基于树莓派与YOLOv3模型的人体目标检测小车(一)
项目介绍:
本科毕业选的深度学习的毕设,一开始只是学习了一下YOLOv3模型, 按照作者的指示在官网上下载下来权重,配好环境跑出来Demo,后来想着只是跑模型会不会太单薄,于是想了能不能做出来个比较实用的东西(因为模型优化做不了)。于是乎做一个可以检测人体的可操控移动小车的想法就诞生了。
实现的功能:1. 控制小车行进,并实时检测人体目标。
2. 作为家庭监控,可以将出现在摄像头中的人体目标通过微信发到手机上,并可以人为决定是否通过蜂鸣器发出警报。
大致的工作包括:1. YOLOv3 tiny 模型的训练
2. Darknet模型到tensorflow模型再到NCS(神经计算加速棒)模型的两次转化
3. 小车控制以及视频流直播程序
4. 微信报警程序
一 、环境搭建
一、安装NVIDIA显卡驱动
1.删除旧的驱动。
原来Linux默认安装的显卡驱动不是英伟达的驱动,所以先把旧得驱动删除掉。
sudo apt-get purge nvidia*
2.禁止自带的nouveau nvidia驱动。
2.1 打开配置文件:
sudo gedit /etc/modprobe.d/blacklist-nouveau.conf
2.2填写禁止配置的内容:
blacklist nouveau``options nouveau modeset=0
2.3更新配置文件:
sudo update-initramfs -u
重启电脑!
2.4检查设置
(因为禁止了显卡的驱动,这时你的电脑分辨率会变成800*600,图标格式将会很不和谐,当然通过这个可以看出,是否完成这上面的操作)
lsmod | grep nouveau
*如果屏幕没有输出则禁用nouveau成功
3 正式安装
法一:ppa源安装(原生安装)
1.添加Graphic Drivers PPA
sudo add-apt-repository ppa:graphics-drivers/ppa``sudo apt-get update
2.查看合适的驱动版本:
ubuntu-drivers devices
3.在这里我选择合适的396版本:
sudo apt-get install nvidia-driver-396
重启电脑!
4.安装成功检查:
sudo nvidia-smi``sudo nvidia-settings
*最直接的方法是进入到系统的“软件和更新”,点击进入到“附加驱动”,选择你需要安装的英伟达驱动,然后点击“应用更改”,便能进行安装了。注意的是这个方法适合网速较好的环境下进行。
二、安装CUDA
1、官网下载:https://developer.nvidia.com/cuda-90-download-archive
我的如下:
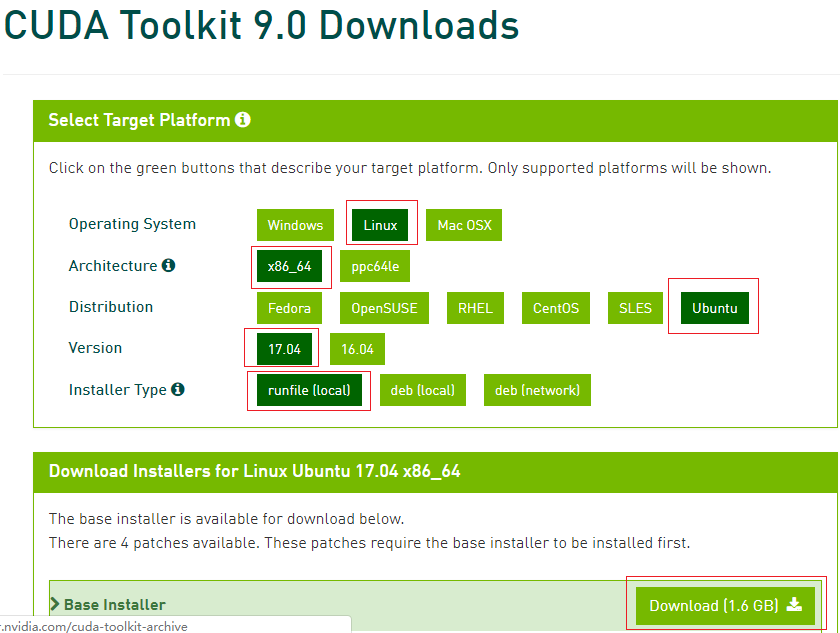
2、安装依赖库
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
否则将会报错:
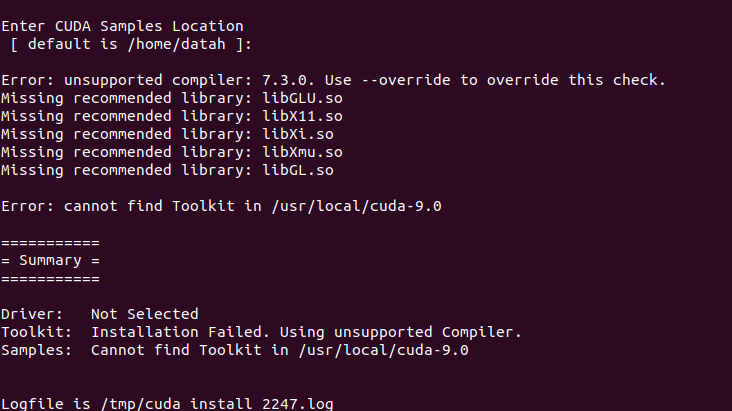
3、注意C++\G++版本
CUDA9.0要求GCC版本是5.x或者6.x,其他版本不可以,需要自己进行配置,通过以下命令才对gcc版本进行修改。
查看版本:
g++ --version
版本安装:
sudo apt-get install gcc-5
sudo apt-get install g++-5
通过命令替换掉之前的版本:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 50
最后记得再次查看版本是否修改成功。
4、运行run文件
sudo sh cuda_9.0.176_384.81_linux.run
安装协议可以直接按q跳到最末尾,注意一项:
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n # 安装NVIDIA加速图形驱动程序,这里选择n
