一篇文章教会你使用Python定时抓取微博评论
【Part1——理论篇】
试想一个问题,如果我们要抓取某个微博大V微博的评论数据,应该怎么实现呢?最简单的做法就是找到微博评论数据接口,然后通过改变参数来获取最新数据并保存。首先从微博api寻找抓取评论的接口,如下图所示。
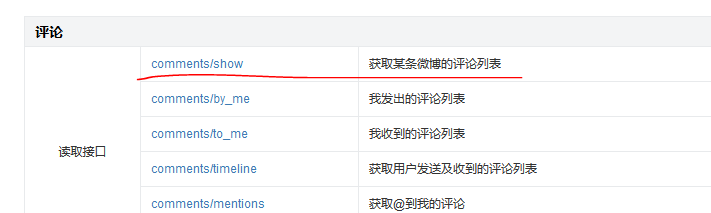
但是很不幸,该接口频率受限,抓不了几次就被禁了,还没有开始起飞,就凉凉了。
接下来小编又选择微博的移动端网站,先登录,然后找到我们想要抓取评论的微博,打开浏览器自带流量分析工具,一直下拉评论,找到评论数据接口,如下图所示。
之后点击“参数”选项卡,可以看到参数为下图所示的内容:

可以看到总共有4个参数,其中第1、2个参数为该条微博的id,就像人的身份证号一样,这个相当于该条微博的“身份证号”,max_id是变换页码的参数,每次都要变化,下次的max_id参数值在本次请求的返回数据中。

【Part2——实战篇】
有了上文的基础之后,下面我们开始撸代码,使用Python进行实现。

1、首先区分url,第一次不需要max_id,第二次需要用第一次返回的max_id。

2、请求的时候需要带上cookie数据,微博cookie的有效期比较长,足够抓一条微博的评论数据了,cookie数据可以从浏览器分析工具中找到。

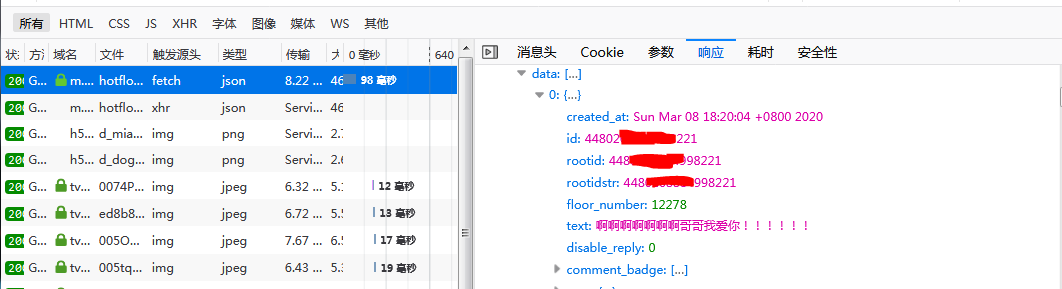
3、然后将返回数据转换成json格式,取出评论内容、评论者昵称和评论时间等数据,输出结果如下图所示。

4、为了保存评论内容,我们要将评论中的表情去掉,使用正则表达式进行处理,如下图所示。

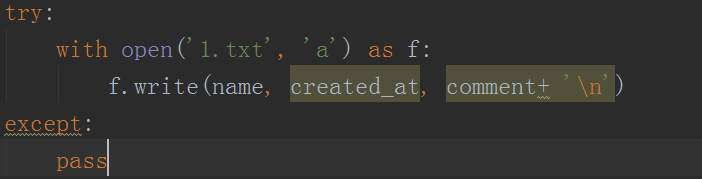
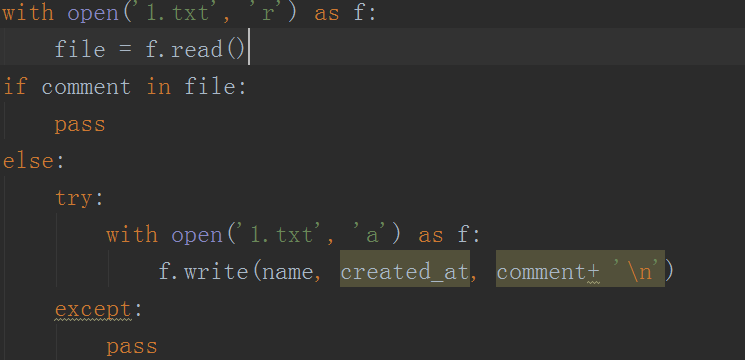
5、之后接着把内容保存到txt文件中,使用简单的open函数进行实现,如下图所示。
6、重点来了,通过此接口最多只能返回16页的数据(每页20条),网上也有说返回50页的,但是接口不同、返回的数据条数也不同,所以我加了个for循环,一步到位,遍历还是很给力的,如下图所示。

