Python爬虫丨大众点评数据爬虫教程(2)
大众点评数据爬虫获取教程 --- 【SVG映射版本】
前言:
大众点评是一款非常受大众喜爱的一个第三方的美食相关的点评网站。从网站内可以推荐吃喝玩乐优惠信息,提供美食餐厅、酒店旅游、电影票、家居装修、美容美发、运动健身等各类生活服务,通过海量真实消费评论的聚合,帮助大家选到服务满意商家。
因此,该网站的数据也就非常有价值。优惠,评价数量,好评度等数据也就非常受数据公司的欢迎。
接上文,本篇是SVG映射版本
希望对看到这篇文章的朋友有所帮助。
- 环境和工具包:
- python 3.6
- 自建的IP池(代理)(使用的是ipidea的国内代理)
- parsel(页面解析)
下面就让我看开启探索之旅
这次我们以“http://www.dianping.com/shop/16790071/review_all”为例子。
既然读者能看到这个,那么就一定自己有过一定了解了。
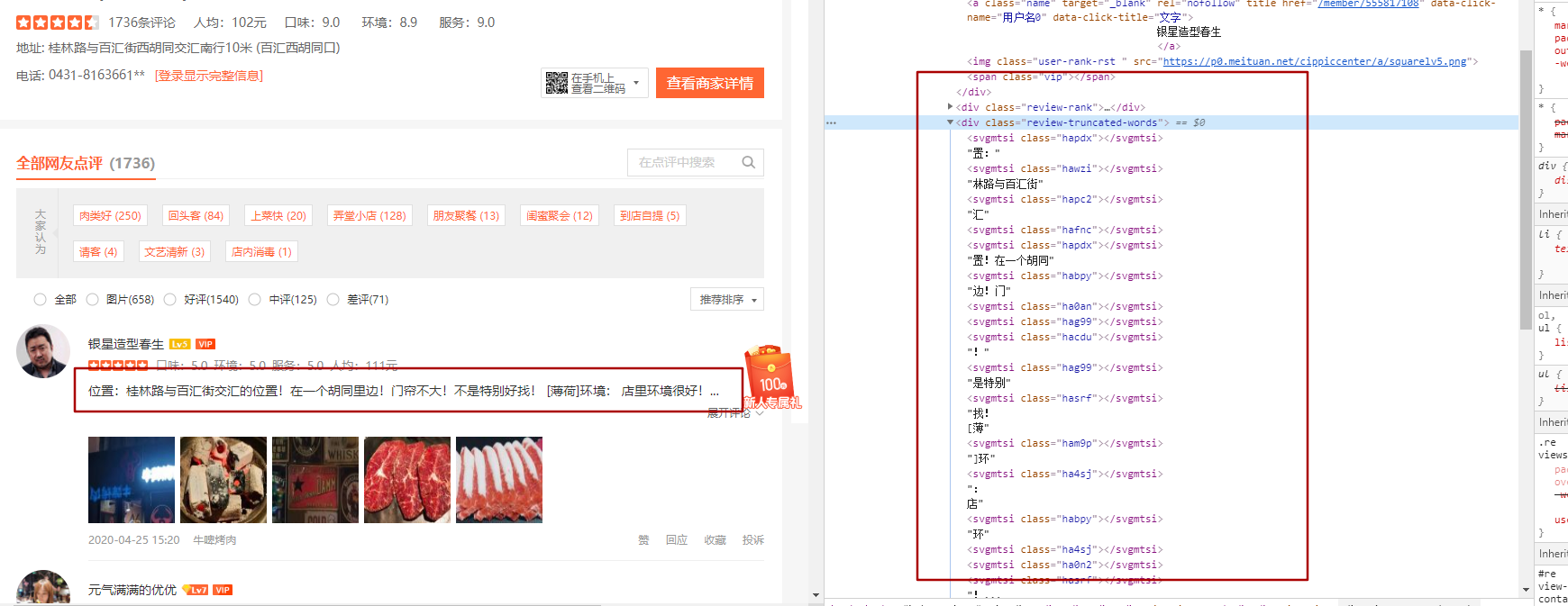
从图中的红框对比,可以看到左右内容的对比。可见并不是看到的结果就是页面返回的结果。
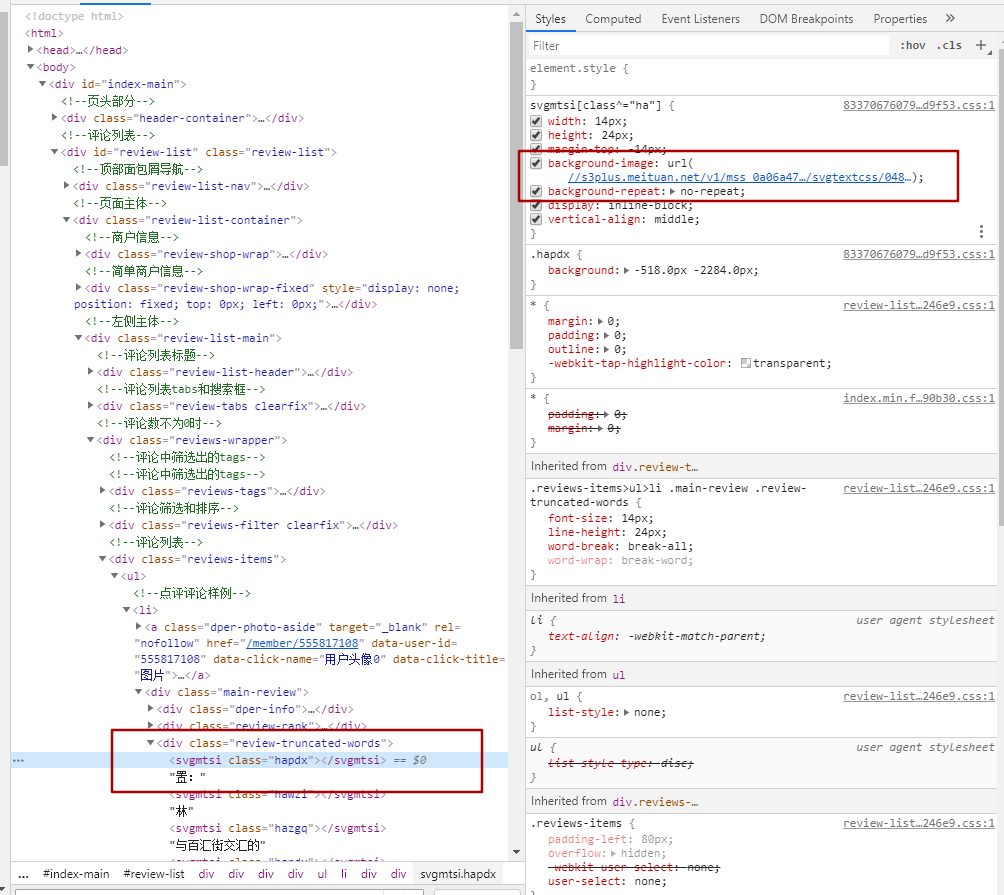
标签内容的class其实是对应的class文件里的设置,通过下图我们可以看到,对应的css个实例有个链接,这个链接就是指向对应svg映射的连接

{kind=link}
打开这个链接后看到的是如下的内容:

请注意上面的对比图,右侧的洪宽下的。hapdx属性,这个属性就是对应知道svg文字位置的背景图。可以自己动手修改参数值,相对应的位置就变了。
因此我们只需要做三步走。
一。找到对应页面的css路径,加载解析内容。处理。
二。替换页面内容,将需要替换的文字从通过属性,找到在css中对应的位置。
三。解析页面,获取对应的页面的值。
代码如下:
import re
import requests
def svg_parser(url):
r = requests.get(url, headers=headers)
font = re.findall('" y="(\d+)">(\w+)</text>', r.text, re.M)
if not font:
font = []
z = re.findall('" textLength.*?(\w+)</textPath>', r.text, re.M)
y = re.findall('id="\d+" d="\w+\s(\d+)\s\w+"', r.text, re.M)
for a, b in zip(y, z):
font.append((a, b))
width = re.findall("font-size:(\d+)px", r.text)[0]
new_font = []
for i in font:
new_font.append((int(i[0]), i[1]))
return new_font, int(width)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