5、添加环境变量
进行环境的配置,打开环境变量配置文件
sudo gedit ~/.bashrc
在末尾把以下配置写入并保存:
#CUDA
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
最后执行:
source ~/.bashrc
6、安装测试
在安装的时候也也相应安装了一些cuda的一些例子,可以进入例子的文件夹然后使用make命令执行。
例一:
1.进入例子文件
cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
2.执行make命令
sudo make
\3. 第三步
./deviceQuery
如果结果有GPU的信息,说明安装成功。
例二:
\1. 进入例子对应的文件夹
cd NVIDIA_CUDA-9.0_Samples/5_Simulations/fluidsGL
2.执行make
make clean && make
\3. 运行
./fluidsGL
当执行这个例子,我们会看到流动的图,刚开始可能看不到黑洞,需要等待一小段时间。不过记得用鼠标点击下绿色的画面。

三、安装cuDNN
1、官网下载:https://developer.nvidia.com/rdp/form/cudnn-download-survey
这个需要注册账号,拿自己的邮箱注册即可。
只需下载下面3个安装包即可

2、顺序执行下面3个安装命令:
sudo dpkg -i libcudnn7_7.0.3.11-1+cuda9.0_amd64.deb``sudo dpkg -i libcudnn7-dev_7.0.3.11-1+cuda9.0_amd64.deb``sudo dpkg -i libcudnn7-doc_7.0.3.11-1+cuda9.0_amd64.deb
3、安装测试
输入以下命令:
cp -r /usr/src/cudnn_samples_v7/ $HOME``cd $HOME/cudnn_samples_v7/mnistCUDNN``make clean && make``./mnistCUDNN
最终如果有提示信息:“Test passed! ”,则说明安装成功!
四、安装TensorFlow
1.pip直接安装
pip install tensorflow_gpu-1.9.0
五、安装darknet
打开YOLOv3官网,https://pjreddie.com/darknet/,按着教程一步一步的照做。
把项目克隆到本地,编译
git clone https://github.com/pjreddie/darknet
cd darknet
make
下载已经训练好的yolov3权重,或者直接wget,如果下载速度太慢可以去百度找一下。
wget https://pjreddie.com/media/files/yolov3.weights
下载完之后就可以使用权重模型来进行测试了。
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
这里不会弹出来检测的图片是因为没有安装OpenCV,检测的结果会在项目文件夹下生成predictions.png.
如果你有摄像头,你也可以直接通过视频测试模型
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
六、总结
至此已完成了,模型训练端的环境搭建,下一篇文章将介绍如何利用YOLOv3模型训练自己的数据集。
基于树莓派与YOLOv3模型的人体目标检测小车(一)的更多相关文章
- 目标检测-基于Pytorch实现Yolov3(1)- 搭建模型
原文地址:https://www.cnblogs.com/jacklu/p/9853599.html 本人前段时间在T厂做了目标检测的项目,对一些目标检测框架也有了一定理解.其中Yolov3速度非常快 ...
