构上稍微有点不同。在stride=2时,不采用shortcut。我们对MobileNet v1和MobileNet v2进行比较如下图:

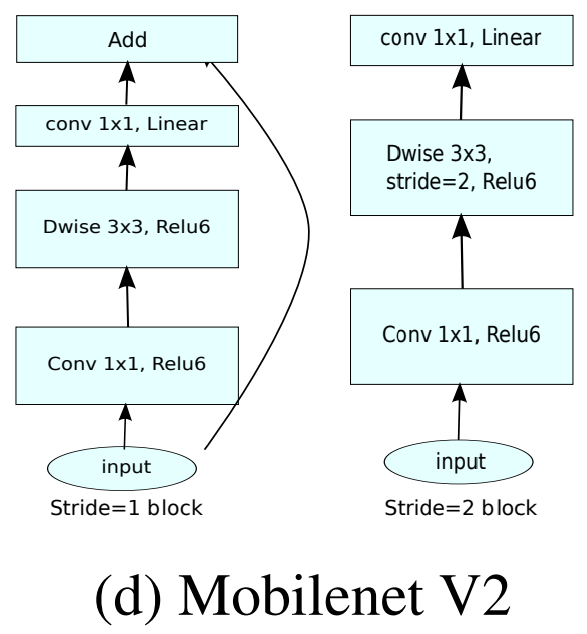
注意:除了最后的avgpool,整个网络并没有采用pooling进行下采样,而是采用stride=2来下采样。
轻量化模型:MobileNet v2的更多相关文章
- 轻量化模型之MobileNet系列
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- CNN结构演变总结(二)轻量化模型
CNN结构演变总结(一)经典模型 导言: 上一篇介绍了经典模型中的结构演变,介绍了设计原理,作用,效果等.在本文,将对轻量化模型进行总结分析. 轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间 ...
- 轻量化模型之SqueezeNet
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 轻量化模型训练加速的思考(Pytorch实现)
0. 引子 在训练轻量化模型时,经常发生的情况就是,明明 GPU 很闲,可速度就是上不去,用了多张卡并行也没有太大改善. 如果什么优化都不做,仅仅是使用nn.DataParallel这个模块,那么实测 ...
- 轻量化模型系列--GhostNet:廉价操作生成更多特征
前言 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络 (CNN) 很困难.特征图中的冗余是那些成功的 CNN 的一个重要特征,但在神经架构设计中很少被研究. 论文提出了一种新颖的 Gh ...
- 卷积神经网络学习笔记——轻量化网络MobileNet系列(V1,V2,V3)
完整代码及其数据,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote 这里结合网络的资料和Mo ...
- 纵览轻量化卷积神经网络:SqueezeNet、MobileNet、ShuffleNet、Xception
近年提出的四个轻量化模型进行学习和对比,四个模型分别是:SqueezeNet.MobileNet.ShuffleNet.Xception. SqueezeNet https://arxiv.org/p ...
- 基于WebGL/Threejs技术的BIM模型轻量化之图元合并
伴随着互联网的发展,从桌面端走向Web端.移动端必然的趋势.互联网技术的兴起极大地改变了我们的娱乐.生活和生产方式.尤其是HTML5/WebGL技术的发展更是在各个行业内引起颠覆性的变化.随着WebG ...
- MobileNet——一种模型轻量化方法
导言 新的CNN网络的提出,提高了模型的学习能力但同时也带来了学习效率的降低的问题(主要体现在模型的存储问题和模型进行预测的速度问题),这使得模型的轻量化逐渐得到重视.轻量化模型设计主要思想在于设计更 ...
随机推荐
- Array(数组)对象-->数组的访问
1.访问数组: 通过指定数组名以及索引号码,你可以访问某个特定的元素. 格式: 数组对象名[下标] 例如:arr[0] 就是访问数组第一个值 var arr = new Array(3); arr[ ...
- logger日志级别
Level 描述 ALL 各级包括自定义级别 DEBUG 指定细粒度信息事件是最有用的应用程序调试 ERROR 错误事件可能仍然允许应用程序继续运行 FATAL 指定非常严重的错误事件,这可能导致应用 ...
- 差分数组&&定义&&使用方法&&与线段树的区别
**1.定义**对于一个有n个元素的数组a[n],我们令a[i]-a[i-1]=d[i],且d[1]=a[1]-0=a[1];那么我们将d[i]称为**差分数组**---即记录数组中的每项元素与前一项 ...
- tf.train.GradientDescentOptimizer 优化器
tf.train.GradientDescentOptimizer(learning_rate, use_locking=False,name='GradientDescent') 参数: learn ...
- git如何清除远程 __pycahce__ 文件
第一步,清除已经存在的缓存文件 >> git rm -r -f --cached */__pycache__ rm 'common/__pycache__/__init__.cpython ...
- java 代码执行cmd 返回值异常 (关于JAVA Project.waitfor()返回值是1)
关于JAVA Project.waitfor()返回值是1 0条评论 Project.waitfor()返回值是1,找了很久从网上没有发现关于1的说明. 这时对源代码调试了一下,发现Project ...
- Java成长第三集--基础重点详细说明
接上篇文章,继续阐述相关的重点基础知识,话不多说! 一.Java中equals()和“==”区别 1.对于8种基础数据类型,使用“=="比较值是否相等: 2.对于复合数据类型(类),使用eq ...
- js使用经验--遍历
目的 在平常的前端开发中,一般需要处理数据(数组和对象居多),特别是复杂功能的页面,通常是一到两个对象数组(有时数组里面还有数组).大多数前端开发的难点就是这里,耗时大.以前我在工作中,遇到的支付方式 ...
- c语言中的引用使用
最近在写一个图像处理的程序时候,遇到一些传参的问题,最后发现引用的效率高一些,在此提醒各位道友,多多关注引用的应用及使用. 1.在引用的使用中,单纯给某个变量取个别名是毫无意义的,不要为了耍酷而乱用, ...
- cucumber学习索引
Cucumber(1) —— 环境配置 Cucumber(2)——目录结构以及基本语法 Cucumber(3)——命令以及日志 Cucumber(4)——jenkins的集成