7、这里把函数命名为job。为了能够一直取出最新的数据,我们可以用schedule给程序加个定时功能,每隔10分钟或者半个小时抓1次,如下图所示。

8、对获取到的数据,做去重处理,如下图所示。如果评论已经在里边的话,就直接pass掉,如果没有的话,继续追加即可。
这项工作到此就基本完成了。
【Part3——总结篇】
这种方法虽然抓不全数据,但在这种微博的限制条件下,也是一种比较有效的方法。
最后如果您需要本文代码的话,请在后台回复“微博”二字,觉得不错,记得给个star噢~
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
一篇文章教会你使用Python定时抓取微博评论的更多相关文章
- Python爬虫抓取微博评论
第一步:引入库 import time import base64 import rsa import binascii import requests import re from PIL impo ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- 用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行.话题和阅读数 #coding=utf-8 from selenium import webdriver import ...
- 一篇文章教会你用Python抓取抖音app热点数据
今天给大家分享一篇简单的安卓app数据分析及抓取方法.以抖音为例,我们想要抓取抖音的热点榜数据. 要知道,这个数据是没有网页版的,只能从手机端下手. 首先我们要安装charles抓包APP数据,它是一 ...
- 一篇文章教会你用Python爬取淘宝评论数据(写在记事本)
[一.项目简介] 本文主要目标是采集淘宝的评价,找出客户所需要的功能.统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等. 很多人学习python,不知道从何学起.很多人学习python,掌握了 ...
- Python抓取微博评论(二)
对于新浪微博评论的抓取,首篇做的时候有些考虑不周,然后现在改正了一些地方,因为有人问,抓取评论的时候“爬前50页的热评,或者最新评论里的前100页“,这样的数据看了看,好像每条微博的评论都只能抓取到前 ...
- Python抓取微博评论
本人是张杰的小迷妹,所以用杰哥的微博为例,之前一直看的是网页版,然后在知乎上看了一个抓取沈梦辰的微博评论的帖子,然后得到了这样的网址 然后就用m.weibo.cn进行网站的爬取,里面的微博和每一条微博 ...
- PowerShell定时抓取屏幕图像
昨天的博文写了定时记录操作系统行为,其实说白了就是抓取了击键的记录和对应窗口的标题栏,而很多应用程序标题栏又包含当时记录的文件路径和文件名,用这种方式可以大致记录操作了哪些程序,打开了哪些文 ...
- Python 3.6 抓取微博m站数据
Python 3.6 抓取微博m站数据 2019.05.01 更新内容 containerid 可以通过 "107603" + user_id 组装得到,无需请求个人信息获取: 优 ...
随机推荐
- Java 面向对象基础
面向对象的基础 局部变量和成员变量区别: 1)定义的位置不同 成员变量直接定义在class中 局部变量在某个{}中或者再某个方法中 2)在内存中的位置不同 对象的成员变量会在内存中的 ...
- 来自AI的Tips——情景智能
来自AI的Tips--情景智能 上一次我们介绍了华为快服务智慧平台是什么,今天我们来侃一侃平台最有代表性的一个流量入口--情景智能(AI Tips). 首先情景智能在哪呢?大家可以拿出自己的华 ...
- 0511Object类和异常
Object类和异常 [要点] toString方法:将类中要打印的信息转换为自定义格式的打印内容 [返回的是当前对象对应的完整包名.类名@当前对象在内存空间首地址(十六进制)] equals方法 p ...
- 14 . Python3之MysSQL
数据库概念 数据库: 按照数据结构来组织.存储.管理数据的仓库` 诞生 计算机的发明是为了做科学计算的,而科学计算需要大量的输入和输出. 早期,可以使用打孔卡片的孔.灯泡的亮灭表示数据输入,输出. 后 ...
- PHP获取临时文件的目录路径
PHP获得临时文件的文件目录相对路径,能够 根据tempnam()和sys_get_temp_dir()函数来完成. 下边我们运用简单的代码实例,给大伙儿介绍PHP获得临时文件的文件目录相对路径的方式 ...
- Chisel3 - Tutorial - VendingMachineSwitch
https://mp.weixin.qq.com/s/5lcMkenM2zTy-pYOXfRjyA 演示如何使用switch/is来实现状态机. 参考链接: https://github.co ...
- 【Hadoop高级】Hadoop HA、hdfs安全模式
Hadoop HA Safemode(安全模式) During start up the NameNode loads the file system state from the fsimage a ...
- AddressBook/AddressBookUI
概述 在iOS中,有2个框架可以访问用户的通讯录.从iOS6开始,需要得到用户的授权才能访问通讯录,因此在使用之前,需要检查用户是否已经授权ABAddressBookGetAuthorizationS ...
- DOM对HTML元素的增删改操作和事件概念和事件监听
DOM创建节点的方法: document.createElement(Tag),Tag必须是合法的HTML元素 DOM复制节点的方法: 节点cloneNode(boolean deep),当deep为 ...
- WALT(Window Assisted Load Tracking)学习
QCOM平台使用WALT(Window Assisted Load Tracking)作为CPU load tracking的方法:相对地,ARM使用的是PELT(Per-Entity Load Tr ...