python爬虫-vmgirls-正则表达式
概述
本次爬虫任务是爬取图片网站图片,网址是https://www.vmgirls.com/
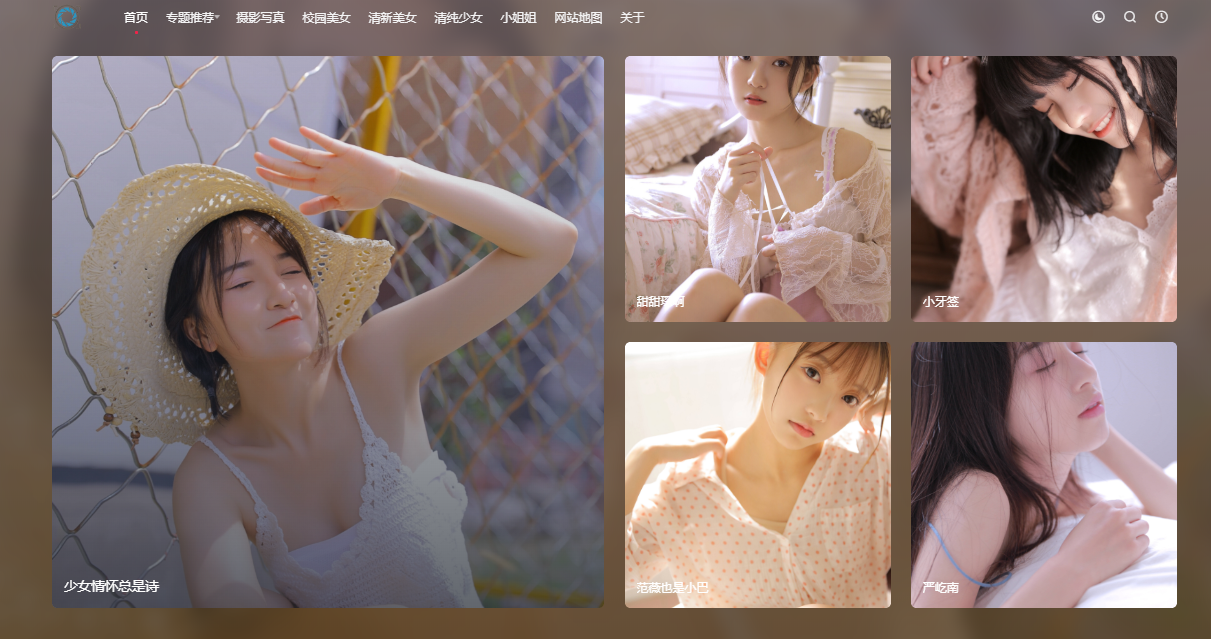
分析网页
第一步,打开需要爬取的页面https://www.vmgirls.com/13344.html
打开F12,随便选择一张图片查看图片,操作如下
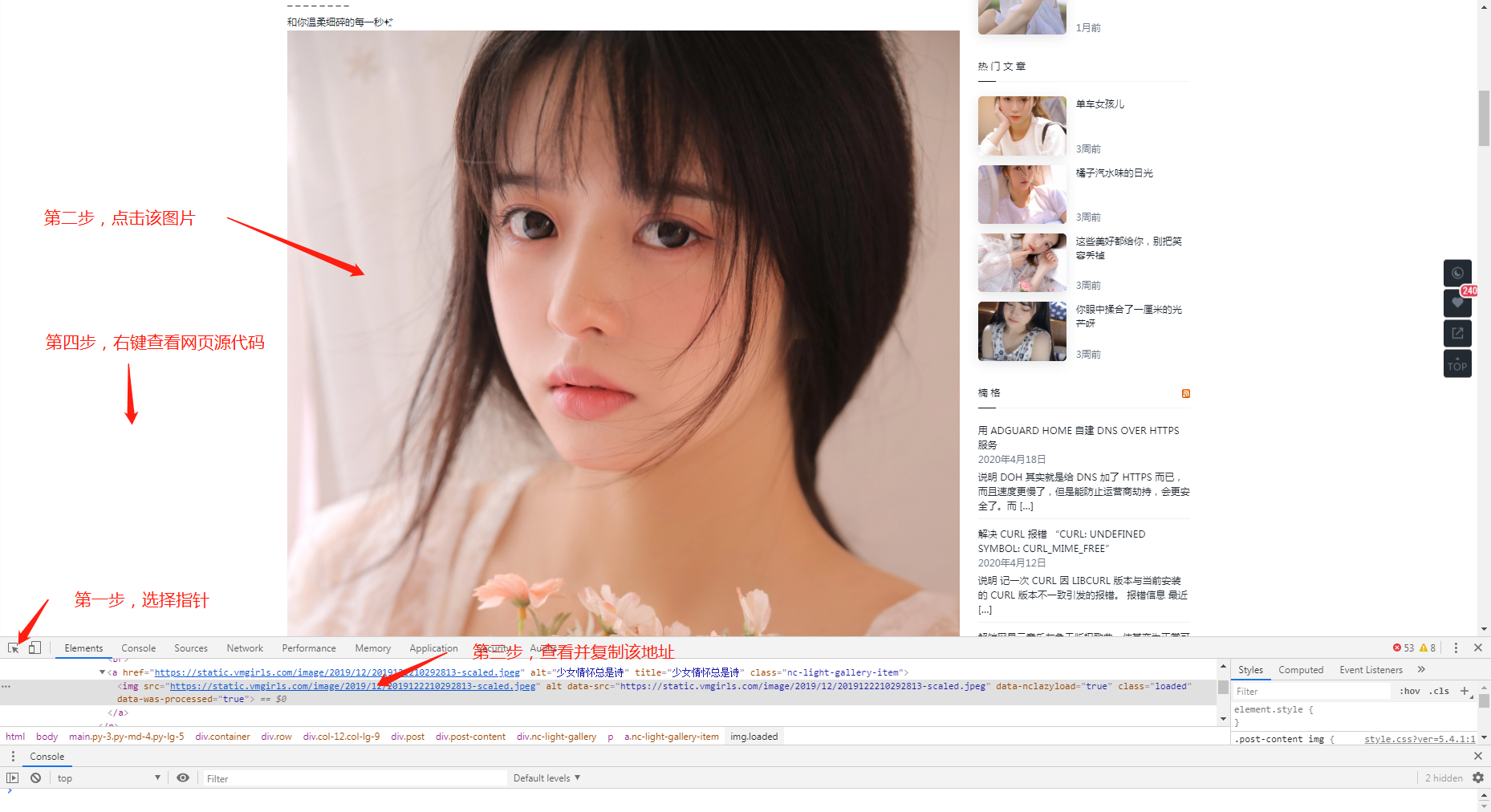
第二步,寻找所需下载图片的地址,并分析最优的方式
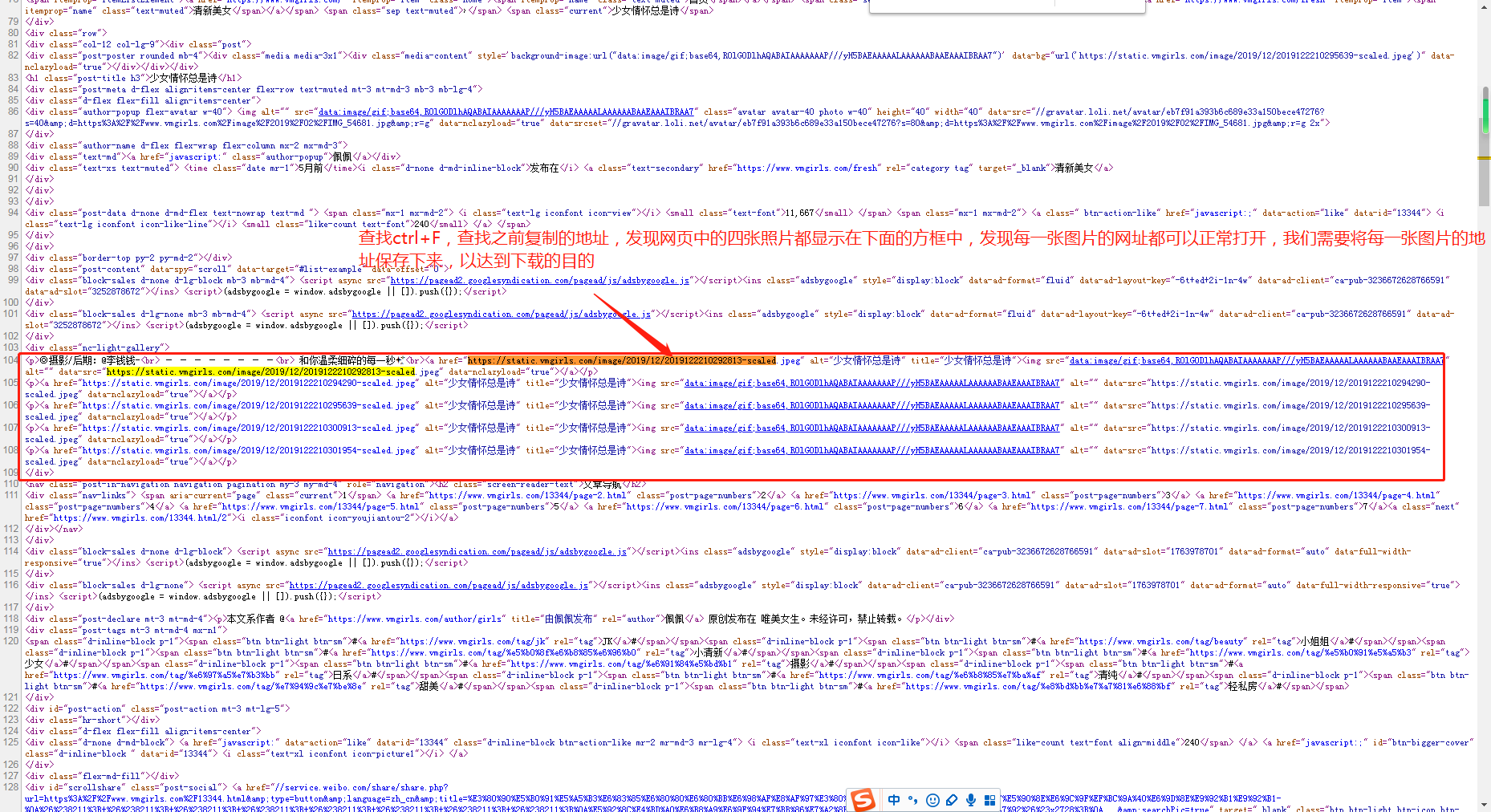
第三步,得出结论,可以通过获取每张图片的url地址,进行保存图片的动作
代码操作
请求网页
第一步,我们请求网页并打印网页返回的请求
import requests
'''请求网页'''
response = requests.get('https://www.vmgirls.com/13344.html', headers=headers)#请求网址并得到一个回复
print(response.text)
发现出现403 Forbidden,我们需要寻找原因
# <html>
# <head><title>403 Forbidden</title></head>
# <body>
# <center><h1>403 Forbidden</h1></center>
# <hr><center>Her</center>
# </body>
# </html>
我们插入一个代码
print(response.request.headers)
发现问题所在,网页返回的信息中表示,我们发送的请求来源于一个爬虫程序,所以我们需要伪装一个header,
# {'User-Agent': 'python-requests/2.23.0',
# 'Accept-Encoding': 'gzip, deflate',
# 'Accept': '*/*',
# 'Connection': 'keep-alive'}
怎么做,打开浏览器,指定网页,F12查看浏览器发送的headers
复制heades到代码中
import requests
'''请求网页'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
} response = requests.get('https://www.vmgirls.com/13344.html', headers=headers)#请求网址并得到一个回复
print(response.text)
print(response.request.headers)
能够正常得到网页返回的信息了
解析网页
解析网页本次使用正则表达式
导入re库
import re
urls = re.findall('<a href="(.*?)" alt=".*?" title=".*?">', html)