"Cookie": "_lxsdk_cuid=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _lxsdk=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _hc.v=970ed851-cbab-8871-10cf-06251d4e64a0.1588154251; t_lxid=17186f9fa02c8-02b79fa94db2c8-5313f6f-1fa400-17186f9fa03c8-tid; _lxsdk_s=171c55ea204-971-8a9-eae%7C%7C368"}
r = requests.get("http://www.dianping.com/shop/73408241/review_all", headers=headers)
print(r.status_code)
# print(r.text)
css_url = "http:" + re.findall('href="(//s3plus.meituan.net.*?svgtextcss.*?.css)', r.text)[0]
print(css_url)
css_cont = requests.get(css_url, headers=headers)
print(css_cont.text)
svg_url = re.findall('class\^="(\w+)".*?(//s3plus.*?\.svg)', css_cont.text)
print(svg_url)
s_parser = []
for c, u in svg_url:
f, w = svg_parser("http:" + u)
s_parser.append({"code": c, "font": f, "fw": w})
print(s_parser)
css_list = re.findall('(\w+){background:.*?(\d+).*?px.*?(\d+).*?px;', '\n'.join(css_cont.text.split('}')))
css_list = [(i[0], int(i[1]), int(i[2])) for i in css_list]
def font_parser(ft):
for i in s_parser:
if i["code"] in ft[0]:
font = sorted(i["font"])
if ft[2] < int(font[0][0]):
x = int(ft[1] / i["fw"])
return font[0][1][x]
for j in range(len(font)):
if (j + 1) in range(len(font)):
if (ft[2] >= int(font[j][0]) and ft[2] < int(font[j + 1][0])):
x = int(ft[1] / i["fw"])
return font[j + 1][1][x]