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
- 基于深度学习的安卓恶意应用检测----------android manfest.xml + run time opcode, use 深度置信网络(DBN)
基于深度学习的安卓恶意应用检测 from:http://www.xml-data.org/JSJYY/2017-6-1650.htm 苏志达, 祝跃飞, 刘龙 摘要: 针对传统安卓恶意程序检测 ...
- CVPR2020|3D-VID:基于LiDar Video信息的3D目标检测框架
作者:蒋天园 Date:2020-04-18 来源:3D-VID:基于LiDar Video信息的3D目标检测框架|CVPR2020 Brief paper地址:https://arxiv.org/p ...
- EGADS介绍(二)--时序模型和异常检测模型算法的核心思想
EDADS系统包含了众多的时序模型和异常检测模型,这些模型的处理会输入很多参数,若仅使用默认的参数,那么时序模型预测的准确率将无法提高,异常检测模型的误报率也无法降低,甚至针对某些时间序列这些模型将无 ...
- .NET - 基于事件的异步模型
注:这是大概四年前写的文章了.而且我离开.net领域也有四年多了.本来不想再发表,但是这实际上是Active Object模式在.net中的一种重要实现方法,因此我把它掏出来发布一下.如果该模型有新的 ...
- 基于Pre-Train的CNN模型的图像分类实验
基于Pre-Train的CNN模型的图像分类实验 MatConvNet工具包提供了好几个在imageNet数据库上训练好的CNN模型,可以利用这个训练好的模型提取图像的特征.本文就利用其中的 “im ...
- word2vec 中的数学原理具体解释(五)基于 Negative Sampling 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注. 因为 word2vec 的作者 Tomas ...
- word2vec 中的数学原理具体解释(四)基于 Hierarchical Softmax 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注.因为 word2vec 的作者 Tomas M ...
随机推荐
- 基于USB接口芯片CH372的人机接口设备设计与实现(转)
摘 要: 基于一种新型USB 总线接口芯片CH372,设计出一种人机接口设备-USB 鼠标.阐述了CH372 的工作原理和特点,给出了系统的硬件电路图:在软件设计中,分析了HID 类设备描述符枚举过程 ...
- VR、网剧如何成为民间骗子中的朝阳产业
互联网的发达,让大众有了了解世界最好的传播工具.但与此同时,大量信息潮的涌来,让人们难以分辨其中的真假.于是,原本靠大力丸.保健药.假公章等行骗的骗子们开始转变方向,利用信息不对称性,大肆捏造与热 ...
- 在线选题系统完善篇(PHP)
第一篇: 选题在线提交系统(html+JS+PHP) 这是当时根据需求做的一个简单的版本,只能适用于这一个场景,而且题目等一系列数据都不能改.然后结束后,我又对重新写了一个有后台管理的选题系统.相对于 ...
- C++走向远洋——25(项目二,游戏类)
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:game.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- [Statistics] Comparison of Three Correlation Coefficient: Pearson, Kendall, Spearman
There are three popular metrics to measure the correlation between two random variables: Pearson's c ...
- MVC06
1.校验机制 我们可以在Model中使用属性进行校验 using System; using System.ComponentModel.DataAnnotations; using System.D ...
- JS对象之封装(二)
JS 对象封装的常用方式 1.常规封装 function Person (name,age){ this.name = name; this.age = age; } Pserson.prototyp ...
- 东南大学RM装甲板识别算法详解
rm中,装甲板的识别在比赛中可谓是最基础的算法.而在各个开源框架中,该算法也可以说最为成熟.出于学习目的,之后将对比多个高校或网络代码(),尝试学习各个rm装甲板识别算法的优点和流程. 这次先是东南大 ...
- view添加阴影
//@mg:masksToBounds必须为NO否者阴影没有效果 // cell.layer.masksToBounds = NO; cell.layer.contentsScale = [UI ...
- Androidstudio实现一个简易的加法器——分享两种方法实现(日常作业练习)
Androidstudio实现一个简易的加法器——分享两种方法实现(日常作业练习) ...