print(urls)
得到5个图片的url链接
['https://static.vmgirls.com/image/2019/12/2019122210292813-scaled.jpeg',
'https://static.vmgirls.com/image/2019/12/2019122210294290-scaled.jpeg',
'https://static.vmgirls.com/image/2019/12/2019122210295639-scaled.jpeg',
'https://static.vmgirls.com/image/2019/12/2019122210300913-scaled.jpeg',
'https://static.vmgirls.com/image/2019/12/2019122210301954-scaled.jpeg']
保存图片
将所有的图片保存为文件格式
for url in urls:
response = requests.get(url, headers=headers)
# 将url中后面的数字字段截取出来作为图片的文件名
file_name = url.split('/')[-1]
# 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
with open(file_name,'wb') as f:
# 文件写入每一个response返回的内容,最终保存的即为图片,图片地址在该py文件相同目录
f.write(response.content)
此时需要考虑到两个问题
1.访问频次
2.文件应该需要保存在但个文件夹中,问不是散乱的存放
修改代码如下
import os
# 获得文件夹名
dir_name = re.findall('<h1 class="post-title h3">(.*?)</h1>', html)[-1]
# 判断文件夹是否存在,并创建文件夹
if not os.path.exists(dir_name):
os.makedirs(dir_name)
# 遍历所有的url,将所有的url单独保存
for url in urls: # 放置访问频次太高,设置访问频率,需要导入time模块
time.sleep(1)
response = requests.get(url, headers=headers)
# 将url中后面的数字字段截取出来作为图片的文件名
file_name = url.split('/')[-1] # 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
# 由于加入了文件夹的步骤,所以with open(file_path,wb)as f中file_path需要带上文件夹
# with open(file_name,'wb') as f:
with open(dir_name+'/'+file_name, 'wb') as f:
