IK分词器 整合solr4.7 含同义词、切分词、停止词
转载请注明出处!
IK分词器如果配置成
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
本人测试切分词可以,但是同义词,扩展词库用不了,
网上查各种资料说IK分词器有个BUG,要自己把jar文件改一下,于是找到IK的源码,里面只有IKAnalyzer的源码,代码如下
package org.wltea.analyzer.lucene; import java.io.Reader; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer; /**
* IK分词器,Lucene Analyzer接口实现
* 兼容Lucene 4.0版本
*/
public final class IKAnalyzer extends Analyzer{ private boolean useSmart; public boolean useSmart() {
return useSmart;
} public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
} /**
* IK分词器Lucene Analyzer接口实现类
*
* 默认细粒度切分算法
*/
public IKAnalyzer(){
this(false);
} /**
* IK分词器Lucene Analyzer接口实现类
*
* @param useSmart 当为true时,分词器进行智能切分
*/
public IKAnalyzer(boolean useSmart){
super();
this.useSmart = useSmart;
} /**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader in) {
Tokenizer _IKTokenizer = new IKTokenizer(in , this.useSmart());
return new TokenStreamComponents(_IKTokenizer);
} }
自己加了一个IKAnalyzerSolrFactory,代码如下
package org.wltea.analyzer.lucene; import java.io.Reader;
import java.util.Map; import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory; public class IKAnalyzerSolrFactory extends TokenizerFactory{ private boolean useSmart; public boolean useSmart() {
return useSmart;
} public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
} public IKAnalyzerSolrFactory(Map<String,String> args) {
super(args);
assureMatchVersion();
this.setUseSmart(args.get("useSmart").toString().equals("true"));
} @Override
public Tokenizer create(AttributeFactory factory, Reader input) {
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
} }
这样一来就能在配置文件中配置成IKAnalyzerSolrFactory 的列子
下面是具体的配置描述:
1。修改IK的jar文件,加入IKAnalyzerSolrFactory (如果不会改的自行下载 http://pan.baidu.com/s/1gfLOIL9)
2.修改solrconfig.xml文件,加入
<lib dir="/contrib/analysis-extras/lib" regex=".*\.jar" />
3.修改schema.xml文件,加入
<!--IK分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
4.在solr的webINFO 下的classes(没有新建)加入如下图,IK压缩文件中的部分文件,如图所示:
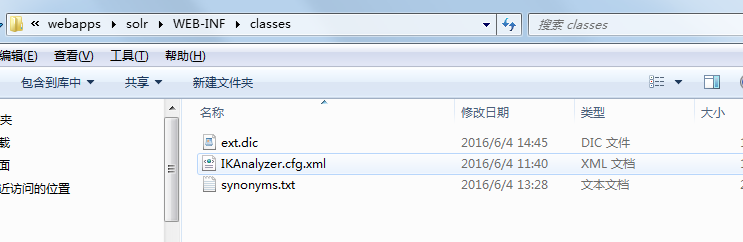
5.在ext.dic配置自定义词库,不需要切分词的词语配置在此,同义词写在synonyms.txt中即可。格式为: 通知,通告
注意每次改变词库或者同义词需要重启服务。
IK分词器 整合solr4.7 含同义词、切分词、停止词的更多相关文章
- Ik分词器没有使用---------elasticsearch-analysis-ik 5.6.3分词问题
此文章在作者认真阅读源码后发现,这并不是问题所在. 此篇文章是对IK配置的错误理解.新版本的IK配置的扩展字典本来就该使用者自己去手动配置! 1.问题 现在项目中用的是ES5.6.3的版本,在解决Fi ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- 【杂记】docker搭建ELK 集群6.4.0版本 + elasticsearch-head IK分词器与拼音分词器整合
大佬博客地址:https://blog.csdn.net/supermao1013/article/category/8269552 docker elasticsearch 集群启动命令 docke ...
- solr4.x配置IK2012FF智能分词+同义词配置
本文配置环境:solr4.6+ IK2012ff +tomcat7 在Solr4.0发布以后,官方取消了BaseTokenizerFactory接口,而直接使用Lucene Analyzer标准接口T ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
- Solr多核心及分词器(IK)配置
Solr多核心及分词器(IK)配置 多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索 ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- solr4.5配置中文分词器mmseg4j
solr4.x虽然提供了分词器,但不太适合对中文的分词,给大家推荐一个中文分词器mmseg4j mmseg4j的下载地址:https://code.google.com/p/mmseg4j/ 通过以下 ...
随机推荐
- Workerman-文件监控-牛刀小试
今天学习了workerman , 初次体验了定时器的效果,结合文档.弄了个文件监控. 好了 废话不多说 直接上代码 use Workerman\Worker; require_once __DIR__ ...
- 怎样用ZBrush对模型进行渲染(二)
继上节课Fisker老师对ZBrush中对渲染和灯光起到重要作用的Light和LightCap进行了具体讲解之后,本节课继续研究Render(渲染)和Light及LightCap相结合会产生什么样的效 ...
- NYOJ 734
奇数阶魔方 描述 一个 n 阶方阵的元素是1,2,...,n^2,它的每行,每列和2条对角线上元素的和相等,这样的方阵叫魔方.n为奇数时我们有1种构造方法,叫做“右上方” ,例如下面给出n=3,5,7 ...
- Java面向对象编程 第一章 面向对象开发方法概述
一.软件开发经历的生命周期: ①软件分析 ②软件设计 ③软件编码 ④ 软件测试 ⑤ 软件部署 ⑥软件维护 二.为了提高软件开发效率,降低软件开发成本,一个优良的软件系统应该具备以下特点: ① 可重用性 ...
- 将对象转化成json字符串
public static String getObjectString(Object object){ String ObjectString = null; try { ObjectMapper ...
- (原创)JAVA多线程二线程池
一,线程池的介绍 线程池包括一下三种: 线程池名称 创建方法 特点 其他 固定大小线程池 ExecutorService threadpool = Executors.newFixedThreadPo ...
- Convert Sorted List to Binary Search Tree
Given a singly linked list where elements are sorted in ascending order, convert it to a height bala ...
- NPM 无法下载任何包的原因,解决方法
前几天发现NPM 无法现在任何的包 通过npm i testPackage -ddd 发现 是卡在了 npm verb addRemoteTarball 这行,google后发现 是有多个tmp地址, ...
- signalr推送消息
参考:Tutorial: Getting Started with SignalR 2 and MVC 5 环境:vs2013,webapi2,entity framework6.0 实现效果:当用户 ...
- 百度数据可视化图表套件echart实战
最近我一直在做数据可视化的前端工作,我用的最多的绘图工具是d3.d3有点像photoshop,功能很强大,例子也很多,但是学习成本也不低,做项目是需要较大人力投入的.3月底由在亚马逊工作的同学介绍下使 ...