replace_dic = []
for i in css_list:
replace_dic.append({"code": i[0], "word": font_parser(i)})
rep = r.text
# print(rep)
for i in range(len(replace_dic)):
# print(replace_dic[i]["code"])
try:
if replace_dic[i]["code"] in rep:
a = re.findall(f'<\w+\sclass="{replace_dic[i]["code"]}"><\/\w+>', rep)[0]
rep = rep.replace(a, replace_dic[i]["word"])
except Exception as e:
print(e)
# print(rep)
from parsel import Selector
response = Selector(text=rep)
li_list = response.xpath('//div[@class="reviews-items"]/ul/li')
for li in li_list:
infof = li.xpath('.//div[@class="review-truncated-words"]/text()').extract()
print(infof[0].strip().replace("\n",""))
运行结果对比图如下:
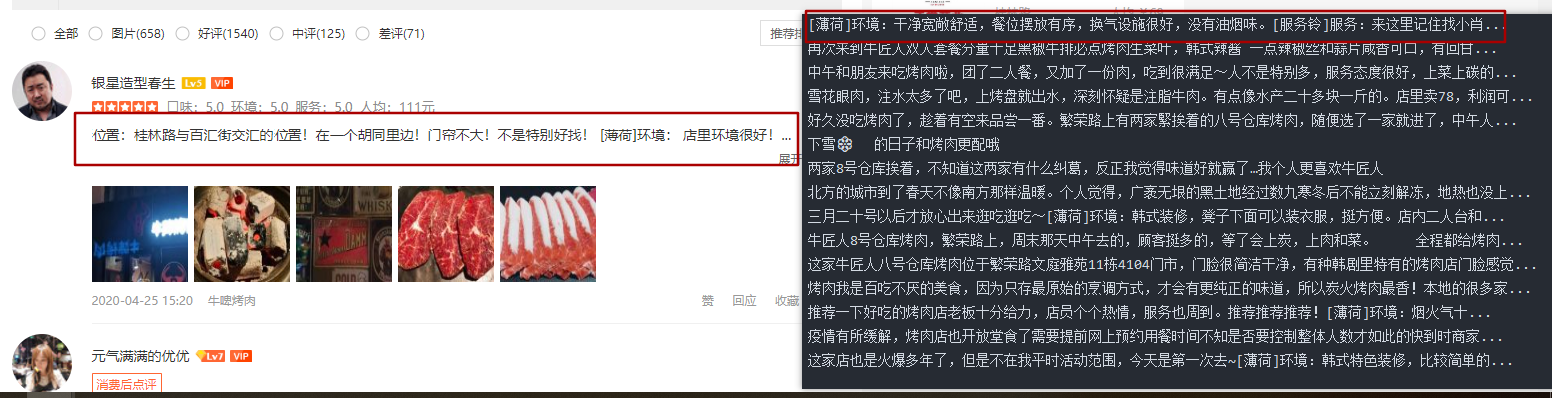
具体的流程就是代码中显示的,细节还需要完善,但内容相对应的都是可以展示出来了。
本次两篇大众点评的采集教程到这里就结束了,详细交流欢迎与我联系。
本文章旨在用于交流分享,【未经允许,谢绝转载】
Python爬虫丨大众点评数据爬虫教程(2)的更多相关文章
- Python爬虫丨大众点评数据爬虫教程(1)
大众点评数据获取 --- 基础版本 大众点评是一款非常受普罗大众喜爱的一个第三方的美食相关的点评网站. 因此,该网站的数据也就非常有价值.优惠,评价数量,好评度等数据也就非常受数据公司的欢迎. 今天就 ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- Python数据分析:大众点评数据进行选址
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:砂糖侠 如果你处于想学Python或者正在学习Python,Pyth ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 【Python3爬虫】大众点评爬虫(破解CSS反爬)
本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称.推荐菜和评分信息. 一.页面分析 进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有 ...