# 文件写入每一个response返回的内容,最终保存的即为图片,图片地址在该py文件相同目录
f.write(response.content) # 由于这种方式文件是一个个单独的存放在目录下面,并没有较好的分类,我们需要加入一个分类的步骤
# 根据网页中的名称设置文件夹名为dir_name = re.findall('<h1 class="post-title h3">(.*?)</h1>')[-1]
# 若想创建文件夹,需要导入os库
# 判断文件夹是否存在
任务完成
完整代码
import requests
import re
import time
import os '''请求网页''' headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
} response = requests.get('https://www.vmgirls.com/13344.html', headers=headers)#请求网址并得到一个回复
html = response.text """
print(response.text) # <html>
# <head><title>403 Forbidden</title></head>
# <body>
# <center><h1>403 Forbidden</h1></center>
# <hr><center>Her</center>
# </body>
# </html> # 发现了403 Forbidden,也就是这个系统设置了反爬虫,所以需要改变
# 我们查看一下返回的headers,也就是请求的头信息 print(response.request.headers) # {'User-Agent': 'python-requests/2.23.0',
# 'Accept-Encoding': 'gzip, deflate',
# 'Accept': '*/*',
# 'Connection': 'keep-alive'} # 发现这是用python端请求,理所当然的被网页拒绝了,所以我们需要一个伪装的headers,伪装成浏览器发送的请求
# 怎么做,打开浏览器,指定网页,F12查看浏览器发送的headers
# {user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36} # 制作伪装的headers
# headers = {'user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
# 注意headers是一个字典,不是字符串,所以格式为"user-agent":"头部具体信息" # 将headers放置到网页请求的前面,即response前
# 同时response里面带上headers
# 程序运行之后发现可以正常运行 """ '''解析网页''' # 解析网页本次使用正则表达式
# 导入re库 # 获得文件夹名
dir_name = re.findall('<h1 class="post-title h3">(.*?)</h1>', html)[-1]
