python3下scrapy爬虫(第一卷:安装问题)
一般爬虫都是用urllib包,requests包 配合正则.beautifulsoup等包混合使用,达到爬虫效果,不过有框架谁还用原生啊,现在我们来谈谈SCRAPY框架爬虫,
现在python3的兼容性上来了,SCRAPY不光支持python2版本了,有新的不用旧的,现在说一下让很多人望而止步的安装问题,很多人开始都安装不明白,
当前使用的版本是PYTHON3.5,安装时用PIP3
安装步骤:
1 安装wheel
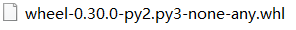
pip3 install wheel
2 安装twisted
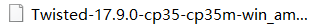
pip3 install Twisted-17.9.0-cp35-cp35m-win_amd64.whl
3 安装lxml
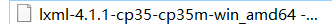
pip3 install lxml-4.1.1-cp35-cp35m-win_amd64.whl
4 安装scrapy
pip3 install scrapy
这样你就成功的安装上了scrapy,你可以创建文件,但是你任然不可爬虫,一旦执行爬虫文件就会报错
5 安装pywin32

一路下一步就行
接着我们创建scrapy文件夹
进入运行环境为python3.5的文件路径,如果你的电脑同时安装2,3版本一定要注意问题。两个版本会出现环境冲突问题,一旦python3版本下的scrapy运行在python2下就会出现版本不兼容问题,就会出现NO MOUDLE的报错
路径切换到python3运行的环境:
scrapy startproject filename
终端进入filename目录
scrapy genspider -t basic crawl1 webname.com
就会创建爬虫脚本文件
文件夹里几个文件我也就不介绍了,
我说下基本爬虫setting.py的应用
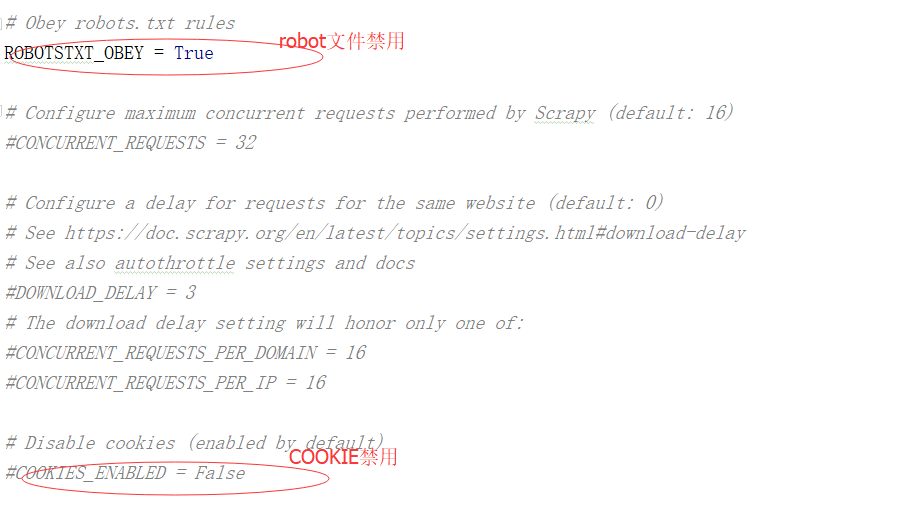
现在可以进行正常的爬取网页了
python3下scrapy爬虫(第一卷:安装问题)的更多相关文章
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架 跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为 ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
随机推荐
- Python说文解字_main
1. main函数: 我们知道很多的编程语言都要写一个main函数,比如在C# 中Main函数还需要大写.很多人疑惑为什么要写这么一个Main函数.其实这就是好比我们在建了一排房子,你从哪个门都可以进 ...
- 一文彻底搞懂Cookie、Session、Token到底是什么
> 笔者文笔功力尚浅,如有不妥,请慷慨指出,必定感激不尽 Cookie 洛:大爷,楼上322住的是马冬梅家吧? 大爷:马都什么? 夏洛:马冬梅. 大爷:什么都没啊? 夏洛:马冬梅啊. 大爷:马什 ...
- 2.Jenkins结合k8s完成Jenkins slave功能
1.构建镜像 下载基础镜像,这里使用openvz的包,下载地址为:https://wiki.openvz.org/Download/template/precreated,下载centos7的镜像 下 ...
- vue 常用知识点
1.数据变更,页面渲染完成 this.$nextTick(function(){ alert('v-for渲染已经完成') }) 2.iview select组件 setQuery用法 <Sel ...
- GCC生成动态链接库(.so文件):-shared和-fPIC选项
Linux 下动态链接库(shared object file,共享对象文件)的文件后缀为.so,它是一种特殊的目标文件(object file),可以在程序运行时被加载(链接)进来.使用动态链接库的 ...
- gcc -c xx.c 选项讲解
-c选项表示编译.汇编指定的源文件(也就是编译源文件),但是不进行链接.使用-c选项可以将每一个源文件编译成对应的目标文件. 目标文件是一种中间文件或者临时文件,如果不设置该选项,gcc 一般不会保留 ...
- beta函数分布图
set.seed(1) x<-seq(-5,5,length.out=10000) a = c(.5,0.6, 0.7, 0.8, 0.9) b = c(.5, 1, 1, 2, 5) colo ...
- mysql only_full_group_by
下载安装的是最新版的mysql5.7.x版本,默认是开启了 only_full_group_by 模式的,但开启这个模式后,原先的 group by 语句就报错,然后又把它移除了. 一旦开启 only ...
- @ResponseBody与@RestController
@ResponseBody与@RestController的作用与区别 https://blog.csdn.net/xfl4629712/article/details/78528387
- eclipse web 项目配置 运行