- python爬取大众点评
拖了好久的代码 1.首先进入页面确定自己要抓取的数据(我们要抓取的是左侧分类栏-----包括美食.火锅)先爬取第一级分类(美食.婚纱摄影.电影),之后根据第一级链接爬取第二层(火锅).要注意第二级的p ...
- python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图: 我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库. 因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis ...
- python python 入门学习之网页数据爬虫cnbeta文章保存
需求驱动学习的动力. 因为我们单位上不了外网所以读新闻是那么的痛苦,试着自己抓取网页保存下来,然后离线阅读.今天抓取的是cnbeta科技新闻,抓取地址是http://m.cnbeta.com/wap/ ...
- python python 入门学习之网页数据爬虫搜狐汽车数据库
自己从事的是汽车行业,所以首先要做的第一个程序是抓取搜狐汽车的销量数据库(http://db.auto.sohu.com/cxdata/): 数据库提供了07年至今的汽车月销量,每个车型对应一个xml ...
随机推荐
- 74HC595芯片的特性及使用方法和点评
一 它能干什么? 74HC595是一个8位串行输入.平行输出的位移缓存器:平行输出为三态输出.在SCK的上升沿,单行数据由SDL输人到内部的8位位移缓存器,并由Q7‘输出,而平行输出则是在LCK的 ...
- linux通过进程名查看其占用端口
1.先查看进程pid ps -ef | grep 进程名 2.通过pid查看占用端口 netstat -nap | grep 进程pid 参考: https://blog.csdn.net/sinat ...
- 全网最全最细的jmeter接口测试教程以及接口测试流程详解
一.Jmeter简介 Jmeter是由Apache公司开发的一个纯Java的开源项目,即可以用于做接口测试也可以用于做性能测试. Jmeter具备高移植性,可以实现跨平台运行. Jmeter可以实 ...
- python的历史和下载python解释器
一.python的诞生 1.Python的创始人为Guido van Rossum.1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,创造了一种C和sh ...
- (一)微信小程序:实现引导页
基本目录结构 index目录下文件操作步骤 1.针对index.wxml <!--index.wxml--> <view class="index-container&qu ...
- shiro:集成Springboot(六)
1:导入相关依赖 <!--thymeleaf 模板引擎依赖包--> <dependency> <groupId>org.springframework.boot&l ...
- vue结合百度地图Api实现周边配置查询及根据筛选结果显示对应坐标详情
在我们平常写房地产相关项目的时候经常会用到百度地图,因为这一块客户会考虑到房源周围的配套或者地铁线路所以在这类项目中就不可以避免的会用到百度地图,当然这只是其中一种,其他地图工具也可以,因为我这个项目 ...
- kubernetes的Statefulset介绍
StatefulSet是一种给Pod提供唯一标志的控制器,他可以保证部署和扩展的顺序. Pod一致性 包含次序(启动和停止次序).网络一致性.此一致性和Pod相关.与被调度到哪个Node节点无关. 稳 ...
- bm25算法和tfidf
- nginx+vue+thinkphp5.1部署,解决前端刷新404,以及前端404解决后,后台又404的问题
宝塔的话直接在网站的伪静态一栏中如下就行 location /admin { if (!-e $request_filename){ rewrite ^(.*)$ /index.php?s=$1 la ...