# 判断文件夹是否存在,并创建文件夹
if not os.path.exists(dir_name):
os.makedirs(dir_name) # 获得所有图片的url链接
urls = re.findall('<a href="(.*?)" alt=".*?" title=".*?">', html)
print(urls) """保存图片""" # 遍历所有的url,将所有的url单独保存
for url in urls: # 放置访问频次太高,设置访问频率,需要导入time模块
time.sleep(1)
response = requests.get(url, headers=headers)
# 将url中后面的数字字段截取出来作为图片的文件名
file_name = url.split('/')[-1] # 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
# 由于加入了文件夹的步骤,所以with open(file_path,wb)as f中file_path需要带上文件夹
# with open(file_name,'wb') as f:
with open(dir_name+'/'+file_name, 'wb') as f:
# 文件写入每一个response返回的内容,最终保存的即为图片,图片地址在该py文件相同目录
f.write(response.content) # 由于这种方式文件是一个个单独的存放在目录下面,并没有较好的分类,我们需要加入一个分类的步骤
# 根据网页中的名称设置文件夹名为dir_name = re.findall('<h1 class="post-title h3">(.*?)</h1>')[-1]
# 若想创建文件夹,需要导入os库
# 判断文件夹是否存在
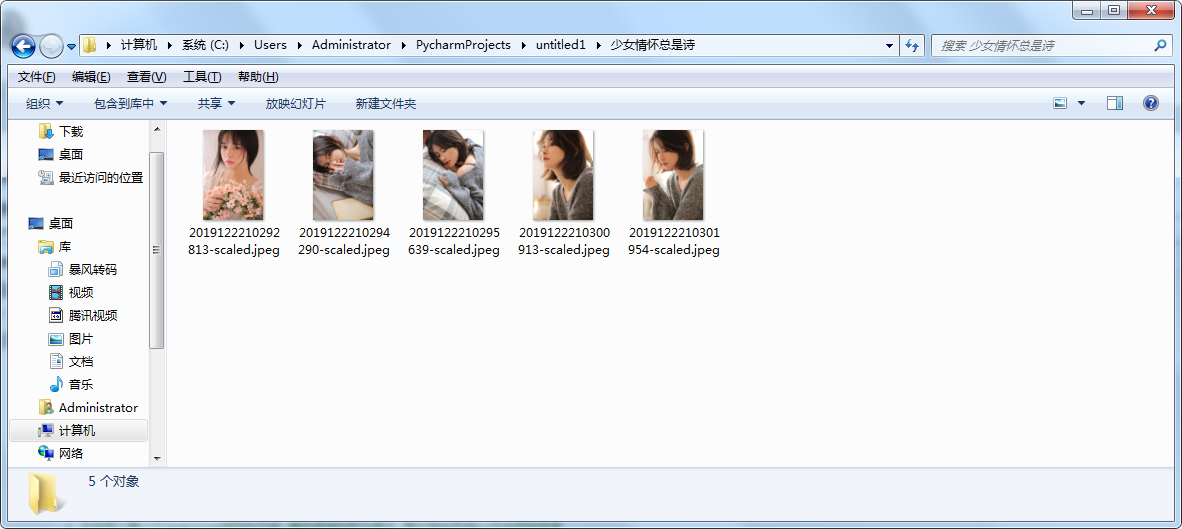
图片结果
python爬虫-vmgirls-正则表达式的更多相关文章
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片. 如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门 所有图片的s ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- Python爬虫运用正则表达式
我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像可以用一下最近学的东 ...
- Python爬虫之正则表达式(3)
# re.sub # 替换字符串中每一个匹配的子串后返回替换后的字符串 import re content = 'Extra strings Hello 1234567 World_This is a ...
- Python爬虫之正则表达式(1)
廖雪峰正则表达式学习笔记 1:用\d可以匹配一个数字:用\w可以匹配一个字母或数字: '00\d' 可以匹配‘007’,但是无法匹配‘00A’; ‘\d\d\d’可以匹配‘010’: ‘\w\w\d’ ...
- python爬虫之正则表达式
一.简介 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念 ...
- Python爬虫基础——正则表达式
说到爬虫,不可避免的会牵涉到正则表达式. 因为你需要清晰地知道你需要爬取什么信息?它们有什么共同点?可以怎么去表示它们? 而这些,都需要我们熟悉正则表达,才能更好地去提取. 先简单复习一下各表达式所代 ...
随机推荐
- 编码理解的漫漫长路(Unicode、GBK、ISO)
Ø 那么现在开始康康都有哪些编码方式 1. ASCII
- redis: 其他数据类型(八)
1.geospatial 地理位置 有效的经度从-180度到180度 有效的纬度从-85.05112878度到85.05112878度 当坐标位置超出上述指定范围时,该命令将会返回一个错误 底层实现原 ...
- SVM之不一样的视角
在上一篇学习SVM中 从最大间隔角度出发,详细学习了如何用拉格朗日乘数法求解约束问题,一步步构建SVM的目标函数,这次尝试从另一个角度学习SVM. 回顾监督学习要素 数据:(\(x_i,y_i\)) ...
- CSS选择器与CSS的继承,层叠和特殊性
什么是选择器?选择器{样式;},在{}之前的部分就是"选择器","选择器"指明了{}中的"样式"的作用对象,也就是"样式" ...
- 在 Azure CentOS VM 中配置 SQL Server 2019 AG - (上)
前文 假定您对Azure和SQL Server HA具有基础知识 假定您对Azure Cli具有基础知识 目标是在Azure Linux VM上创建一个具有三个副本的可用性组,并实现侦听器和Fenci ...
- sqlilab less15-17
less15 试了很多符号,页面根本不显示别的信息,猜测为盲注 可是怎么检测闭合? 万能密码登录 最终试出来'闭合 uname=1' or 1=1 # 接下来就要工具跑 less16 同上用万能密码试 ...
- ThinkPHP框架初步掌握
为了帮老师用ThinkSNS二次开发一个微博系统,专门花了几天学习ThinkPHP框架,现在将一些ThinkPHP入门知识作以记录. 首先声明: 本文不是完全教程,只是将开发中碰到的问题作以总结,如果 ...
- 列表按钮功能的设置和DOM的使用
HTML: <foreach name="fulltime_list" item="v"> <tr> <td></td ...
- 2019-2020-1 20199308《Linux内核原理与分析》第六周作业
<Linux内核分析> 第五章 系统调用的三层机制(下) 5.1 给MenuOS增加命令 强制删除当前menu目录,用get clone重新克隆一个新版本的menu,运行make root ...
- web 之 session
Session? 在WEB开发中,服务器可以为每个用户浏览器创建一个会话对象(session对象),注意:一个浏览器独占一个session对象(默认情况下).因此,在需要保存用户数据时,服务器程序可以 ...